Frame-by-Frame Analysis: A Comprehensive Review of Google's "Counterattack" Against OpenAI
In the field of artificial intelligence, Google has always been a major competitor to OpenAI. After being outmaneuvered by OpenAI's unadorned business strategies, Google spent more than two hours seemingly unveiling everything they had been holding back over the past year 📅!
- Project Astra 🆚 GPT-4o,
- Veo: Text-to-Video Model 🆚 Sora
- AI++ Google Search 🆚 OpenAI's delayed search engine
- 2 million token context Gemini 1.5 Pro 🆚 GPT-4
- Multimodal Gemini App 🆚 New ChatGPT APP UI
In addition, new TPUs, new open-source models, and new Gemma 27B were introduced. Don't worry, a detailed and comprehensive breakdown is provided later.
Watching the OpenAI presentation, I felt that 26 minutes was far from enough. My frame-by-frame analysis of this Google event took a whole day 🥱. Google was well-prepared and very confident:
CEO Sundar Pichai set the tone right from the start: "We are in the Gemini era."

Controversy Right After Launch
The following comments are collected from various forums, so they all start with "someone said"
- Some believe that Google's new product launch is suffering from hype fatigue, with the new models not performing as expected and waitlists being an issue.
- Some criticize Google's product management, mentioning that Google's product launches often have short-lived hype and the products might eventually be shut down, expressing skepticism about Google's new products.
- Some think Google's product launch strategy is confusing, with unclear naming conventions and inadequacies compared to OpenAI's products.
- Some counter that OpenAI's product launches also have issues, with unreleased features causing concern.
- Some point out that Google's product launch strategy resembles the past few years' IO conferences, with waitlists and demos but products failing to meet expectations.
- Some doubt Google's product launch strategy and quality, believing Google has adopted Apple's marketing strategy, controlling the narrative on social media.
For me, the most important thing is to get my hands on these new products as soon as possible!
Available Today:
- Gemini 1.5 Flash, 1M context window
- PaliGemma, open-source vision model
Coming Soon:
- Imagen 3, text-to-image model
- Gemma 2, open-source LLM
- Gemini 1.5 Pro, 2M context window
Super Quick Version & One-Page Summary
Thanks to GuiZang for providing the first version
Google's I/O conference saw a comprehensive release, covering almost all types of generative models, and integrating AI at the product level 🧪
📌 Gmini 1.5 Pro supports 2 million tokens in context, with a series of quality improvements across key use cases such as translation, coding, and reasoning, but no test results were released.
📌 Gemini Flash is a smaller Gemini model optimized for narrower or high-frequency tasks, with the speed of model response being paramount. It is cheaper per million tokens than GPT-3.5.
📌 Composition of the Gemini model family:
- Ultra: "Largest model" (available only in Gemini Advanced)
- Pro: "Best overall performance model" (available in API preview)
- Flash: "Lightweight speed/efficiency model" (available in API preview)
- Nano: "On-device model" (will be built into Chrome 126)
📌 Gemini Gems are Google's GPTs, allowing customization of interactions with Gemini.
📌 Gemini Live: The ability to engage in deep, bidirectional conversations using voice, which powers the Project Astra real-time video understanding personal assistant chatbot.
📌 Gemma 2: To be released in June with a scale of 27B (previously 7B and 2B), offering performance close to Llama-3-70B at half the size.
📌 PaliGemma: Google's first open vision language model, inspired by PaLI-3.
📌 Veo: DeepMind's model challenging Sora, capable of generating 60-second 1080p high-definition, coherent videos from a short prompt, though some who have experienced it on HN say it doesn't quite cut it, with chessboards and pieces generated incorrectly.
📌 Imagen 3: Image model that understands naturally written prompts to generate higher-quality, more realistic images and excels in rendering text.
📌 Music AI Sandbox: Developed with artists like Wyclef Jean, Justin Tranter, and Marc Rebillet, it can create original instrumental tracks and perform voice transformation.
📌 Trillium: The latest TPUs, offering up to 4.7 times the performance improvement per chip over the previous generation TPU v5e.
🧪 Google Search Updates:
- AI Overviews: Rolling out to everyone in the US today, with options to simplify or elaborate explanations.
- Multi-Step Reasoning: Can break down complex questions into smaller parts and solve them in sequence.
- Video Queries: Soon to be used in searches.
- Advance Planning: Directly in search, allowing plans to be made for anything from dining to vacations.
- AI-Organized Search Results: Search will use generative AI to brainstorm and create an AI-organized results page.
🧪 Project Astra: Voice Assistant + Google Glass, a real AI assistant, always on hand.
🧪 Gemini App: The mobile version of the Gemini app will also support AI video conversations.
🧪 Workspace (Gmail): Integrated with Gemini Pro 1.5 to help summarize emails and draft replies.
🧪 Google Docs: Integrated with Gemini Pro 1.5 in the sidebar for document rewriting and summarizing.
🧪 Google Sheets: Request help with creating spreadsheets and data analysis using Gemini and Data Q&A, launching later this year.
🧪 Google Photos: Ask Photos can help search for pictures and videos using natural language, understanding and answering complex questions.
🧪 Circle to Search: Now a great learning assistant, allowing complex physics problems to be circled on a phone or tablet for step-by-step guidance.
Now for the detailed version, Gogogo!
New Version of Gemini
With Sundar Pichai announcing a context token limit of 2000K (2 million), Gemini surpasses all current large language models in context length and is available to personal users. In comparison, GPT-4 Turbo is 128K, and Claude 3 is 200K.

2 million tokens mean you can input up to 2 hours of video content, 22 hours of audio files, over 60,000 lines of code, or more than 1.4 million words, and the model will accurately understand and process this information.
Google's next goal is an unlimited context length, which I think we can start looking forward to.
Use Case 1 - Multimodal Interaction
Gemini can handle the information you upload, understand it, and transform it into a suitable format for interaction. Just think of it as a one-on-one small class!
- As a parent, if you want to quickly understand your child's situation at school, you can ask Gemini to identify all emails about school in Gmail and summarize the key points for you.
- If you missed a company meeting, you can upload an hour-long meeting recording, and Gemini will summarize the meeting points for you.
- To help students and teachers, Google designed an "audio overview" feature in NotebookLM, which integrates all the materials on the left as input and turns them into a personalized scientific discussion.

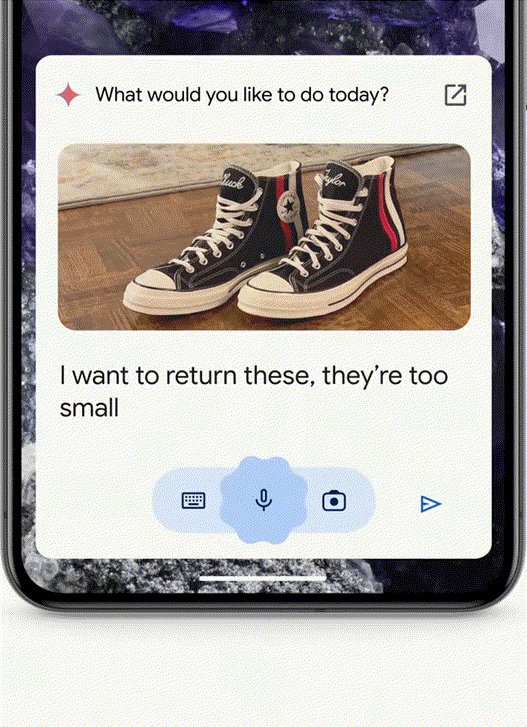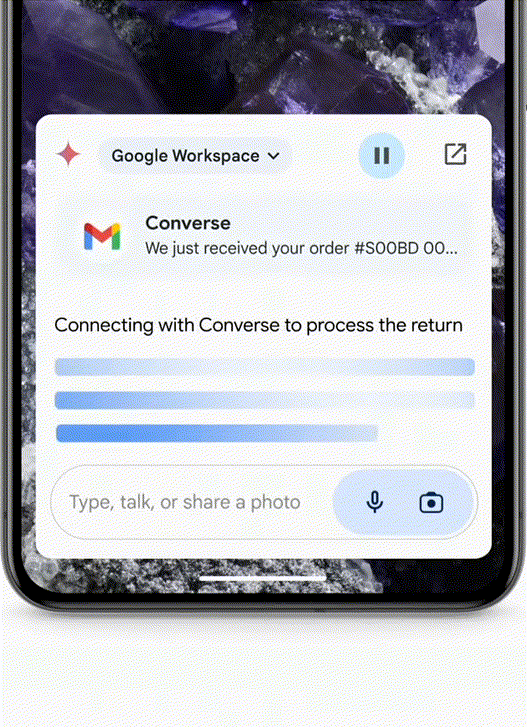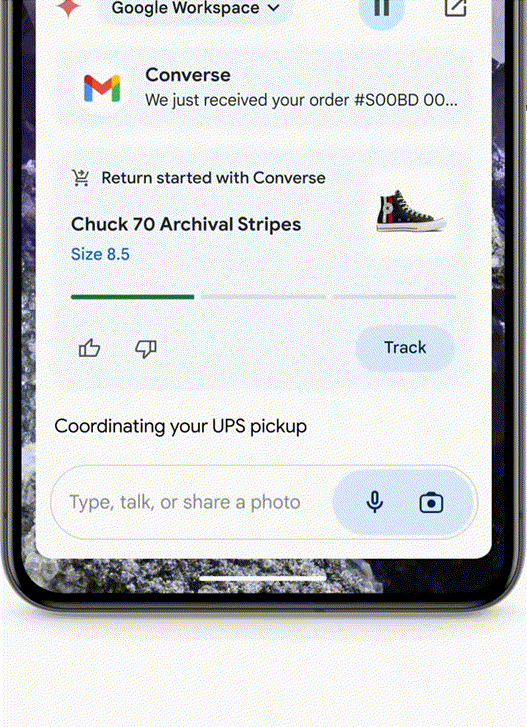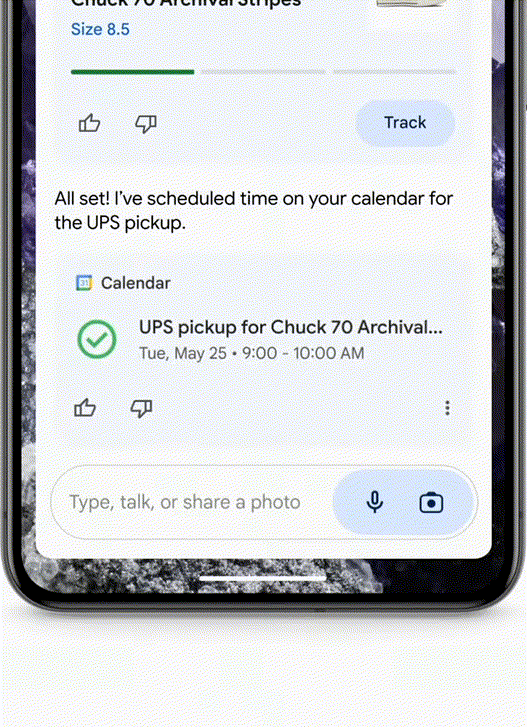
Use Case 2 - Agent Helps with Returns/Ordering Food/Auto "Meituan"
- If you bought a pair of shoes that don't fit and want to return them, just take a photo and send it to the Agent. It will find the order from your email and help you fill out the return form.
- For example, if you've just moved to a new city, the Agent can help you explore services you need in the city, like dry cleaners or dog walkers. From Google Maps' perspective, we might not always be able to use it 🤔

Simply put, Gemini can leverage its "multi-reasoning" capability to handle these tasks and provide you with the necessary information in one go!
AI++ Google Search
Earlier this year, OpenAI indirectly claimed through various media that it would release an AI search engine, which seemed like it was aiming to steal Google's cake.
Starting yesterday, Google Search will look completely different with the support of Gemini. An AI summary tailored for you will appear under the search box. In fact, this AI summary will be familiar to users who have registered for Gemini, as Google started using AI to respond to user queries last year.
Not only that, but Google also added four powerful peripherals to Google Search:
- Peripheral 1: The multi-step reasoning capability has also been integrated into the new Google search. It can break down a complex question into multiple parts, determine what needs to be addressed, and in what order to solve them, a very familiar Agent workflow 👍
For example, if you want to find the best yoga or Pilates studio in Boston, it will directly search for results and then organize the information and working hours for you.
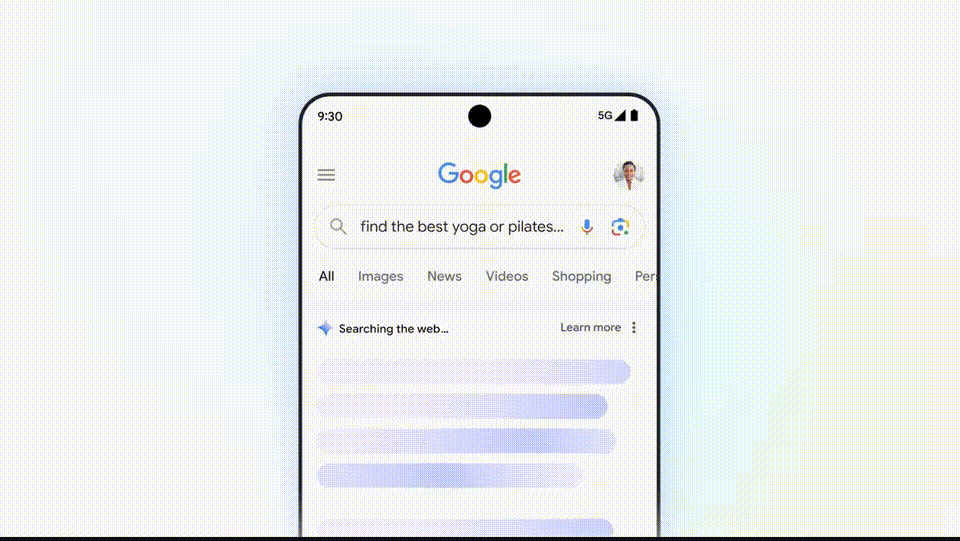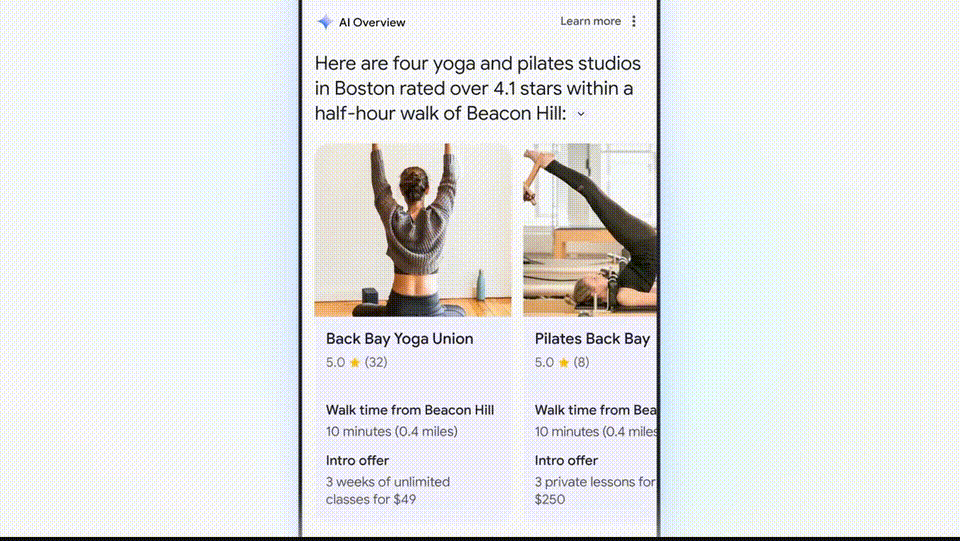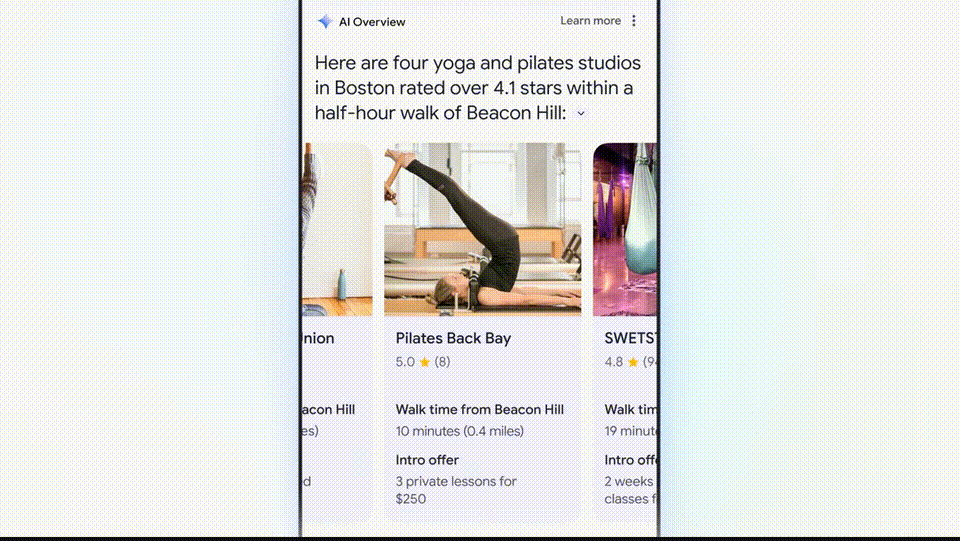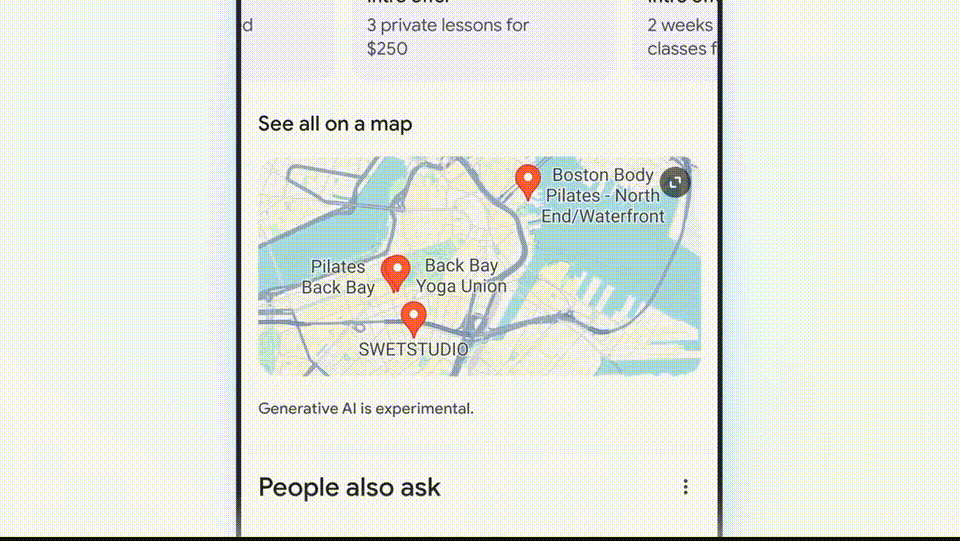
- Peripheral 2: In addition to providing answers, Google Search AI version will also help you plan in more detail. In the example below, you can ask Google for a three-day meal plan. These recipes are integrated from across the web, clear and comprehensive, perfect for planning trips.
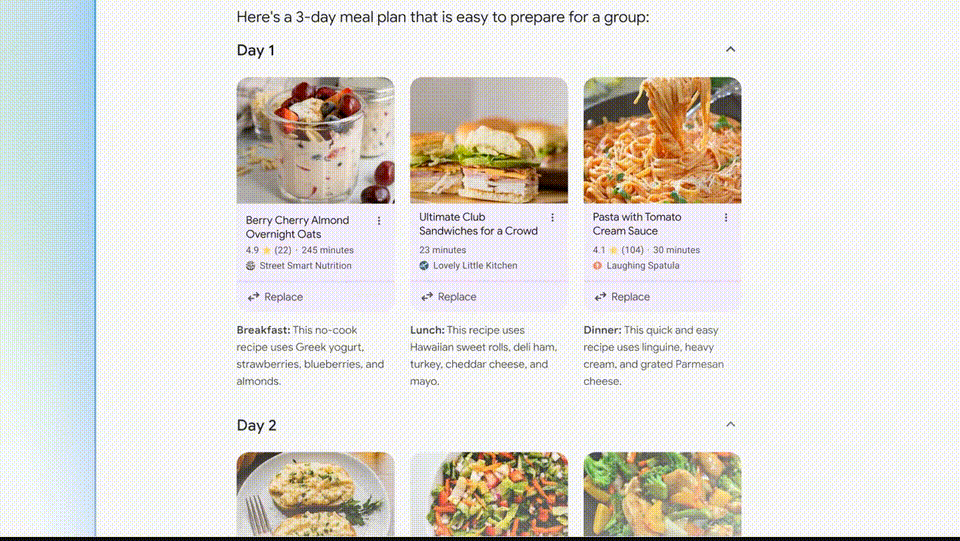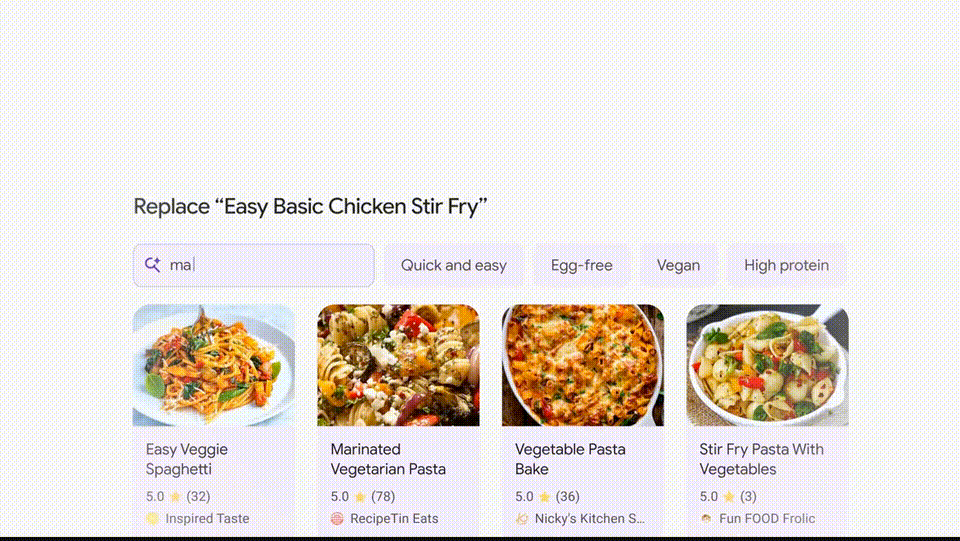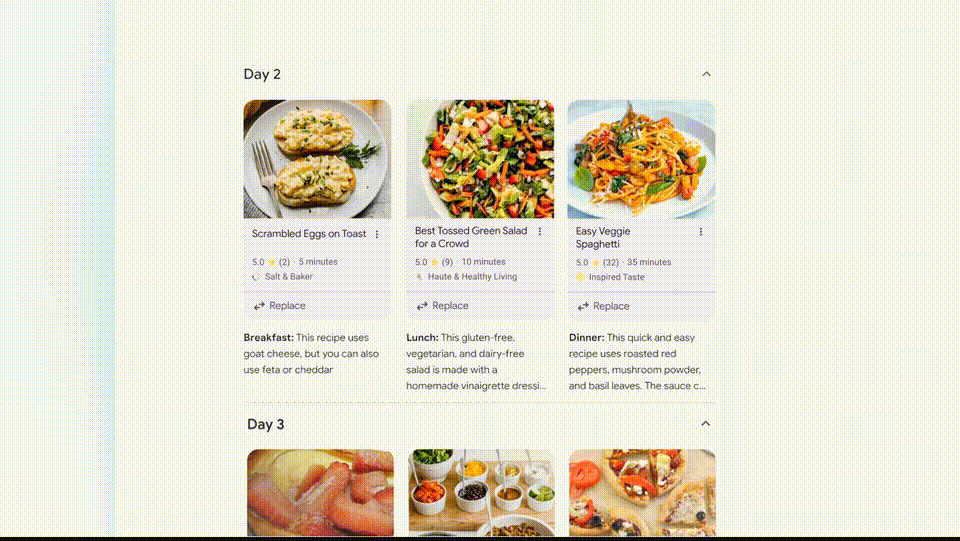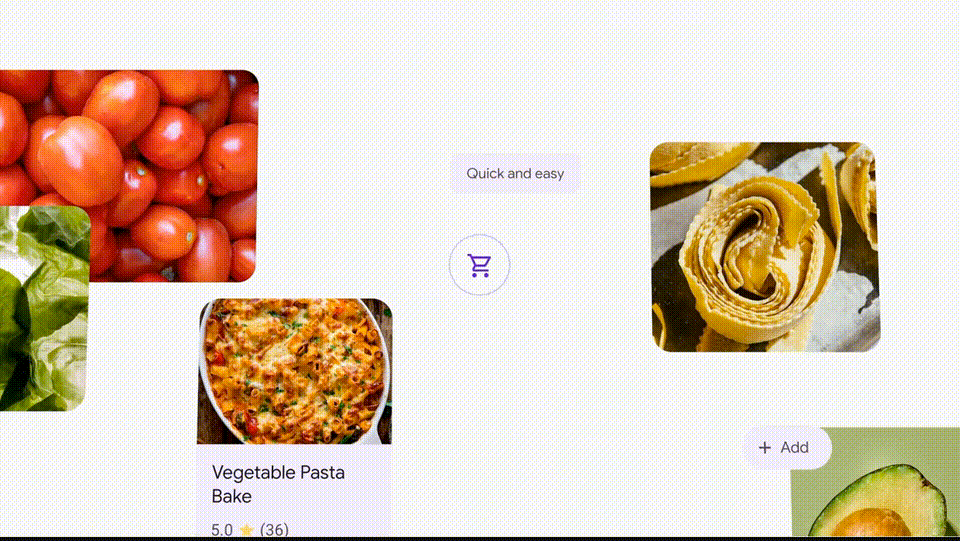
Peripheral 3: Multimodal Search
For example, how do you fix a record player without a manual?
In the past, we might spend a lot of time searching to determine the brand and model of the record player before figuring out the issue. But now, the situation is entirely different. Just shoot a video, upload it to Google, and describe the problem briefly to get a detailed answer.

Google says it will roll out this new search engine with AI Overviews to US users this week and to more countries in the coming months, aiming to cover over 1 billion users by the end of this year.
Competing with GPT-4o: Creating a Universal AI Agent Project Astra
We've witnessed the emergence of the new model GPT-4o, giving ChatGPT more powerful real-time conversation capabilities. Everyone is saying it feels like bringing the plot of "Her" into reality.
In response to OpenAI, Google DeepMind today unveiled for the first time their new project "universal AI agent"—Project Astra, abbreviated as Astra.
According to Google, it is a universal AI agent that can assist us in daily life, a real AI assistant.

The on-site demonstration was quite impressive. Many friends found it the most exciting part of the Google I/O conference.
Astra showcased its excellent fluent answering ability and for the first time demonstrated AI-equipped "Google AR prototype glasses."
Astra's demonstration was split into two parts, both done in one take, recorded in real-time.
Case 1
Tester: Tell me when you see something that makes a sound.
Astra: I see a speaker; it might make a sound.

Tester can use a red arrow to specify specific items in the APP: What is this part of the speaker called?
Astra: This is a tweeter, capable of producing high-frequency sounds.

Astra can also understand code, similar to GPT-4o, directly using the camera to take a picture of the computer screen and then asking: What does this part of the code do?
Astra: This code defines encryption and decryption functions. It seems to use AES CBC encryption to encode and decode data based on a key and initialization vector.

What's even more impressive is its memory capability, which can be called a video context window.
When you can't find your glasses, just ask Astra, Do you remember where you last saw my glasses?
Astra can "recall" the scene, Yes, I remember. Your glasses are on the table next to a red apple.

Case 2 Google AR Glasses
Google's prototype AR glasses + Astra feel like they surpass 🍎Vision Pro【They have different functions and are not directly comparable, I am only considering my personal experience as a wearable device】
The tester walks up to a whiteboard, looks at a diagram of a "server," and asks, What should I do to make this system faster?
Astra: Adding a cache between the server and database can improve speed.

Furthermore, seeing the picture below, what does it remind you of?
Schrödinger's cat! I almost didn't think of it.

Astra was demonstrated in a complex office environment, which I found more fun than the GPT-4o demonstration.
When it comes to general artificial intelligence, we expect it to understand and respond to the complex and ever-changing world like humans.
Specifically: Astra is an intelligent agent developed by the Google team based on Gemini, focusing on continuous encoding of video frames.
It can integrate video and audio multimodal inputs and cache them on the event timeline to achieve efficient recall and information processing by the AI agent.
Moreover, Google has enhanced the voice output effect with a wide range of tonal variations. Through these efforts, Astra can better understand the context, making interactions more natural, and improving the fluency and quality of conversations.
Imagen 3: Text-to-Image
The AI text-to-image generation model Imagen 3 is getting an upgrade!

Specifically,
- Imagen 3 generates richer and more detailed images than the previous version, with better lighting effects and fewer artifacts.
- The ability to understand prompts has greatly improved, capturing more details from longer prompts.
- Imagen 3 produces outstanding visual effects, excellent lighting, and composition. It can accurately render fine details like hand wrinkles and complex textures, and add tiny details like wildflowers or blue birds based on prompts.
- Imagen 3 offers multiple versions optimized for different tasks, compatible with generating quick sketches to high-resolution images.
- Significant improvements in text rendering capabilities, achieving text-to-image text pictures.
Let's look at some examples directly!
Prompt: Using a polarizing filter in the style of a DSLR camera. A photo of two hot air balloons floating above the unique rock formations of Cappadocia, Turkey. The colors and patterns on the balloons contrast sharply with the earthy tones of the landscape below. The photo captures the sense of adventure of enjoying this experience.

An amigurumi elephant walking on a grassland, professional photo, blurred background

The word "light" made of various colorful feathers on a black background

More examples: DeepMind's Imagen 3
Text-to-Video Veo 🆚 Sora - 1080p Over 60 Seconds
Google's latest video generation model Veo seems to be a long-prepared challenge to OpenAI's Sora!
Veo is built on DeepMind's groundbreaking achievements over the past year, including GQN, Phenaki, Walt, VideoPoet, Lumiere, and more. Google has combined the best architectures and technologies from these achievements to improve consistency, quality, and resolution.
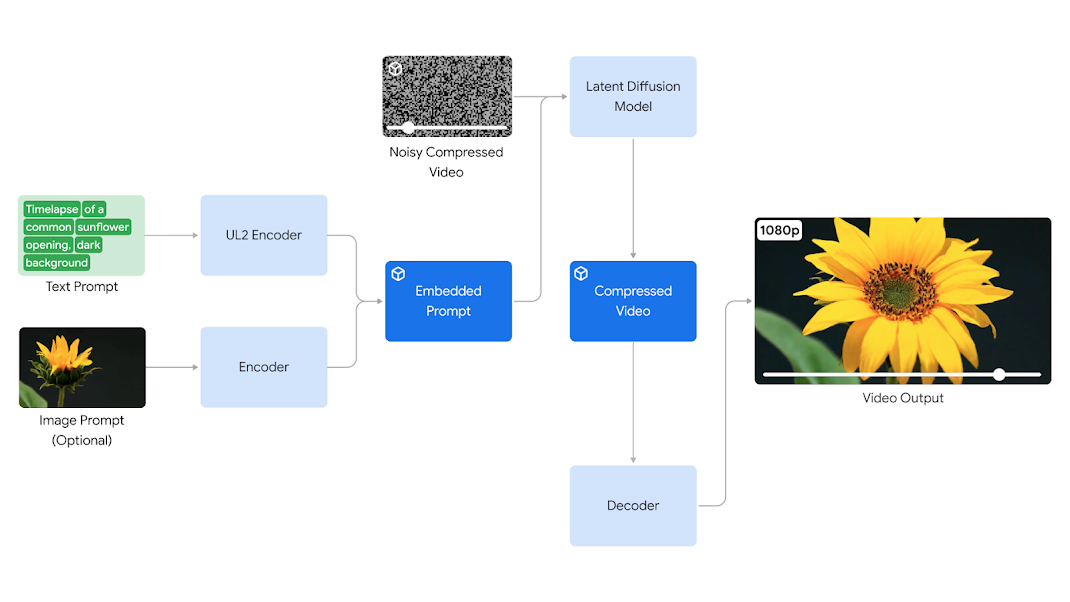
The final result is that Veo delivers 1080p high-quality videos, with user prompts that can be text, images, videos, and more, capturing all the details about visual effects and image styles.
In Google's own words,
It accurately captures the nuances and tone of the prompts and provides an unprecedented level of creative control—understanding prompts for various film effects, such as time-lapse or aerial shots of landscapes.

Veo also supports video editing, such as adding a kayak to a shoreline scene in an aerial shot. Veo can take input videos and editing instructions, apply those commands, and generate entirely new edited videos.

Additionally, Veo excels in maintaining consistency between video frames. A common challenge in today's AI video generation is that characters, objects, or entire scenes may flicker, jump, or deform unexpectedly between frames, affecting the viewing experience. However, Veo seems to handle these issues well.
More examples: DeepMind's Veo
Music Generation Music AI Sandbox
In the AI music field, Google has partnered with YouTube to create Music AI Sandbox. Isn't this a direct challenge to Suno, Udio?
Music AI Sandbox can take user-input melodies and quickly realize their creativity through style transfer features.
Some well-known musicians like Wyclef Jean, Justin Tranter, and Marc Rebillet are the first to release new demos using Music AI Sandbox, and each demo can now be heard on their YouTube channels.
Unfortunately, not much information was provided about Music AI Sandbox this time; we'll have to wait for more updates.
Gemini App
Google has launched the native multimodal Gemini application, capable of handling text, audio, and video content simultaneously. This application is part of Google's long-term effort to create a personal AI assistant.
To make interaction with Gemini more natural, Google also released Gemini Live.
In the Gemini app, you can have video conversations with AI, with a delay of about 1-2 seconds, longer than GPT-4o (4o is about 0.3 seconds), and with noticeably weaker voice modulation than 4o.
For example, if you're preparing for an interview, just enter Live and let Gemini help you prepare.
Gemini can rehearse the interview with you, suggest which skills to highlight when talking to potential employers, and provide advice. You can even control your speaking pace or interrupt Gemini's responses, just like talking to a real person.
Google says they will release a camera mode this year, allowing users to interact with Gemini through their surroundings.
Google's Version of GPTs
Meanwhile, Google has also introduced Gemini Experts—Gems, customized according to individual needs, essentially Google's version of GPTs.
You can make Gemini your fitness coach, kitchen assistant, programming partner, creative writing guide, or any role you can think of. The Gems feature is similar to OpenAI's GPT Store, making it Google's version of GPTs.

Google also demonstrated how to build custom AI assistants. You can set up a gem by telling Gemini what to do and how to respond. For example, you can tell it to be your running coach, provide you with daily running plans, and maintain an optimistic and motivational tone. Then, Gemini will create a gem based on your description.

New Feature Ask Photos
With the support of Gemini, Google is also launching a new feature, Ask Photos. The convenience of this feature lies in the ability to find specific photos without having to search through a large number of images on your phone.
For example, if you forget your license plate number while paying for parking, you can directly ask Ask Photos, and it will show your car's license plate photo, saving you the hassle of searching.

You can also ask about the people or scenes in the photos. For example, you can ask when your daughter started learning to swim and how her swimming skills have progressed. Gemini will recognize different scenes in the photos and compile all the relevant information for you.

But my concern is, can this feature only be used in Google Photos?
Gemini 1.5 Flash
Indeed, Google has also released a new lightweight model! Gemini 1.5 Flash.
This was driven by feedback from some Gemini 1.5 Pro users, needing lower latency and service costs for certain programs.
Although small, it is powerful. Gemini 1.5 Flash also has multimodal capabilities, a 1M tokens long context, and costs only a twentieth of the Pro version per million tokens, priced at only $0.002 per thousand tokens in RMB.
Starting today, Gemini 1.5 Flash is available in Google AI Studio and Vertex AI, and developers can register to apply for a 2 million token beta version. Additionally, to facilitate developers, Google has optimized the Gemini API with three new features—video frame extraction, parallel function calls, and context caching.
Gemini 1.5 Flash
Detailed pricing information:
Standard Price:
- Input: $0.7 / 1M tokens
- Output: $1.05 / 1M tokens
Discount Price (context less than 128k):
- Input: $0.35 / 1M tokens
- Output: $0.53 / 1M tokens
In comparison, GPT-3.5 Turbo (16k context) is priced at:
- Input: $0.5 / 1M tokens
- Output: $0.15 / 1M tokens
Benchmark results show that Gemini 1.5 Flash performs very similarly to Gemini 1.5 Pro.
"Easter Egg" Google also announced that its Chrome 126 browser will introduce the Gemini Nano model, capable of performing text generation functions locally, such as generating product reviews, social media posts, and other summaries, optimized for Chrome, significantly improving loading speed.
Sixth-Generation TPU Trillium
The latest generation of Trillium TPUs offers up to 4.7 times the performance improvement per chip compared to the previous TPU v5e, while increasing energy efficiency by over 67%.

This leap is due to Google's enlargement of the matrix multiplication units (MXUs) and an increase in clock speed. Additionally, Trillium is equipped with the third generation of SparseCore, an accelerator designed to handle large embeddings common in advanced sorting and recommendation workloads.
SparseCores can effectively accelerate heavy embedding workloads by strategically offloading random and fine-grained access from TensorCores. Google has also doubled the capacity and bandwidth of high-bandwidth memory (HBM) and increased the bandwidth of chip-to-chip interconnects (ICI), enabling Trillium to support more complex models and significantly shorten training times and response latency for large models.
In a high-bandwidth, low-latency Pod, Trillium can scale to 256 TPUs. Through multi-slice technology and Titanium intelligent processing units (IPUs), Trillium can further scale, connecting tens of thousands of chips to form a super-scale supercomputer supported by a multi-terabit-per-second data center network.
Vision-Language Open-Source Model PaliGemma
Google has not forgotten the open-source community, releasing its first vision-language open-source model—PaliGemma, optimized for image annotation, visual question answering, and other image tagging tasks. It can be found on GitHub, Hugging Face models, Kaggle, Vertex AI Model Garden, and ai.nvidia.com (using TensorRT-LLM acceleration), available now.

Additionally, Google plans to release a larger-scale open-source model, Gemma 2 27B, in June. In terms of performance, the new Gemma 27B surpasses the 70B-parameter Llama 3 while being more than twice as efficient, capable of running efficiently on GPUs or a single TPU host.

Conclusion
After reviewing the entire conference, although it didn't attract as much attention as OpenAI, I believe Google I/O still had many highlights, prompting me to write this long article.
Overall, I feel that Google is catching up with OpenAI, even surpassing it in some aspects. Whether it's the 2M super-long context, text-to-video Veo, AI+Google search engine, or voice assistant Astra combined with Google Glass, all have shown significant advancements.
However, Google's biggest challenge now is how to deal with the commercialization challenges brought by LLM in search results, a longstanding issue since last year. How to ensure that their models do not cut into the search engine's main artery? After all, many believe that replacing the first search result with an LLM result has a significant impact on SEO (search engine optimization) & website commercialization.
In the end, I still hope Google continues to improve,
Because on the road to AGI, a hundred flowers blooming is far more exciting than a single branch standing alone!
