🟢 OpenAI Official Prompt Engineering Guide
😀 Preface: On the 15th, OpenAI updated the official Prompt Engineering Guide. The guide mentions six key principles:
1. Write clear instructions
2. Provide reference text
3. Split complex tasks into simpler subtasks
4. Give the model time to "think"
5. Use external tools
6. Test changes systematically
These principles can be combined to achieve greater effectiveness. Following this framework can optimize your prompts by 99%.
1. Write Clear Instructions
The model can't read minds and can't guess your thoughts.
- If the model's output is too long, you can ask it to respond briefly.
- If the model's output is too simple, you can request it to use a more professional level of writing.
- If you are not satisfied with the output format, you can directly show the format you expect.
It's best to make sure the model doesn't need to guess what you want, as this will give you the best chance of getting the desired result.
OpenAI provides 6 core tips
1. Add Details to the Question
Ensure your question includes all important details and background information.
🙅 Don't say: "Summarize the meeting notes."
🙆 Instead say: "Please summarize the meeting notes in one paragraph. Then, list all the speakers and their key points in a markdown list. Finally, if any, list the next steps or suggested actions by the speakers."
2. Ask the Model to Play a Specific Role
Explicitly telling the model to play a role can activate its "role-playing" ability. Here is an improved example:
I want you to play the role of a novelist. You will come up with creative and engaging stories that can captivate readers for a long time. You can choose any genre, such as fantasy, romance, historical fiction, etc., but the goal is to write works with outstanding plots, compelling characters, and unexpected climaxes. My first request is, "I want to write a science fiction novel set in the future."
3. Use Delimiters to Clearly Separate Different Parts of the Input
Using triple quotes, XML tags, chapter titles, etc., as delimiters can effectively distinguish and process different parts of the text. (In simple terms, it allows the model to clearly distinguish between your requirements and the text to be processed)
For example:
You will receive two articles on the same topic. First, summarize the main arguments of each article separately. Then, evaluate which article's arguments are more convincing and explain why.
"""
Article content
"""
Using blank lines and """ (commonly used in the coding field to divide different areas) is very effective and convenient.
4. Clearly Specify the Steps Required to Complete the Task
For complex tasks, it is best to break them down into a series of clear steps. Writing out the steps clearly can help the model follow instructions more effectively.
For example:
Please respond to the user's input by following these steps.
Step 1 - The user will provide you with text wrapped in triple quotes. Summarize this text in one sentence, prefixed with "Summary:".
Step 2 - Translate the summary from Step 1 into Spanish, prefixed with "Translation:".
"""Input text"""
5. Provide Examples as References
Few-shot technique: In some cases, providing concrete examples to illustrate may be more intuitive. For instance, you want the model to learn a specific way of responding.
For example:
whatpu is a furry little animal native to Tanzania.
Examples of sentences using the word whatpu: We saw these very cute whatpus on our trip to Africa.
"farduddle" means to jump up and down quickly.
Examples of sentences using this word: The children loved to farduddle in the playground.
6. Clearly Specify the Desired Output Length
Please summarize the text within the triple quotes in two paragraphs.
"""insert text here"""
2. Provide Reference Text
Language models may confidently fabricate false answers, especially when responding to deep topics or being asked for citations and URLs. Providing GPT with reference text can reduce the occurrence of false information.
1. Use Reference Text to Construct Answers
For example:
When you are provided with specific articles and need to answer questions, please base your answers on the content of these articles. If the answers are not included in these articles, just state "Unable to find the answer."
< Insert article content, separated by triple quotes between each article>
Question: < Insert question>
💡 Since all models are limited by the context window size, we need a method to dynamically query information related to the question asked. Embeddings can be used to achieve effective knowledge retrieval.
2. Instruct the Model to Answer Using Referenced Text
If the input information already contains relevant knowledge, you can directly ask the model to quote the provided documents when answering questions. Note that the quotes in the output can be verified by matching strings in the provided documents.
For example:
You will receive a document marked with triple quotes and a question. Your task is to answer the question using only the provided document and cite the parts of the document used to answer the question. If the document does not contain enough information to answer the question, simply write "Insufficient information." If the answer to the question is provided, it must be marked with a citation. When citing relevant paragraphs, use the following format ({"citation": …}).
"""< Insert document>"""
Question: < Insert question>
3. Split Complex Tasks into Simpler Subtasks
Breaking down a large and complex task into smaller, simpler subtasks is an effective method. This also applies to large models. This approach can help them handle complex tasks more effectively, resulting in superior performance.
1. Use Intent Classification to Determine the Most Relevant Instructions for User Queries
When you have many different tasks to handle, one method is to first classify these tasks into several categories. Then, for each category of tasks, you can decide which specific steps are needed to complete them. For example, you can first set a few main task types and then set some fixed steps for each type of task.
The benefit of this approach is that you don't have to handle everything at once but can take it step by step, reducing the chances of making mistakes. This approach not only reduces errors but also saves costs, as handling a large number of things usually costs more than handling them step by step.
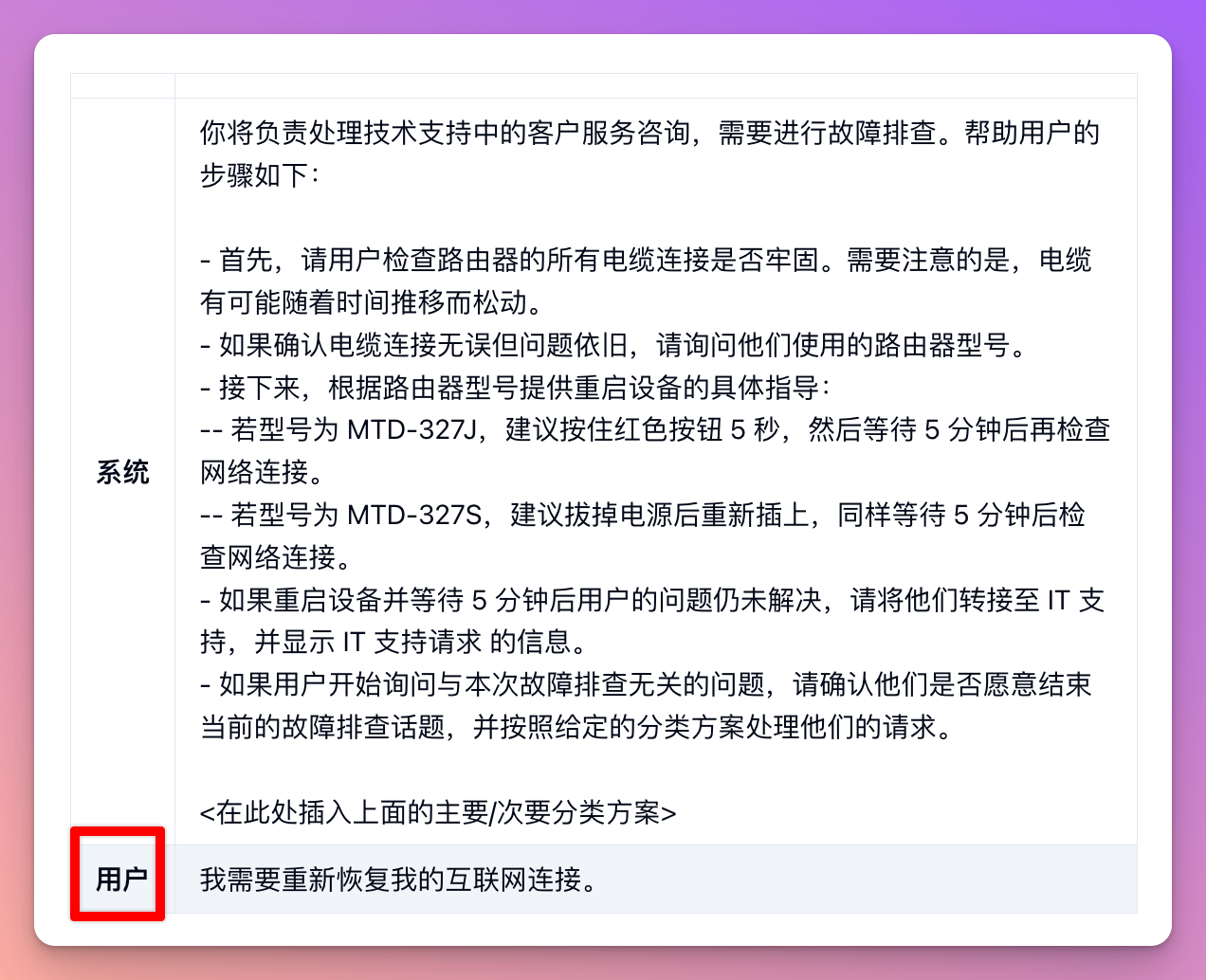
For example, for a customer service application, queries can be effectively classified into the following categories:

Now, based on Step 1, the model knows that "I'm disconnected, what should I do" falls under technical support troubleshooting, and we can continue with Step 2:
2. For Applications Requiring Long Conversations, Summarize or Filter Previous Conversations
Since the model's context length is fixed, conversations between the user and the assistant cannot continue indefinitely, especially when the entire conversation content is included in the context window.
One way to address this issue is to summarize the previous conversation. When the input content reaches a certain length, it can trigger a query to summarize part of the conversation. This summary can be part of the system message. Alternatively, the previous conversation can be summarized continuously in the background throughout the conversation.
💡 Although this leans towards a developer scenario, ordinary users can also use prompts to actively summarize the conversation history.
For example:
Your task is to summarize the information history of a conversation between an AI character and a human. The provided conversation comes from a fixed context window and may not be complete. Summarize what happened in the conversation from the AI's perspective (using the first person). The summary should be less than {WORD_LIMIT} words and must not exceed the word limit.
WORD_LIMIT is the desired output length.
Another method is to dynamically select the parts of the conversation most relevant to the current question. For details, see the strategy "Use Embedding-Based Search to Implement Efficient Knowledge Retrieval".
3. Summarize Long Documents in Segments and Recursively Construct a Complete Summary
Since the model's context length is fixed, it cannot summarize a text longer than the context length minus the length of the generated summary in one go.
For example, to summarize a long book, we can use a series of queries to summarize each chapter of the book separately. These partial summaries can be concatenated and further summarized to form a summary of the summaries. This process can be done recursively until the entire book is summarized. If information from earlier chapters is needed to understand later parts of the book, attaching a continuous summary of the previous content when summarizing the current part is a useful technique.
OpenAI previously conducted research on this method of summarizing books using a variant of GPT-3.

4. Give the Model "Time" to Think
1. Guide the Model to Find a Solution Before Hastily Concluding
Sometimes, we may get better results by explicitly guiding the model to reason based on fundamental principles before making a conclusion. Suppose we want the model to evaluate a student's answer to a math problem. The most intuitive way is to directly ask if the student's answer is correct.

However, the student's answer is actually incorrect! By guiding the model to produce its own answer first, it can successfully identify the issue.

2. Hide the Model's Reasoning Process Using Inner Monologue or Sequential Questioning
Previous strategies have shown that the model sometimes needs to reason through the problem deeply before answering a specific question. However, in some application environments, the reasoning process may not be suitable for sharing with users. For example, in educational applications, we might want to encourage students to think for themselves, but the model's reasoning process may inadvertently reveal the answer.
Inner monologue is an effective strategy to address this situation. The main concept of inner monologue is to guide the model to present parts of the output that need to be hidden from the user in a structured way, making it easy to parse. The output can then be parsed before presenting it to the user, showing only part of the parsed result.

Another way is to achieve this through a series of queries, where all but the last query's results are not shown to the user.
First, we can have the model solve the problem independently. Since this initial step does not require the student's answer, it can be omitted. This ensures that the model's answer is not influenced by the student's answer.
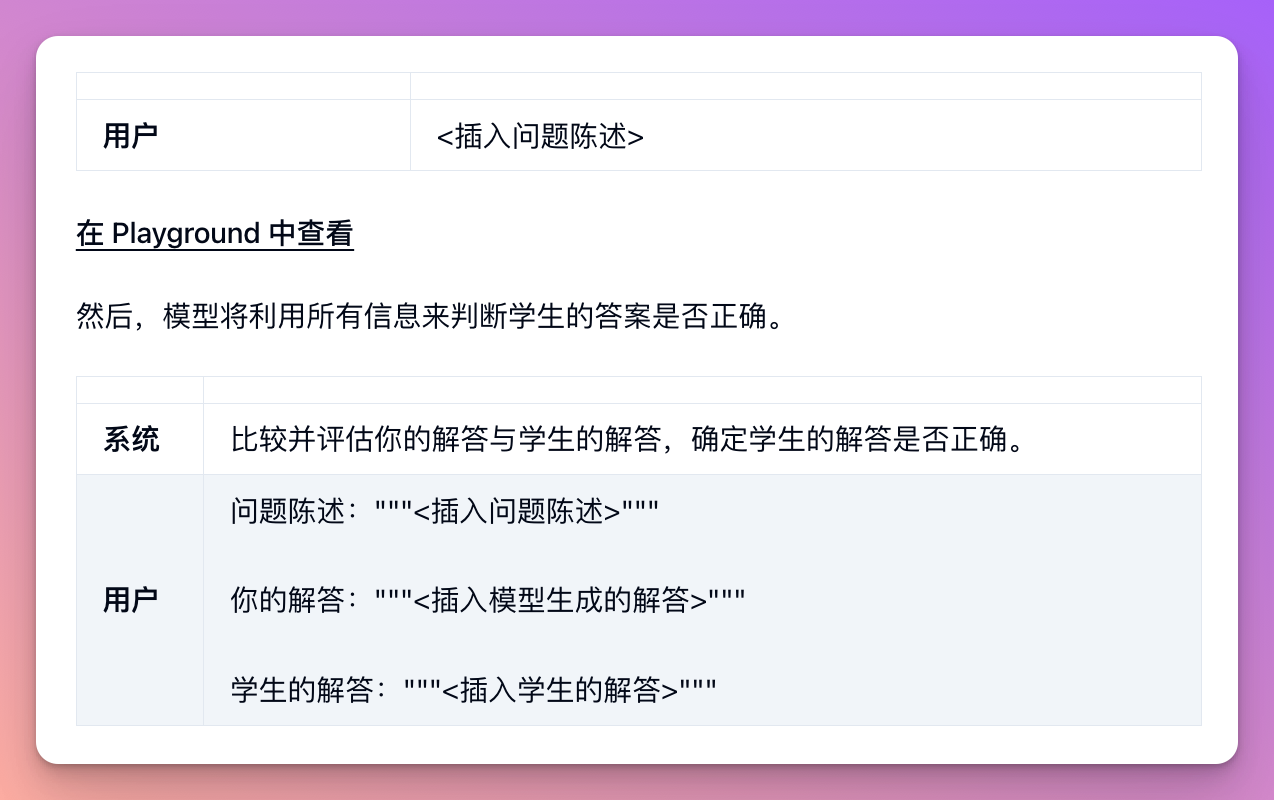
Finally, let the model respond as a helpful tutor based on its analysis.

3. Ask the Model If There Are Omissions
For example, when listing excerpts related to a specific question, the model needs to decide whether to continue with the next excerpt or stop after listing one. If the original text is long, the model may stop too early, missing some relevant excerpts. By asking follow-up queries to search for previously omitted excerpts, better results can usually be obtained.
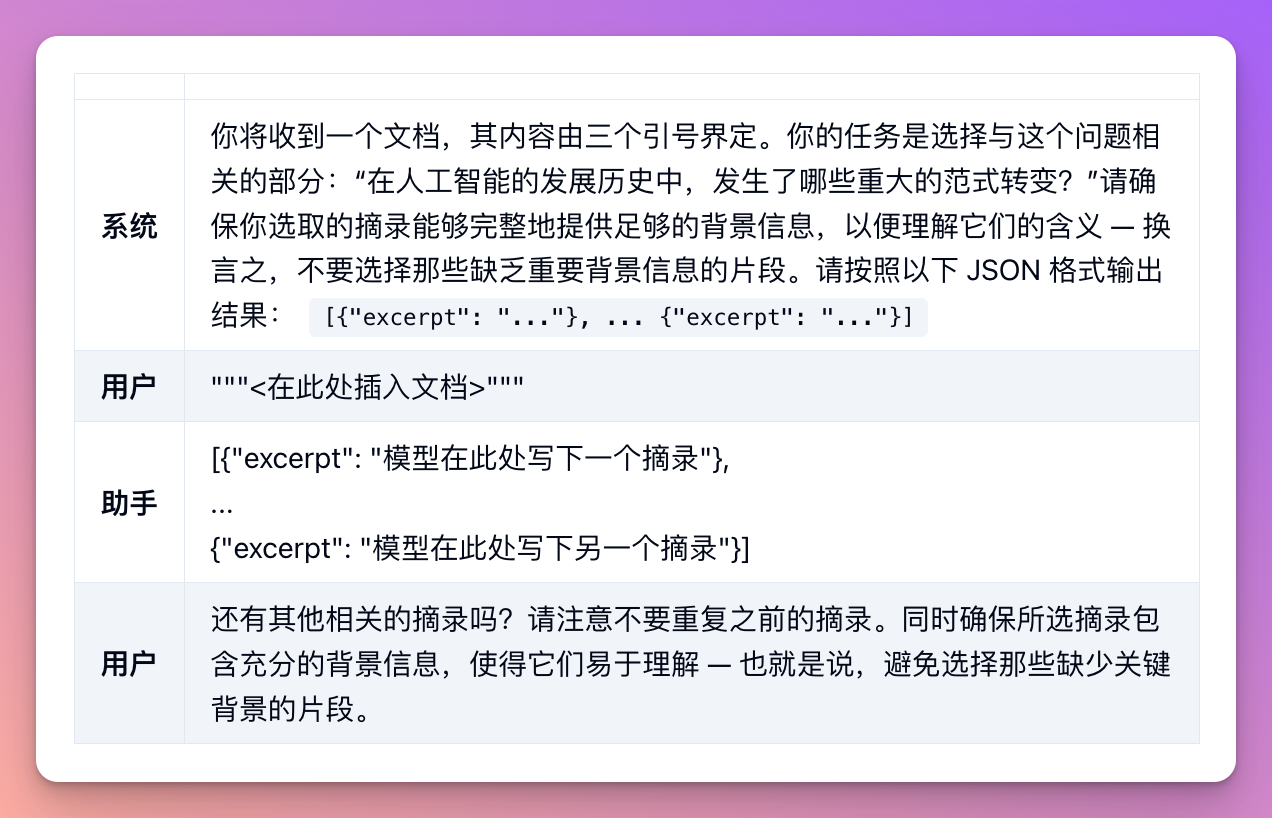
5. Use External Tools
In short, the model can generate more accurate and timely responses by utilizing external information provided as part of the input (the plugin system for GPT demonstrates the effectiveness of this strategy).
1. Use Embedding-Based Search for Efficient Knowledge Retrieval
If a user asks a question about a specific movie, adding high-quality information about the movie (e.g., actors, director) to the model input can be helpful. Embedding technology can be used for efficient knowledge retrieval, allowing relevant information to be dynamically added to the model input at runtime.
💡 Text embeddings are vectors that measure the relevance between text strings. Related or similar strings are closer in the embedding space than unrelated strings. This fact, combined with the existence of fast vector search algorithms, means that embeddings can be used for efficient knowledge retrieval. Specifically, a text corpus can be divided into multiple chunks, each chunk embedded and stored. Then, a specific query can be embedded and a vector search can be performed to find the most relevant embedded text chunks in the corpus (i.e., those closest in the embedding space).
In the OpenAI Cookbook, you can find some practical implementation examples.
2. Use Code Execution for Precise Calculation or External API Calls
We can't expect the language model to accurately perform arithmetic or complex calculations on its own. In cases where precise calculation is required, we can have the model write and run code instead of calculating by itself. Specifically, we can have the model put the code to be executed in a specific format, such as triple backticks. The output generated by the code can be extracted and executed. If necessary, the output of the code execution engine (e.g., Python interpreter) can be used as input for the next query.
For example:
You can write and execute code by wrapping it in triple backticks, such as code goes here. This method is suitable for situations where calculations are required.
Solve for all real roots of the following polynomial: 3x**5 - 5x4 - 3*x3 - 7*x - 10.
3. Enable the Model to Access Specific Functions
This is the recommended method for using OpenAI models to perform external function calls, mostly for developers.
In short, the Chat Completions API allows function descriptions to be passed in the request. This way, the model can generate function parameters that match these descriptions. These parameters are returned by the API in JSON format and can be used to perform function calls. The results of the function calls can be fed back into the model, forming a closed loop.

5. Evaluate Model Output Against a Standard Answer
Suppose we already know the correct answer to a question should involve a specific set of known facts. In this case, we can check the answer generated by the model to see if it includes the necessary facts.
💡 The main purpose is to help developers evaluate whether prompt changes have improved or degraded actual performance. Typically, the sample size is limited, making it difficult to determine if the change is a genuine improvement or just due to random factors.
The main idea is to "track the similarity between the model-generated answers and the standard answers, and check if there are any contradictions between the candidate answers and the standard answers." This part is recommended to read in the original text: