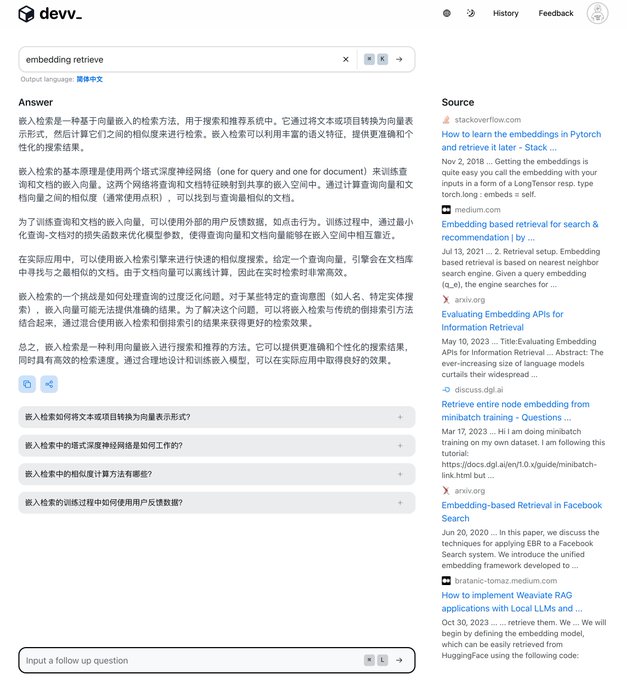
🟢 RAG Application: devv.ai
😀 Author: @Tisoga
Background
devv_ai is an AI search engine designed for developers. It focuses on perfecting the "programming + search" aspect to replace Google / StackOverflow / documentation, helping developers create value.
In November 2023, it surpassed 1 million searches and 100,000 users, backed by leading dollar funds.
The main developer of this RAG application has also publicly shared the tech stack and RAG background knowledge, making it highly valuable for learning.
What is RAG?
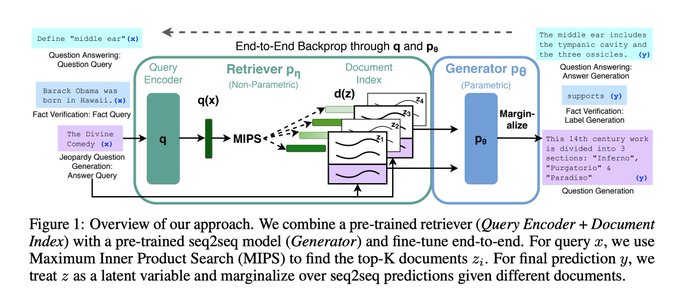
RAG stands for Retrieval Augmented Generation. It originated from a 2020 Facebook paper: Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks (Yes, this technology has been around since 2020).

The paper addresses a simple problem: how to make language models use external knowledge for generation.
Typically, pre-trained model knowledge is stored in parameters, leading to a lack of knowledge outside the training set (e.g., search data, industry knowledge).
The previous approach was to finetune the pre-trained model with new knowledge.
Problems Solved by RAG
This approach has several issues:
- Finetuning is required every time new knowledge is available.
- Training models is costly.
Thus, the paper proposed the RAG method: the pre-trained model can understand new knowledge, so we directly provide the new knowledge to the model via prompts.
RAG Components
A minimal RAG system consists of three parts:
- Language model
- External knowledge set required by the model (stored as vectors)
- External knowledge needed in the current context
Langchain and llama-index essentially build this RAG system (including agents built on RAG).
Understanding the essence means no additional abstraction is necessary. Build the system according to business needs. For example, to maintain high performance, we use a Go + Rust architecture to support high-concurrency RAG requests.
💡 Simplify the problem: optimize the three modules to optimize the RAG system.
Why RAG Became Popular This Year
1) Language Models
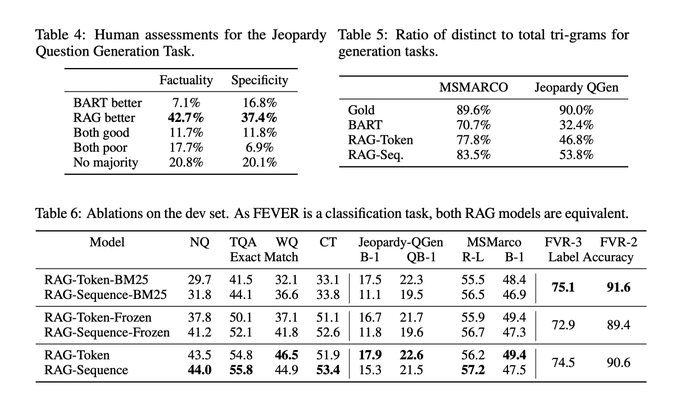
Why did the 2020 paper become popular this year? A major reason is that base models were previously inadequate.
Even with rich external knowledge, a poor base model couldn't reason with it.
Benchmarks from the paper show improvements, but not significantly.
1.1) GPT-3 Made RAG Usable for the First Time First-wave companies using RAG + GPT-3 gained high valuations & ARR (annual recurring revenue):
- Copy AI
- Jasper
Both built RAG products in the marketing field, becoming AI unicorns, though valuations have since dropped.
1.2) Since 2023, many open & closed-source base models can build RAG systems
Common methods:
- GPT-3.5/4 + RAG (closed-source)
- Llama 2 / Mistral + RAG (open-source)
2) External Knowledge Sets for the Model
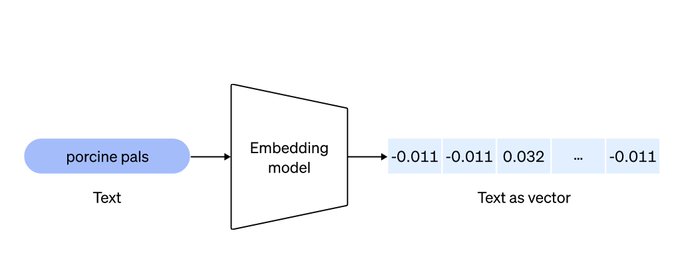
Now, everyone understands embedding models and embedding data retrieval.
Embedding converts data to vectors, finding the most similar vectors via cosine similarity.
knowledge -> chunks -> vector user query -> vector
2.1) This Module Has Two Parts:
- Embedding model
- Database storing embedding vectors
Most use OpenAI's embedding model; many options exist for the latter, including Pinecone, China's Zilliz, open-source Chroma, and pgvector built on relational databases.
2.2) These companies gained high funding and valuations during the AI hype.
However, from first principles, the purpose of module 2 is to store external knowledge and retrieve it when needed.
This step doesn't always require an embedding model; traditional search matching might work better in some cases (e.g., Elasticsearch).
2.3)
devv.ai uses embedding + traditional relation DB + Elasticsearch.
It optimizes each scenario, encoding knowledge extensively for faster & more accurate retrieval (early vs. late effort).
2.4) We built the entire knowledge index in Rust, including:
- GitHub code data
- Development documentation
- Search engine data
3) Better Retrieval of External Knowledge in the Current Context
Following the early effort rule, we processed raw knowledge data during encoding:
- Program analysis for code
- Logical-level chunking for documentation
- Extracting & optimizing page ranking for web information
3.1) This preprocessing ensures structured data retrieval, improving accuracy without much processing.
The a16z chart below expands each step with corresponding components, but the core essence remains.
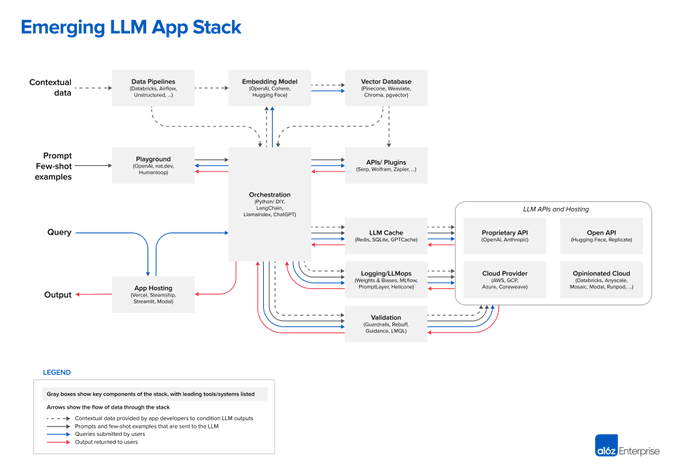
In 2022, the RAG-based search engine Perplexity had millions of monthly visits, and LangChain received billions in valuation.
Whether general or specific RAG, it's easy to do poorly but hard to achieve 90%. No best practices exist for each step; actual business scenarios require trial and error. There are many related papers, but not all methods are useful.
Today, we briefly introduced some high-level techniques used by devv.ai without diving into technical details, aiming to demystify technology for aspiring developers.
Next, we will share a weekly LLM-related tech post. While writing this thread, we extensively used devv.ai to find relevant information, which was very helpful.