Comprehensive Evaluation of GPT-4o's Ten Capabilities in Chinese Context - Surpassing GPT-4
Since the early hours of today, the impact of the newly released omnipotent GPT-4o continues to spread. Besides the brief 27-minute content of the press conference itself, some easter eggs displayed on the official blog show significant improvements in various aspects of GPT-4o's capabilities, making me eager to conduct a practical evaluation. Coincidentally, OpenAI seemed to hear my thoughts and updated GPT-4o less than an hour after the press conference ended, so I immediately conducted a ten-capability evaluation.

Although the web version has been updated to GPT-4o, unfortunately, the iOS version has not yet equipped the "eyes" nor updated the voice interface, so real-time voice and visual capabilities are not within the scope of this evaluation. (Three continuous reminders! I will update the article as soon as the update is received🎉)
Back to the topic, this time the ten capabilities of GPT-4 turbo 🆚 GPT-4o are respectively semantic understanding and extraction, AI agent capabilities, contextual dialogue, generation and creation, knowledge and encyclopedia, coding, logic and reasoning, computation, role-playing, and safety.
Background Review
The dataset I referenced here is the comprehensive Chinese general model benchmark SuperCLUE. From May 2023 to April this year, they have continuously updated the Chinese leaderboard. SuperCLUE includes three sub-tasks: open domain multi-turn interaction (OPEN), objective question format three major capabilities (SuperCLUE-Opt), and the crowd-sourced anonymous battle format benchmark Langya List (SuperCLUE-LYB).
Their goal is to maintain consistency with the real user experience target, so they included the evaluation of open subjective questions. Through a multi-dimensional, multi-perspective, multi-level evaluation system and the form of dialogue, they realistically simulate the application scenarios of large models.
From the model list released in April, the GPT4 series models are still in the first echelon in terms of total score.
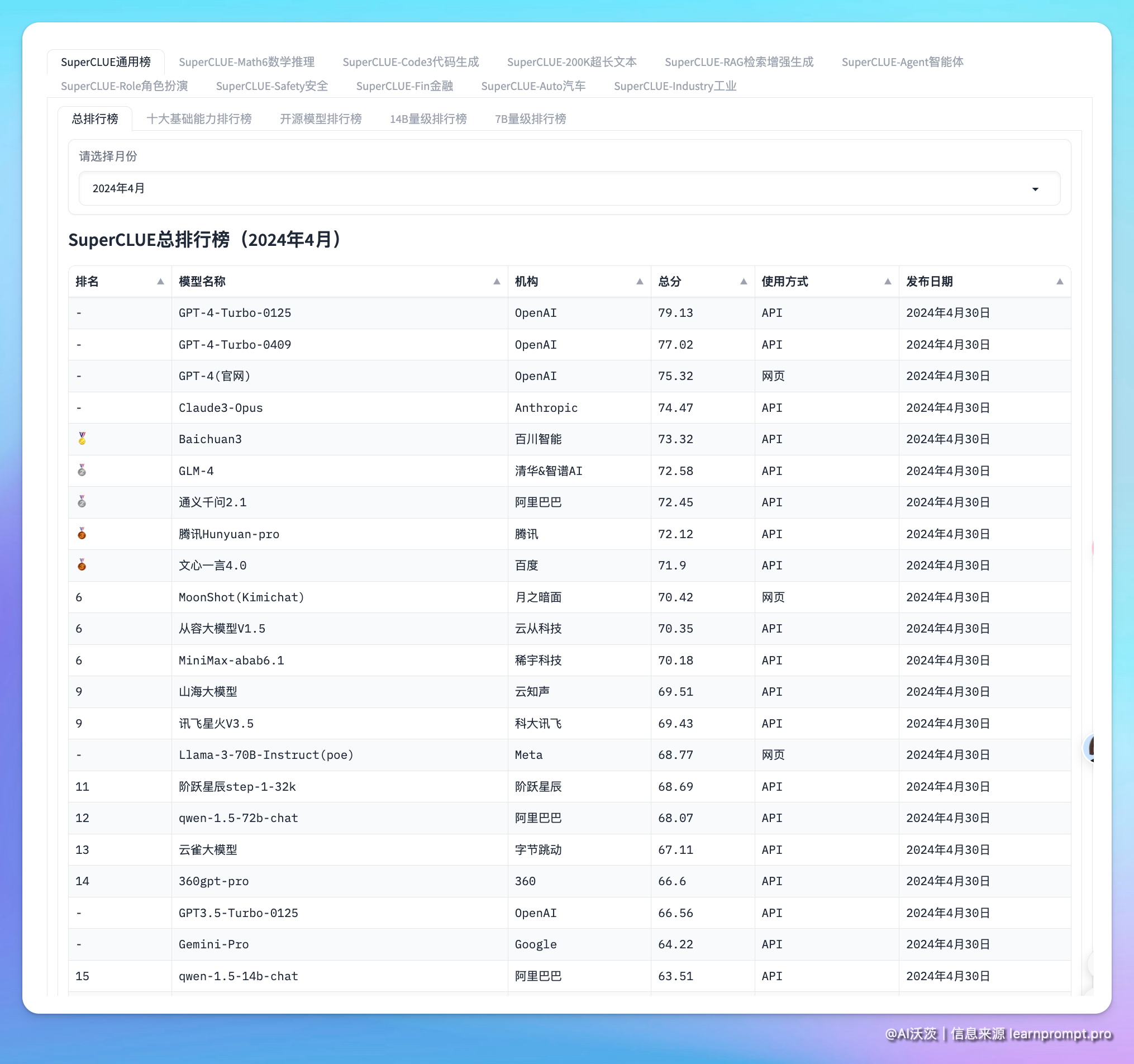
Thanks to the open-source community and thanks to SuperCLUE for providing such comprehensive performance comparisons: https://github.com/CLUEbenchmark/SuperCLUE/
Today I used 10 groups to compare GPT4 and GPT4o. If you have interesting cases, feel free to post them in the comments, and let's explore the potential of GPT-4o together.
In the comparative cases below, there are situations where the output of GPT-4o is much longer than GPT-4. To make it clear for everyone to read, I will display the actual test results based on the layout 🎉
Capability 1: Semantic Understanding and Extraction
A language capability that can understand and parse the meaning of input text information. The model needs to be able to recognize the meaning of phrases, sentences, and paragraphs, as well as extract key information and themes from larger text blocks.
GPT-4o
GPT-4
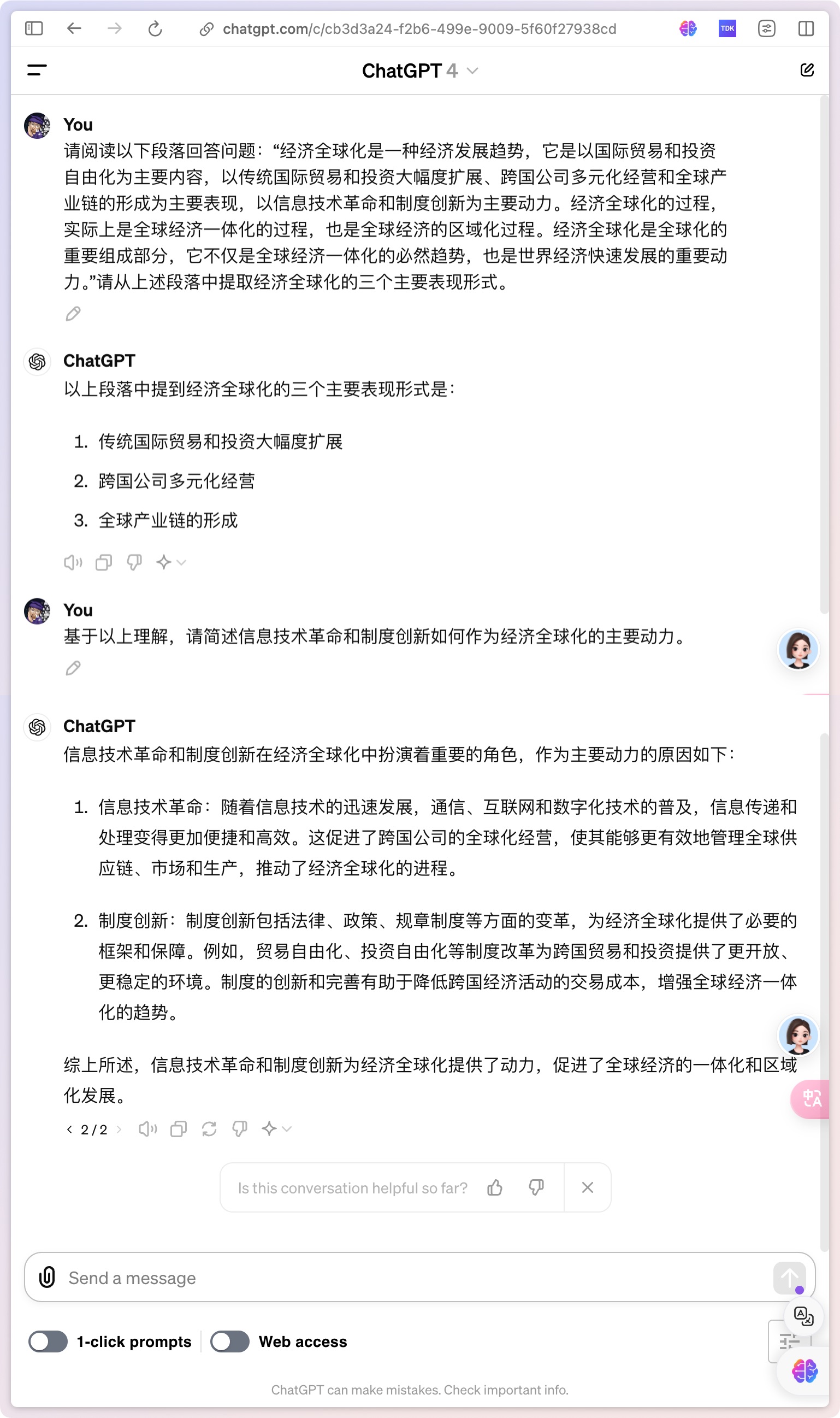
Personal Comment: I really like the secondary layout of GPT-4o, it's at a level that can be directly copied and used.
Capability 2: AI Agent Capabilities
AI agent is a current frontier research hotspot related to large language models, possessing the capabilities similar to human super assistants in sci-fi movies like Jarvis, and can autonomously complete tasks according to needs.
The focus is on evaluating the performance of AI agents in [tool usage] and [task planning].
GPT-4o
GPT-4

Personal Comment: GPT-4o's planning process can provide accurate schedules and price lists, which is impressive.
Capability 3: Contextual Dialogue
A language capability that requires understanding and remembering previous dialogue information to maintain coherence in responses. This involves understanding the overall flow and context of the conversation, or generating corresponding dialogue.
GPT-4o

GPT-4

Personal Comment: GPT-4o can provide dialogue rounds, and even with increased dialogue rounds, it can remember the history well. But overall, my experience is not much different from GPT-4.
Capability 4: Generation and Creation
A language capability that can create new text content, such as articles, copywriting, short stories, and poetry. This involves creatively using language while considering style, context, and target audience.

Personal Comment: GPT-4o understands Chinese better; it finally stops adding emotional words to enhance empathy like GPT-4, but uses our more familiar four-character idioms and arranged sentences to create copywriting.
Capability 5: Knowledge and Encyclopedia
A knowledge capability that can provide information like an encyclopedia. This involves understanding and answering questions on a wide range of topics, and providing accurate, detailed, and up-to-date information.
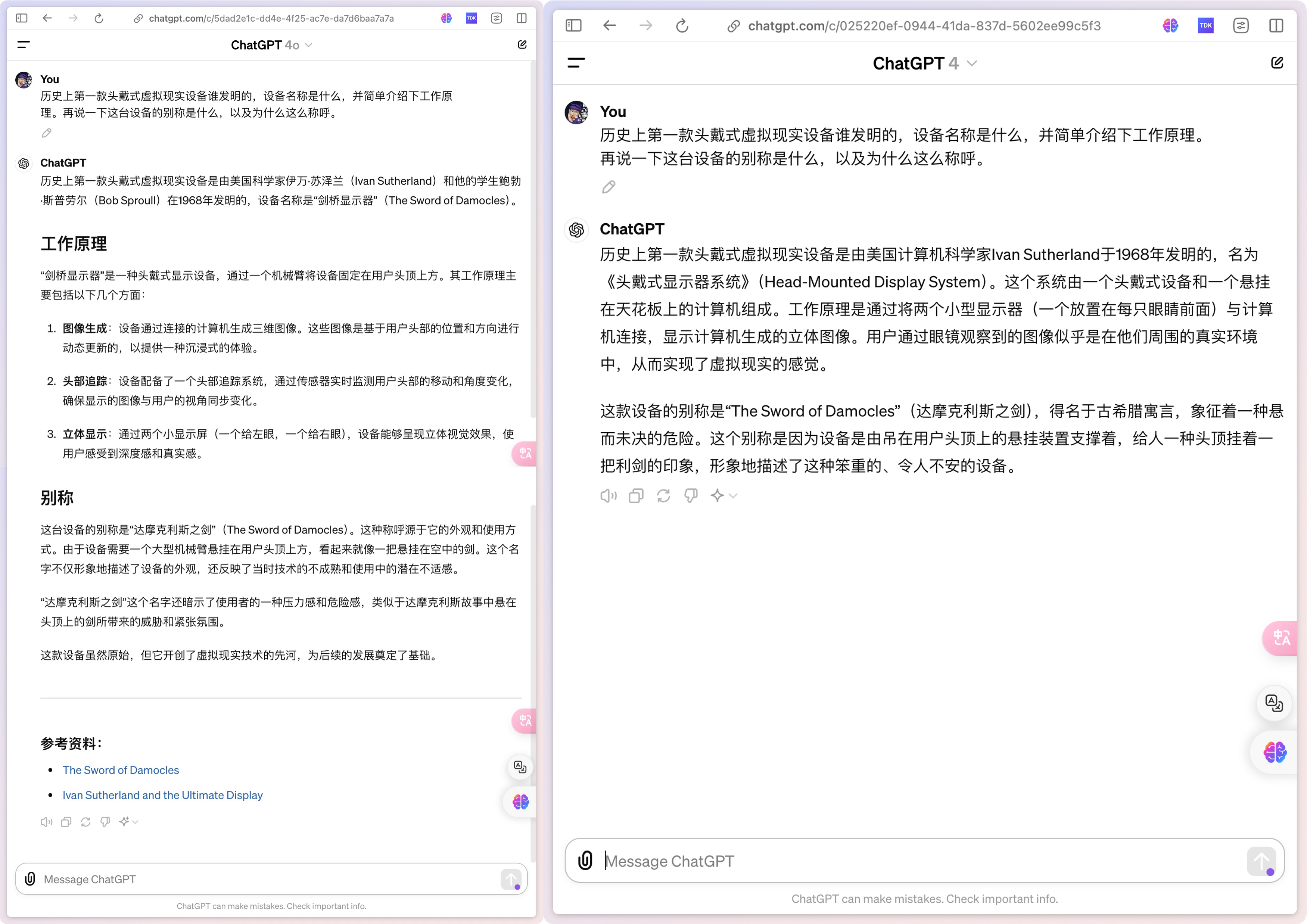
Personal Comment: GPT-4o outputs better; it segments the introduction of items and cites references.
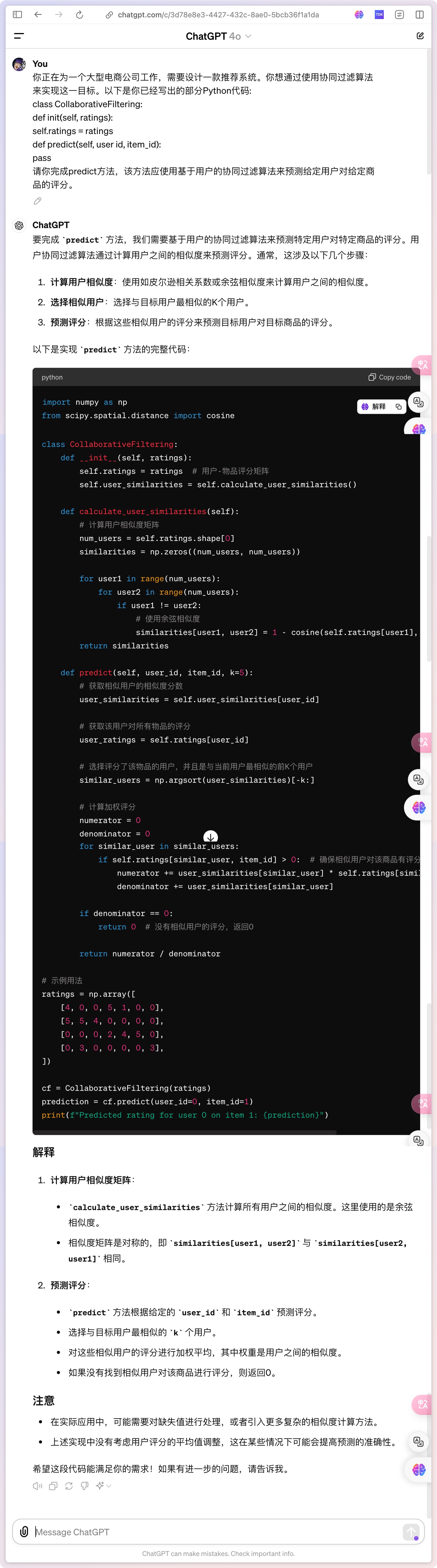
Capability 6: Coding
A professional capability that can understand and generate programming code. This involves understanding the syntax, structure, and conventions of various programming languages, as well as how to solve programming problems.
GPT-4o
GPT-4
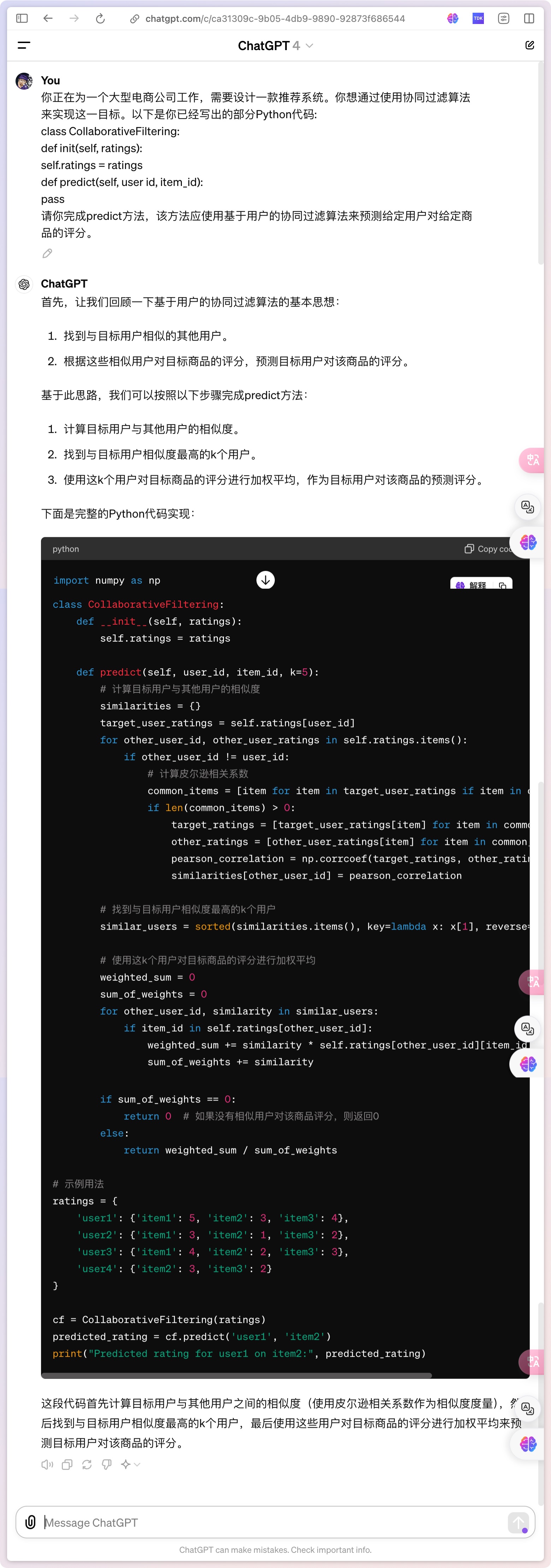
Personal Comment: The advantage of GPT-4o is that the analysis after generating the code includes corresponding variables, making it friendly to read.
Capability 7: Logic and Reasoning
A professional capability that can understand and apply logical principles for reasoning. This involves analyzing problems, identifying issues, and reasoning.

Personal Comment: GPT-4o's step-by-step reasoning process is very friendly; our group members generally understand GPT-4o's explanations first before understanding GPT-4's output.
Capability 8: Computation
A professional capability that allows it to perform mathematical operations such as addition, subtraction, multiplication, and division, and even more complex mathematical problems. This involves understanding the expression of mathematical problems and how to solve them step by step.

Personal Comment: Both sides have correct computation results, and GPT-4o's display effect is better without worrying about layout.
Capability 9: Role-Playing
A perceptual capability that allows it to play a role in a specific simulated environment or scenario. This involves understanding the behavior, speaking style of a specific role, and appropriate responses in specific situations.

Personal Comment: GPT-4o can directly provide the chat content I want, clearly superior.
Capability 10: Safety
A safety capability that prevents generating content that may cause distress or harm. This involves identifying and avoiding requests that may contain sensitive or inappropriate content, and adhering to user privacy and safety policies.

Personal Comment: This time GPT-4's output content also cited papers, making it more reliable than GPT-4o.
In Conclusion
When I tested the fifth capability, the Mac application of GPT-4o had already started pushing to beta users. This update speed is faster than ever before.
After testing the ten capabilities, my first feeling is that the surprise brought by GPT-4o is not just in real-time voice communication.
It significantly reduces the hard requirement of relying on complex prompts to control model output,
giving me a sense of relief,
this is the AI assistant Jarvis I was looking forward to.
It completes complex tasks in daily conversations,
because it is so user-friendly that you might even ignore its presence,
looking forward to the day when I can say
“hey, GPT!” “I'm here!” anytime, anywhere!