🟡 Ten Strategies to Reduce Large Model Hallucinations - GPT Reliability +100
In this information explosion era, ChatGPT is like a leading ship, navigating us through the sea of knowledge. Its power and versatility make it a valuable assistant for improving our efficiency. However, you might have noticed that sometimes when using ChatGPT, it provides detailed explanations of incorrect or non-existent answers?
These captivating yet illusory answers are what we call "large model hallucinations." They are like mirages appearing out of nowhere, seemingly real but impossible to touch. In our pursuit of accurate information, these hallucinations can sometimes mislead us, blurring the line between fiction and reality.
🔍How do these hallucinations form? How can we identify and avoid these misleading instances?
In this article, I will guide you through understanding what large model hallucinations are, where they come from, and how we can avoid them.
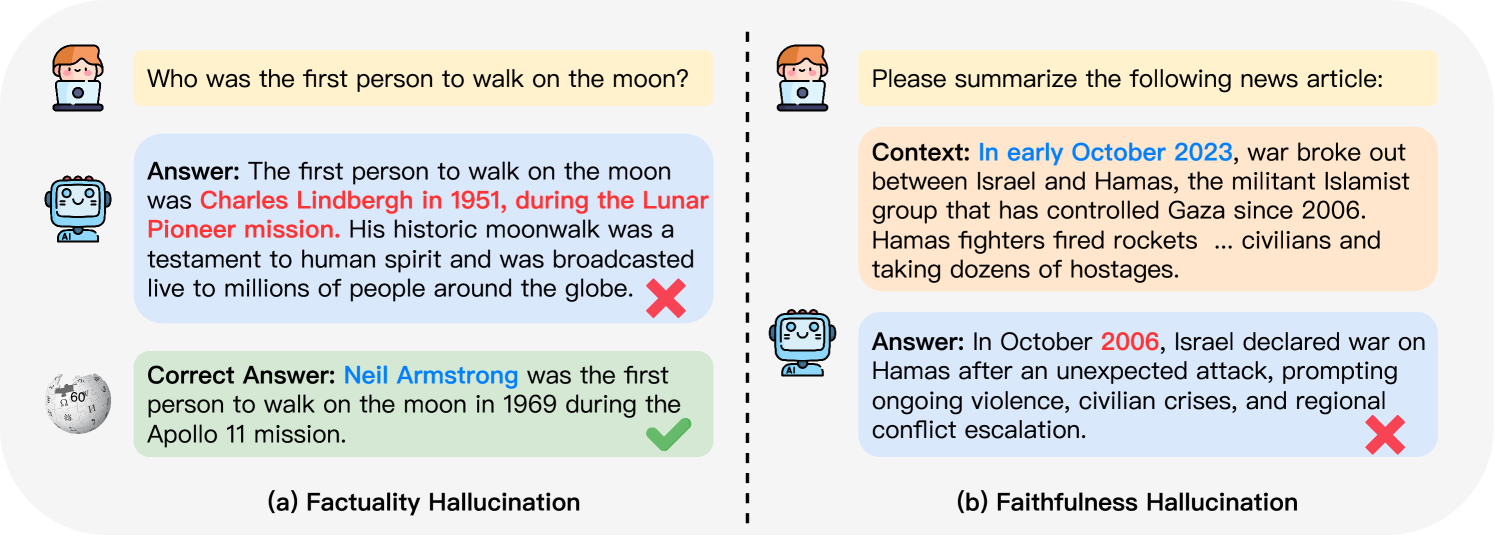
What Are Large Model Hallucinations?
"Large model hallucinations" occur when we use LLMs (like ChatGPT) to answer questions, and they sometimes create plausible but fictional or incorrect answers. Essentially, they are confidently incorrect statements. Large model hallucinations look like this:
Question: "What discovery led to the 2024 Nobel Prize in Physics?"
Answer (hallucination example): "The 2024 Nobel Prize in Physics was awarded to a group of scientists for their pioneering discoveries in quantum gravity waves. This discovery resolved long-standing inconsistencies between quantum mechanics and general relativity, providing new insights into the fundamental structure of the universe. This research was the first to experimentally demonstrate the behavior of gravitational waves on a quantum scale, thus opening up a new field of physics research."
Classification: In the survey "A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions," large model hallucinations are classified into factuality hallucinations and faithfulness hallucinations.
Tracing the Origins—Where Do Large Model Hallucinations Come From?
- The three main sources of model hallucinations: Data Sources, Training Process, and Inference
If we think of the training and inference process of a large model as a cooking process:

Data: The Quality of Ingredients Determines the Flavor
The final dish (output content) depends on the ingredients (data) used. However, sometimes these ingredients may be "flawed," such as incorrect information and biases (including repeated biases and social biases), similar to expired or spoiled ingredients that can lead to imperfect dishes.
Architecture Flaws: The Importance of Recipe Design
Next, consider the "recipe" (model architecture) of this dish. If the recipe is poorly designed, for example, focusing only on the previous step (token) and ignoring the overall ratio (contextual relationship), the final dish may not achieve the ideal taste. This is akin to architectural flaws like unidirectional modeling and insufficient self-attention modules.
Training Process: The Importance of Learning Method
In the "cooking" process (training phase), if the chef's learning method has issues, such as relying solely on previous cooking experiences (previous tokens) without adapting to new cooking environments (new contexts), this is exposure bias. Similarly, if it overfits to human preferences during fine-tuning, it might sacrifice the authenticity of the dish (information accuracy).
Inference Phase: The Accuracy of Taste Testing
Finally, when the chef conducts a "taste test" (inference), it may be influenced by inherent sampling randomness, akin to guessing the taste in a blind tasting, which might result in generating inaccurate content. Additionally, due to imperfect decoding representations, such as focusing too much on adjacent texts (insufficient contextual attention) and the softmax bottleneck (limited expressive power of the output probability distribution), its tasting judgment might not always be accurate.
Analyzing the sources of model hallucinations: To fundamentally solve the problem of large model hallucinations, prompt-based solutions are far from sufficient.
How to Solve Large Language Model Hallucination Problems?
Prompt Engineering:
Provide Reference Information: Ensure Information Accuracy
By providing the model with or referencing relevant documents and contextual information, ensure its responses are based on reliable data sources. For example, when posing a question, include links to relevant articles or data reports, requiring the model to generate answers based on this specific information.

Build Efficient Prompt Templates: Guide Content Generation
Use customized prompt templates, including clear instructions, user inputs, output requirements, and related examples, to guide the model in generating desired responses. For example, when designing a template, you can first clarify the problem background, then specify the type of answer needed, and finally provide a similar question's answer as an example.
Here is a prompt constructed based on the CREATE template I shared in the "Prompt" group:
You are an experienced translation expert proficient in translating text from English to Chinese.
Please translate the following English paragraph into Chinese.
[Insert a short English text here]
When translating, please pay attention to maintaining the tone and cultural background of the original text while ensuring the Chinese expression is smooth and natural.
Provide a fluent and accurate Chinese translation.
If the original text contains specific terms or cultural nuances, please briefly explain them next to the translation.
Apply Chain-of-Thought (CoT) and Customized Prompts: Enhance Reasoning Abilities
Use context-directed reasoning (CoT) methods and customized prompts to guide the model through detailed step-by-step reasoning and provide specific examples to help the model understand the expected output format. For example, require the model to display each step of its thought process before providing the final conclusion.

Task Decomposition and Recursive Linking: Simplify Complex Problems and Create Coherent Thought Chains
Break down complex problems into simple, modular steps, and use recursive linking to take the output of one subtask as the input for the next. This ensures the coherence and logic of the answers. For example, analyzing market trends and predicting future changes can be broken down into analyzing current market trends and predicting future changes based on current trends as two subtasks.
(The following part might be a bit advanced, those without a foundational understanding can skip to the large model thinking section)
5. Advanced Prompt Engineering Techniques
- Retrieval-Augmented Generation (RAG): Combine different stages of retrieval and generation processes, such as LLM-Augmenter, knowledge retrieval, D&Q framework, RARR, and the original RAG model, to enhance text accuracy and relevance.
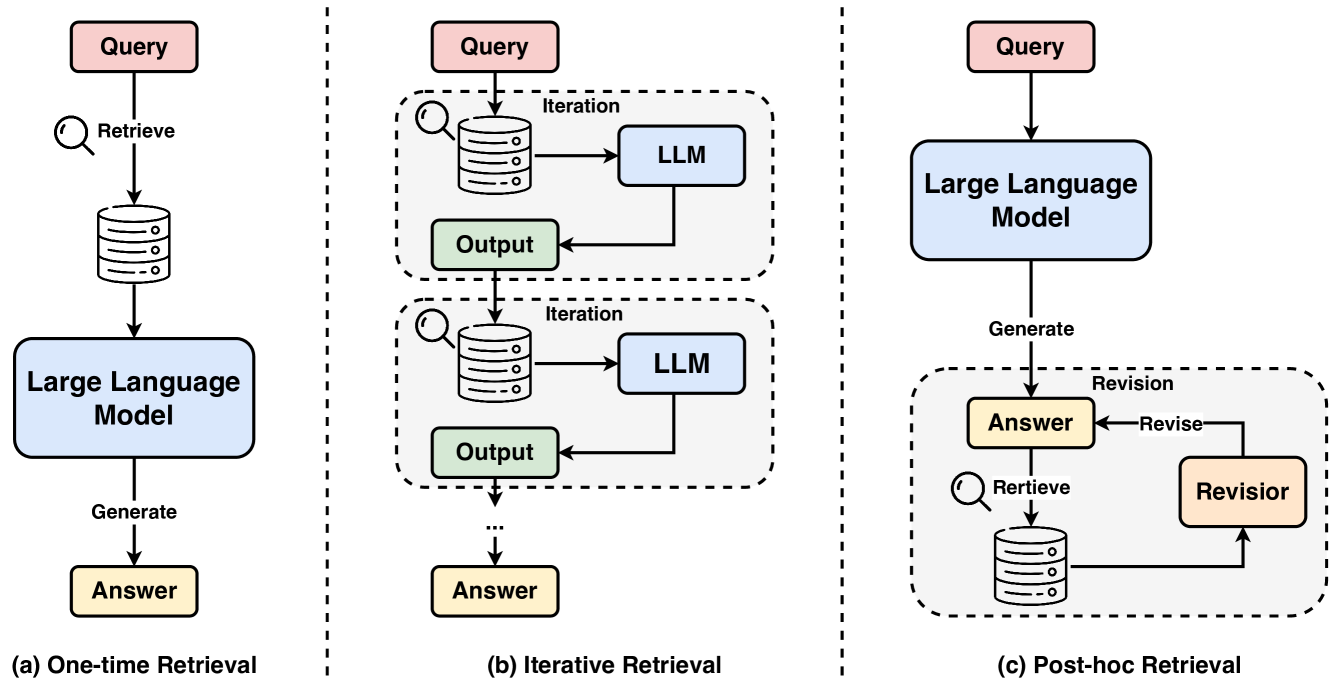
- Self-Improvement through Feedback and Reasoning: Including iterative improvement through user feedback (like "Prompting GPT-3 for Reliability"), discovering and mitigating self-contradictions (like ChatProtect), and interactive improvement through feedback loops (such as the self-reflection methodology).
Training-Related Hallucination Solutions
- Improved Pre-Training Strategies
Recent research shows that by improving pre-training strategies, ensuring the model has a richer contextual understanding and bias avoidance, hallucination issues can be effectively addressed. This includes allowing the model to better understand unstructured factual knowledge in documents, preventing fragmented understanding and lack of association.
- Enhance Model's Associative Understanding of Facts
For example, some research attaches a TOPIC PREFIX to each sentence of a document, converting them into independent facts, thus enhancing the model's associative understanding of facts. This method helps the model more accurately understand and associate information.
- Improve Human Preference Judgment and Activation Guidance
By improving the model's performance in mimicking human preference judgments and activation guidance techniques, alignment issues can be mitigated, enhancing the accuracy and relevance of model outputs.
Inference-Related Hallucination Solutions
- Fact-Enhanced Decoding and Post-Editing Decoding
Researchers explore advanced strategies, including fact-enhanced decoding and post-editing decoding, to reduce model output deviations from the original context.
- Faithfulness-Enhanced Decoding
This strategy emphasizes consistency with the provided context and enhances the coherence of the generated content. Faithfulness-enhanced decoding can be divided into two categories:
- Contextual Consistency: For example, Context-Aware Decoding (CAD), which adjusts the output distribution to reduce dependence on prior knowledge, promoting the model's focus on contextual information.
- Logical Consistency: Including the use of knowledge distillation frameworks to enhance inherent coherence in chain-of-thought prompts, ensuring logical consistency in model reasoning.
(For detailed knowledge, you can search for more information. The knowledge is extensive, so this part only provides an idea)
Thoughts on Large Model Hallucinations:
The issue of large model hallucinations has always troubled us using large models and LLM researchers. Everyone hopes to solve the hallucination problem through technical means, which is a challenging topic for LLMs. While we are still complaining about the hallucination problems of large models, OpenAI scientist Andrej Karpathy's view on large model hallucinations was eye-opening!

Andrej Karpathy stated:
"In a sense, hallucinations are precisely what LLMs do. They are dream machines. We guide their dreams through prompts. Prompts initiate dreams based on the LLM's fuzzy recollection of training documents. Most of the time, this leads to something useful. Only when the dreams venture into areas deemed factually incorrect do we label them as 'hallucinations.' It appears to be a bug, but it is merely what LLMs have always been doing."
He believes that large models are like dream machines, and hallucinations are their characteristics. It is only when the dreams venture into areas deemed factually incorrect that we label them as "hallucinations."
"Consider the other extreme, like a search engine. It accepts a prompt and returns a nearly verbatim 'training document' from its database. You could say this search engine has a 'creativity problem'—it never responds with anything new. An LLM is 100% dreaming and has a hallucination problem. A search engine is 0% dreaming and has a creativity problem. Nevertheless, I realize people actually mean they do not want LLM assistants (like ChatGPT) to hallucinate. An LLM assistant is a far more complex system than the LLM itself, even though the LLM is its core. There are many ways to reduce hallucinations in these systems—using retrieval-augmented generation (RAG) to anchor dreams more firmly in real data is one of the most common methods. Inconsistencies among multiple samples, reflection, validation chains. Decoding uncertainty from activations. Tool use. All these are active and very interesting research fields. In short, I know I am being verbose, but LLMs do not have a 'hallucination problem.' Hallucinations are not a bug but a key feature of LLMs. LLM assistants have a hallucination problem, and we should address it."
He also compares LLMs with search engines, which, although an extreme example, also illustrates that hallucinations are, to some extent, a source of creativity for LLMs. He believes ChatGPT does not represent LLMs but is an LLM assistant, and its hallucination problem should be addressed.
Conclusion
"Dreams" and AI, to some extent, resonate mysteriously and unknowingly. They contain infinite imagination and are shrouded in a veil of the unknown. Perhaps it is this mystery and unpredictability that bring unexpected wonders and beauty to the human world. Their existence seems to be the universe's way of showing us the splendor beyond imagination.
💡 If you have any questions about large model hallucinations, feel free to leave a comment below and let's discuss it together!