🟢 RAG: From Theory to LangChain Implementation
Author: Leonie Monigatti
Reposted by: Xin
Recommendation: Easy to understand with code examples
Since realizing that proprietary data can be used to enhance large language models (LLMs), discussions have continued on how to best bridge the gap between general knowledge in large models and specific proprietary data. At the same time, there's been debate over whether fine-tuning or Retrieval-Augmented Generation (RAG) is more suited for this goal (spoiler: both are useful).
This article first focuses on the concept of RAG, introducing its theory, then demonstrates how to implement a simple RAG process using LangChain, OpenAI language models, and the Weaviate vector database.
What is Retrieval-Augmented Generation (RAG)
RAG is about supplementing large language models with additional external knowledge. Its purpose is to enable the model to generate more accurate and contextually relevant answers and reduce hallucinations.
Problem Background
Currently, the most advanced large language models are trained on vast amounts of data to store extensive general knowledge within the neural network weights (also called parameter memory). However, when we ask these models to generate information not included in their training data, such as real-time, proprietary, or domain-specific information, they may produce factually inaccurate responses (known as hallucinations), as shown in the image below:
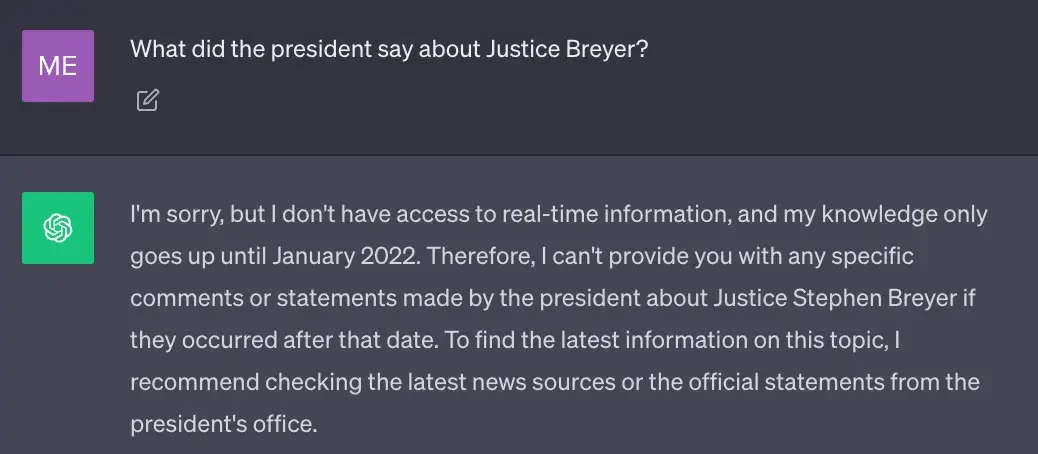
- Question: What did the president say to Justice Breyer?
- ChatGPT's Answer: The model's training data is up to January 2022, so it cannot accurately answer this question.
Therefore, to make the model's answers more accurate, contextually relevant, and to reduce errors, it's necessary to bridge the gap between the general knowledge stored in the model and additional context (e.g., real-time information).
Solution
Traditionally, we would fine-tune models to adapt to specific domains or proprietary information. However, this approach is complex, computationally intensive, expensive, and requires specialized technical knowledge. Hence, in 2020, Lewis et al. proposed a more flexible approach called Retrieval-Augmented Generation (RAG). In short, RAG combines a generative model with a retriever module, allowing the model to easily access additional information beyond the training data.
Simply put, RAG works like an open-book exam for large models. In an open-book exam, students can bring reference materials like textbooks or notes and look up answers during the test. The idea behind open-book exams is that they focus on students' reasoning abilities rather than the ability to memorize specific information.
Similarly, RAG separates factual knowledge from the model's reasoning capabilities, storing the knowledge externally so it can be easily accessed and updated:
- Parametric Knowledge: Learned during training, implicitly stored in the neural network's weights.
- Non-Parametric Knowledge: Knowledge stored externally, such as in a vector database.
Note: I didn't come up with this brilliant analogy. As far as I know, it was first proposed by someone named JJ during the Kaggle LLM Science Exam competition.
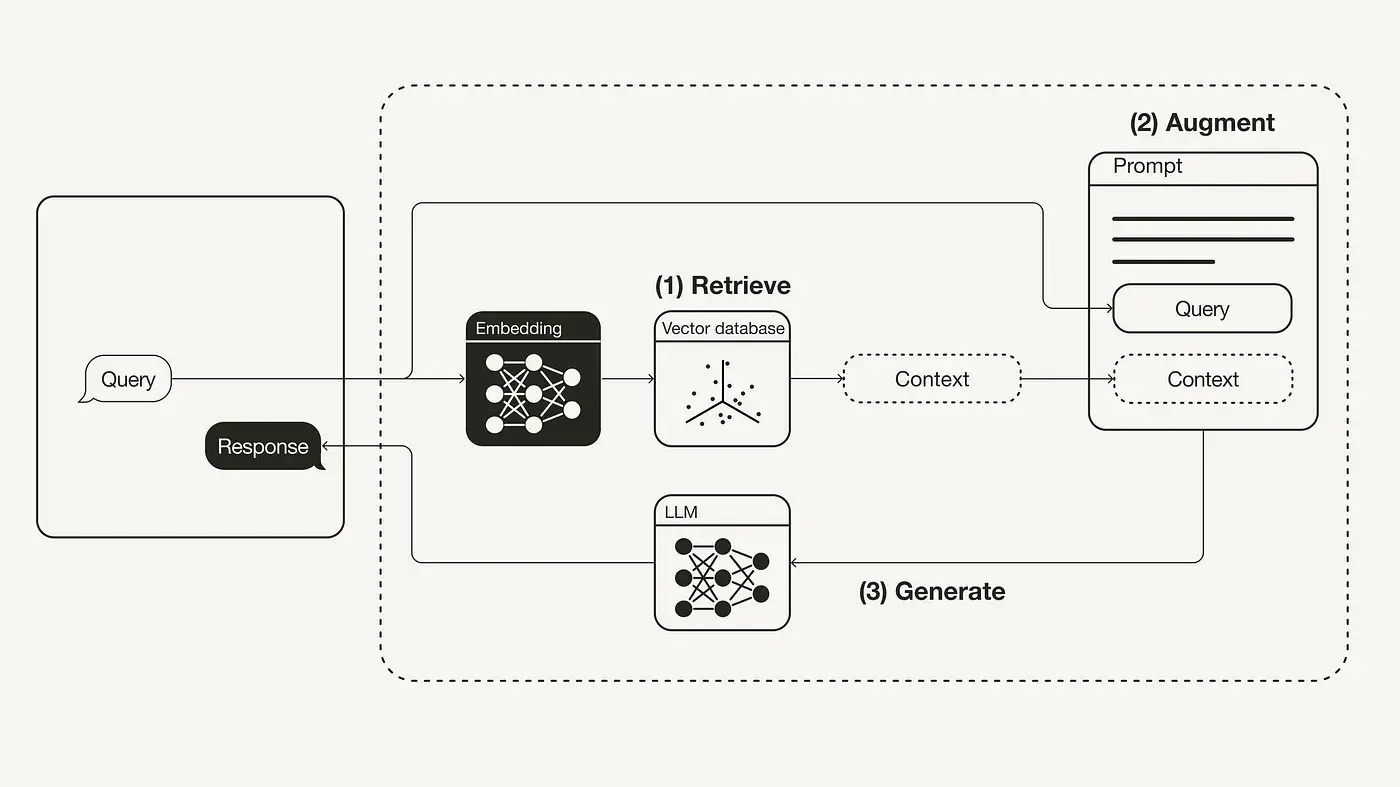
The diagram below shows the basic workflow of RAG:
- Retrieve: The user's query is used to retrieve relevant context from an external knowledge base. To do this, the query is embedded into the same vector space as the contexts in the vector database, then a similarity search is performed in this space to return the top k data objects most similar to the query.
- Augment: The user's query and the retrieved content are combined into a prompt template.
- Generate: Finally, the retrieval-augmented prompt is input into the LLM.
Implementing RAG with LangChain
This section uses Python to implement a RAG process: combining OpenAI's LLM, Weaviate vector database, and OpenAI's embedding model. LangChain is used for orchestration.
If you're unfamiliar with LangChain or Weaviate, you may want to read the following articles first:
- Getting Started with LangChain: A Beginner’s Guide to Building LLM-Powered Applications
- Getting Started with Weaviate: A Beginner’s Guide to Search with Vector Databases
Environment Setup
Ensure you have the following necessary Python packages installed:
langchainfor orchestrationopenaifor embedding and LLM callsweaviate-clientfor the vector database
#!pip install langchain openai weaviate-client
Additionally, define the related environment variable OPENAI_API_KEY in the root directory's .env file. You need an OpenAI account to get an OpenAI API key and then select "Create new key" under API keys.
OPENAI_API_KEY="<YOUR_OPENAI_API_KEY>
Next, run the following command to load the related environment variables.
import dotenv
dotenv.load_dotenv()
Data Preparation
You need to prepare a vector database to store all the additional information as an external knowledge source. This can be done through the following steps:
- Collect and load data
- Document chunking
- Embedding and storing
First, collect and load the data: We will use Biden's 2022 State of the Union address as additional background knowledge. The raw file is available on LangChain's GitHub. LangChain also provides many built-in document loaders (DocumentLoader). A document(Document)is a dictionary containing text and metadata. Here, we use the built-in TextLoader to load the text into the database.
import requests
from langchain.document_loaders import TextLoader
url = "https://raw.githubusercontent.com/langchain-ai/langchain/master/docs/docs/modules/state_of_the_union.txt"
res = requests.get(url)
with open("state_of_the_union.txt", "w") as f:
f.write(res.text)
loader = TextLoader('./state_of_the_union.txt')
documents = loader.load()
Next, document chunking: Because the original document is too long to be input directly into the LLM, it needs to be chunked into smaller pieces. LangChain provides many built-in text splitting tools. Here we use CharacterTextSplitter, setting chunk_size to about 500 and chunk_overlap to 50 to maintain text continuity between chunks.
from langchain.text_splitter import CharacterTextSplitter
text_splitter = CharacterTextSplitter(chunk_size=500, chunk_overlap=50)
chunks = text_splitter.split_documents(documents)
Next, document chunking: Because the original document is too long to be input directly into the LLM, it needs to be chunked into smaller pieces. LangChain provides many built-in text splitting tools. Here we use CharacterTextSplitter, setting chunk_size to about 500 and chunk_overlap to 50 to maintain text continuity between chunks.
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Weaviate
import weaviate
from weaviate.embedded import EmbeddedOptions
client = weaviate.Client(
embedded_options = EmbeddedOptions()
)
vectorstore = Weaviate.from_documents(
client = client,
documents = chunks,
embedding = OpenAIEmbeddings(),
by_text = False
)
RAG-1: Retrieval
With the vector database ready, we define it as the retriever component. The component's role is to fetch additional context based on the user's query and the semantic similarity between the query and the embedded chunks.
retriever = vectorstore.as_retriever()
RAG-2: Augmentation
To combine the prompt with additional context, you need a prompt template. Prompts can be easily customized from the prompt template, as shown below:
from langchain.prompts import ChatPromptTemplate
template = """你是一个用于问答任务的助手。
使用下面检索到的上下文片段来回答问题。
如果你不知道答案,只需说你不知道。
最多使用三个句子,并保持回答简洁。
问题:{question}
上下文:{context}
答案:
"""
prompt = ChatPromptTemplate.from_template(template)
print(prompt)
RAG-3: Generation
Finally, connect the retriever, prompt template, and LLM using a chain to build the RAG process. Once the RAG chain is defined, it can be called.
``python from langchain.chat_models import ChatOpenAI from langchain.schema.runnable import RunnablePassthrough from langchain.schema.output_parser import StrOutputParser
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
rag_chain = ( {"context": retriever, "question": RunnablePassthrough()} | prompt | llm | StrOutputParser() )
query = "What did the president say about Justice Breyer" rag_chain.invoke(query)
```python
"The president thanked Justice Breyer for his service and acknowledged his dedication to serving the country.
The president also mentioned that he nominated Judge Ketanji Brown Jackson as a successor to continue Justice Breyer's legacy of excellence."
Below is the example RAG workflow diagram:

Summary
This article introduced the concept of RAG, proposed in the 2020 paper "Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks" [1]. After covering some theory behind the concept, including motivations and solutions, it moved to implementation in Python. The article demonstrated using OpenAI LLM with Weaviate vector database and OpenAI embedding model to implement a RAG process. LangChain was used for orchestration.
References
[1] Lewis, P., et al. (2020). Retrieval-augmented generation for knowledge-intensive NLP tasks. Advances in Neural Information Processing Systems, 33, 9459–9474.
Image References
Unless otherwise stated, all images are created by the original author.