🟢 Claude3's Midnight "Raid" on GPT, OpenAI Updated in Half a Day?
🥯 Claude3 Family Launched, Targeting GPT-4
Claude has finally made a move, and once again, it was released late at night 😭. Although the copy didn't mention GPT-4, the image clearly targets both GPT-4 and GPT-3.5 as key competitors. It seems everyone is learning from OpenAI's surprise release strategy.
I recommend subscribing to email notifications from all official AI product accounts on X, otherwise, you might get a sleepless surprise at any time 🥱.
🎹 Summary: The Claude company has launched the Claude3 model series, which includes Claude 3 Haiku, Claude 3 Sonnet, and Claude 3 Opus. These models feature high performance, multilingual capabilities, groundbreaking speed, visual recognition, and reduced error rates, catering to various intelligent needs across different fields.
(GPT-4 summarized 😏)
- Now available: Opus and Sonnet models, accessible globally in 159 countries via claude.ai and the Claude API. Free users can also use the Claude 3 Sonnet model.
- Coming soon: Haiku model, stay tuned.
Due to Claude's strength in text capabilities, the naming this time is quite creative. Haiku refers to Japanese three-line poems, Sonnet to fourteen-line poems, and Opus to epic musical compositions.
Pricing?
As a GPT-4 subscriber, my first concern was not the performance but the pricing of the new Claude 3 models.
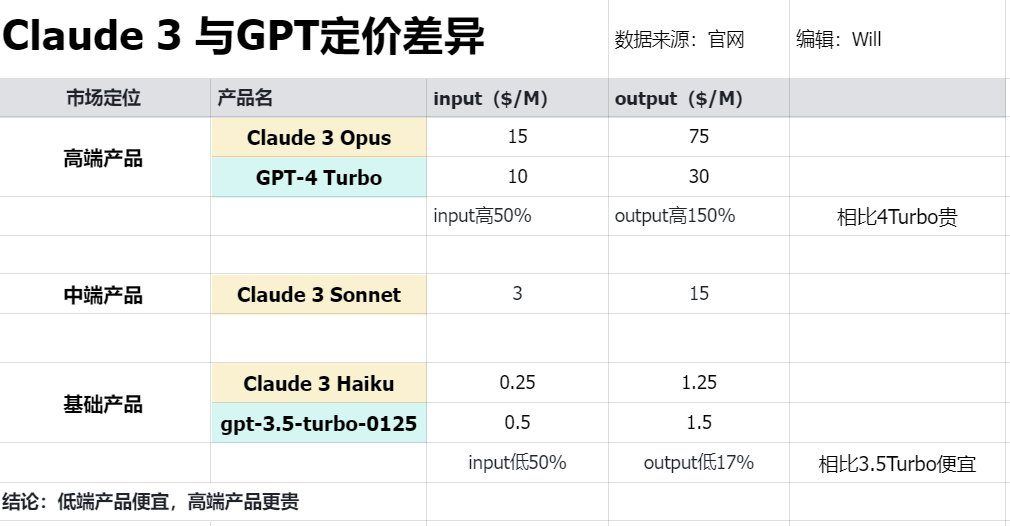
- Web version: To experience Opus, you need to subscribe to the $20/month pro package, the same price as GPT-4!
- API: Opus is priced higher than GPT-4 Turbo but significantly lower than GPT-4 32K. Sonnet is cheaper than all versions of GPT-4 (including GPT-4 Turbo), and Haiku (yet to be released on Claude API) is even cheaper than GPT-3.5 Turbo.
Core Advantages
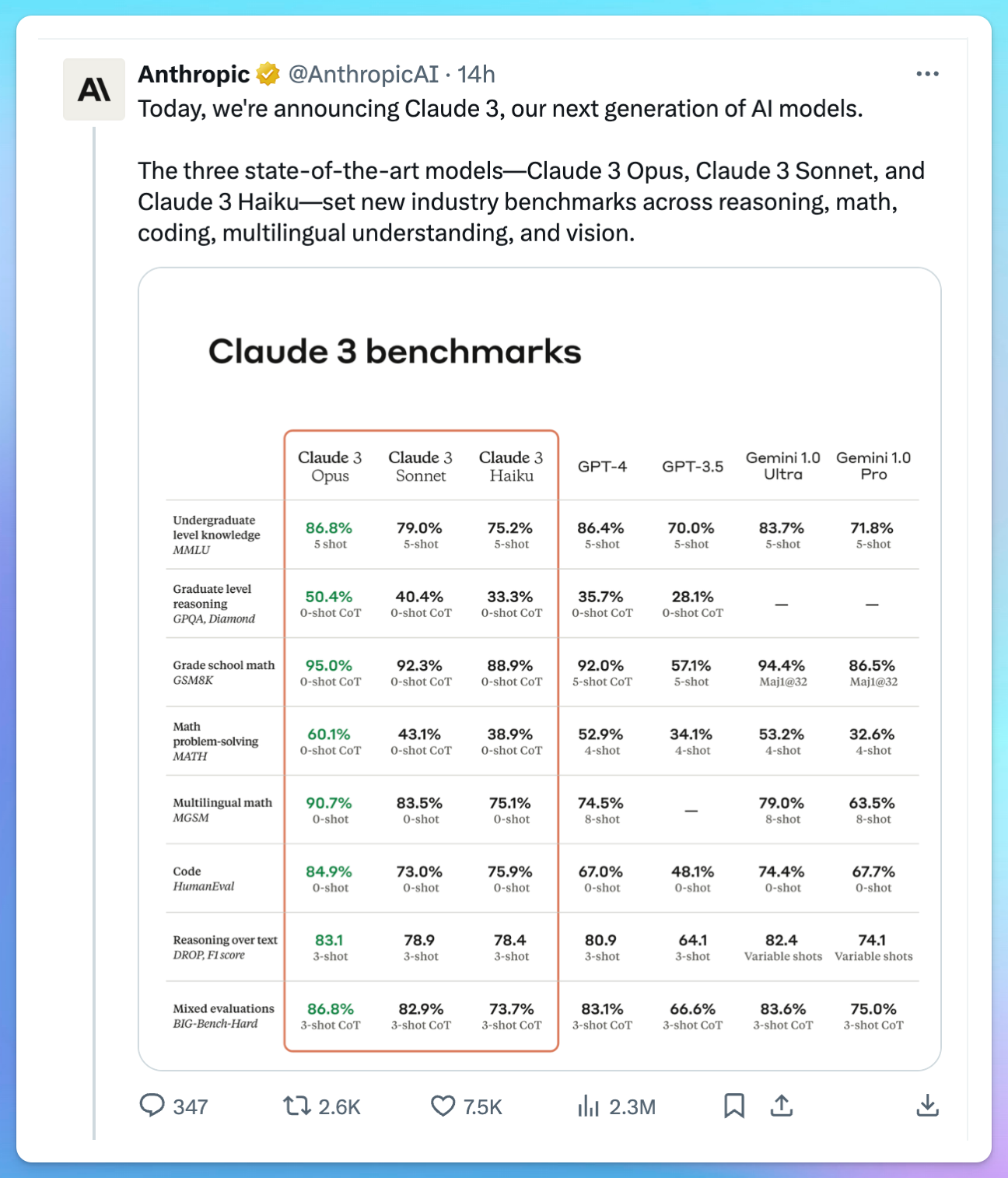
The most seen image by everyone must be this one:
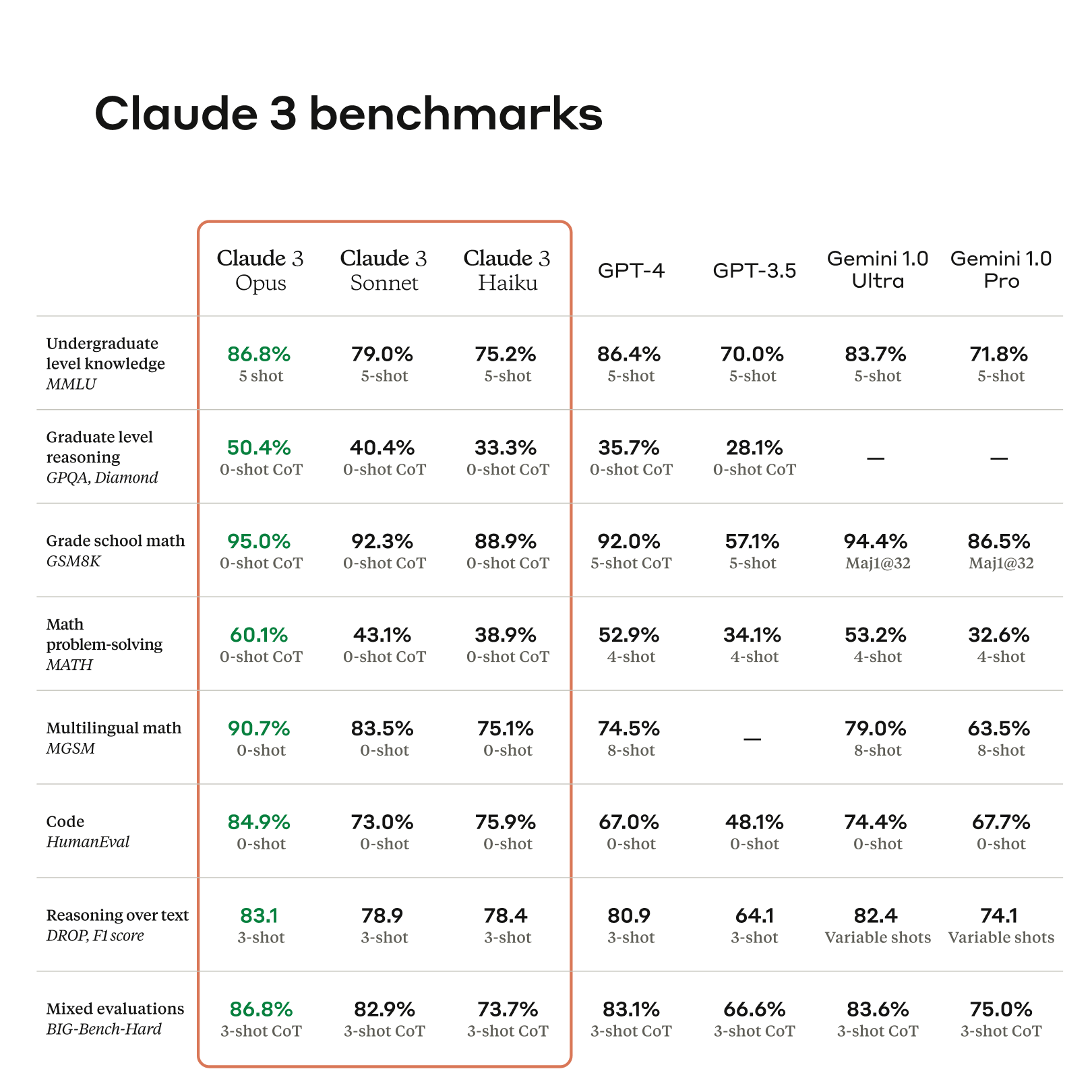
A brief interpretation of the key indicators worth noting:
- 👍👍👍 Reasoning Ability: Claude3 Opus achieved a 90.7% accuracy rate on the multilingual mathematical reasoning test set (MGSM) in a 0-shot scenario (without any examples), whereas GPT-4 only reached 74.5% accuracy with 8-shot (with 8 examples) (-16.2) accuracy. This is also reflected in MATH (math problem-solving) and GPQA (graduate-level reasoning datasets).
- 👍👍 Comparable Language Processing Ability to GPT-4: Claude3 performed similarly to GPT-4 on the MMLU, GSM8K, and HumanEval test sets.
Claude 3 Real Test!
With such impressive claims, it's time to test it hands-on!
I summarized the improvements highlighted in the official technical documentation using Claude3 Opus.
- New Intelligent Standards (Powerful Reasoning Ability): The Claude 3 series surpasses peers in multiple evaluation benchmarks, especially the Opus model, leading the frontier of general intelligence with near-human understanding and fluency.
- Near-Instant Results: The Claude 3 models support immediate customer service and data extraction, with the Haiku model renowned for its ultra-fast response.
- Powerful Visual Capabilities: The Claude 3 models can handle various visual formats, making them suitable for decoding visual information in enterprise knowledge bases.
- Fewer Refusals: Compared to earlier versions, the Claude 3 models significantly reduce the likelihood of refusal when handling edge cases, demonstrating a more nuanced understanding.
- Improved Accuracy: The Claude 3 models have made significant strides in maintaining high accuracy, especially when dealing with complex problems.
- Long-Context Processing with Near-Perfect Recall: All three models can handle inputs exceeding 1 million tokens, with the Opus model achieving near-perfect recall.
The features that most attract me and might make me subscribe to Claude are:
Reasoning Ability, Multimodal, All Models Capable of Handling Over 1 Million Tokens
Near-Instant Results are also very appealing, but true 3x speed+ is currently only available with Haiku, and the reasoning ability of Opus, which surpasses GPT-4, has roughly the same response speed as the previous version.
Fewer Refusals also mean the model won't frequently refuse your questions, but this issue has been less common in my current use of the GPT API and GPT web version, while it happens more with Gemini.
Reasoning Ability
Here are some representative examples from X (Let's see Claude & GPT playing brain teasers together):
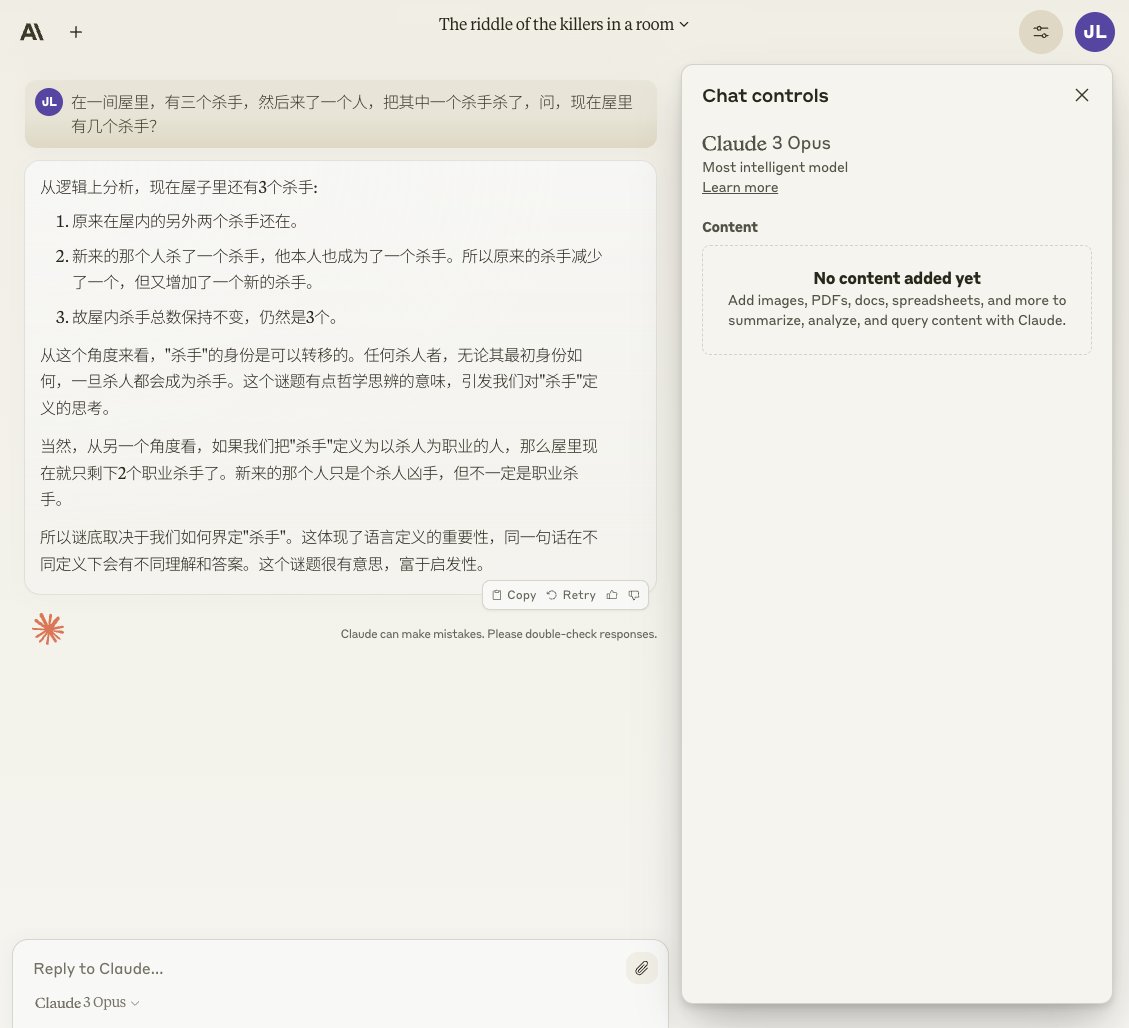
"In a room, there are three killers. Then someone came in and killed one of the killers. How many killers are there in the room now?"
GPT-4 vs Claude 3 Round 1: Draw

"I have 6 eggs, 2 broke, 2 were fried, and 2 were eaten. How many are left?"
GPT-4 vs Claude 3 Round 2: GPT-4 Wins

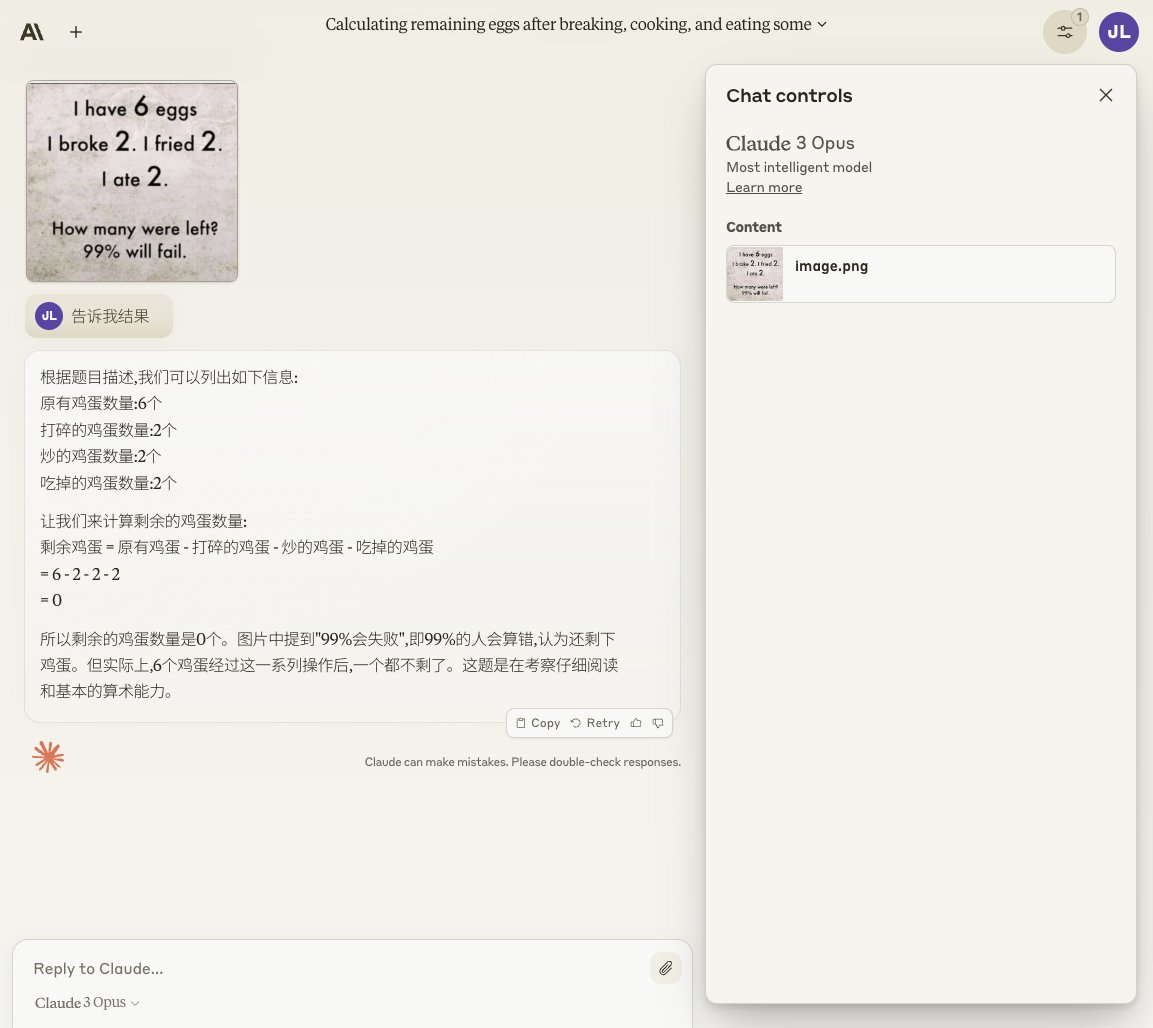
Final Round:
"Which will boil 500g of 25-degree water faster, a microwave or an induction cooker, both rated at 800w? By how much?"
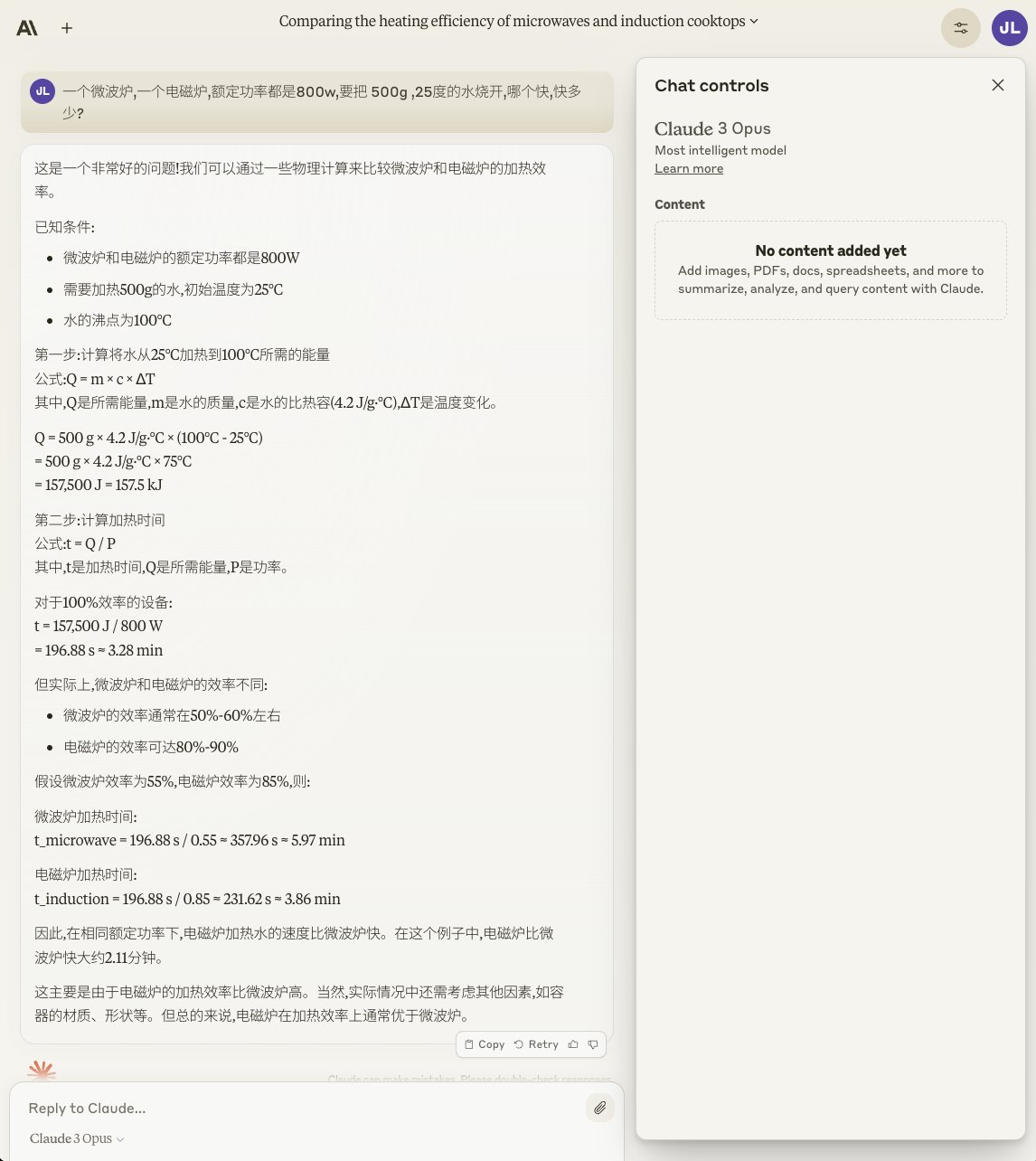
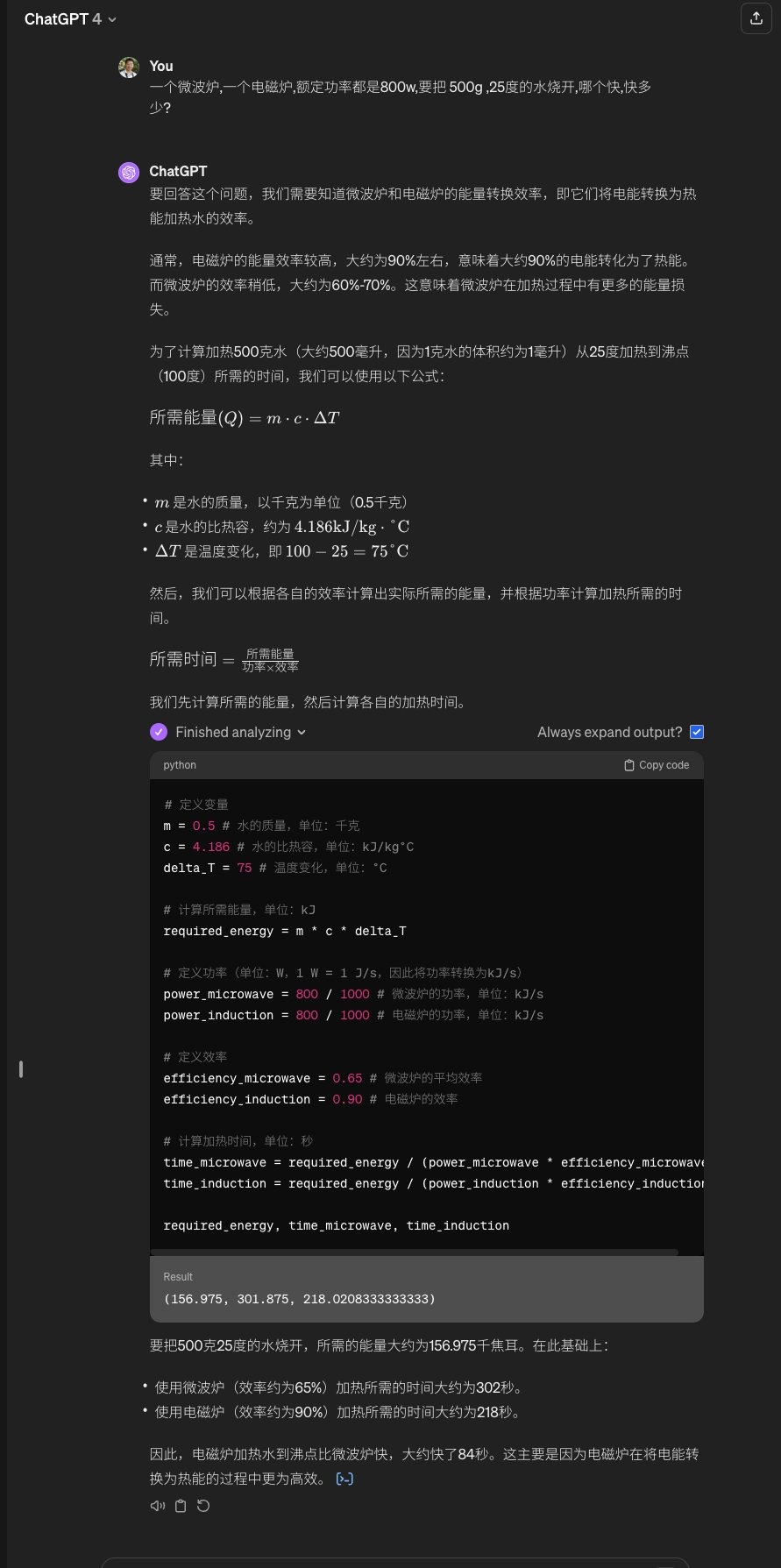
So who won this round? Check it out 👀
Multimodal Real Test
Compared to the previous models, the most notable new capability of Claude3 is its visual recognition ability. This means it can handle various visual materials such as photos, charts, graphics, and technical drawings.
The most common scenarios for daily multimodal use are video & text:
- Emmanuel Ameisen and Erik Schluntz challenged Claude 3 Opus to convert Andrej Karpathy's 2-hour 13-minute video into a blog post with just one prompt, and Claude 3 Opus successfully completed the task.
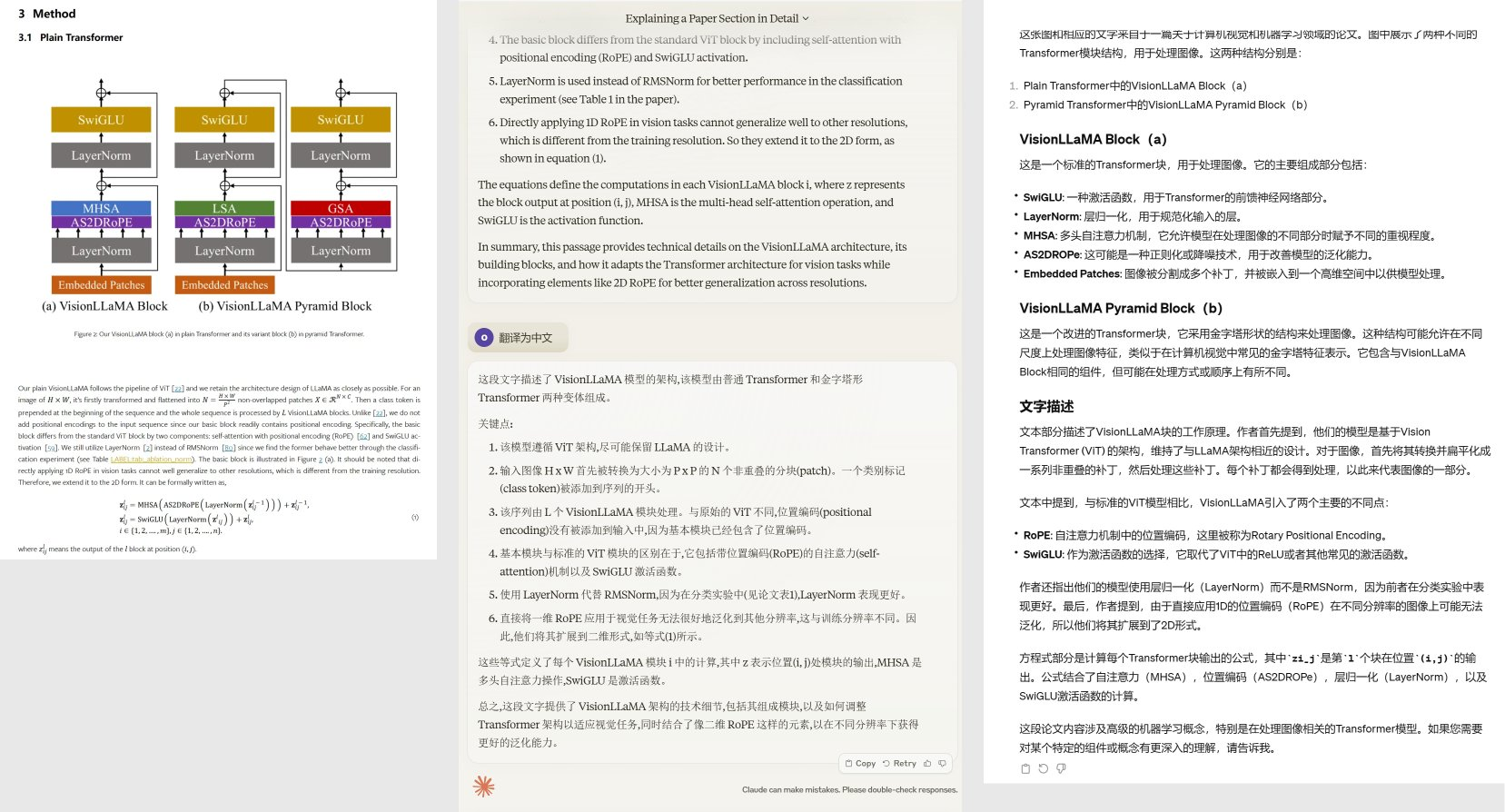
- The expert Guicang had Claude 3 Opus analyze a portion of a paper, which it did clearly, but the information provided was not as rich as GPT-4.
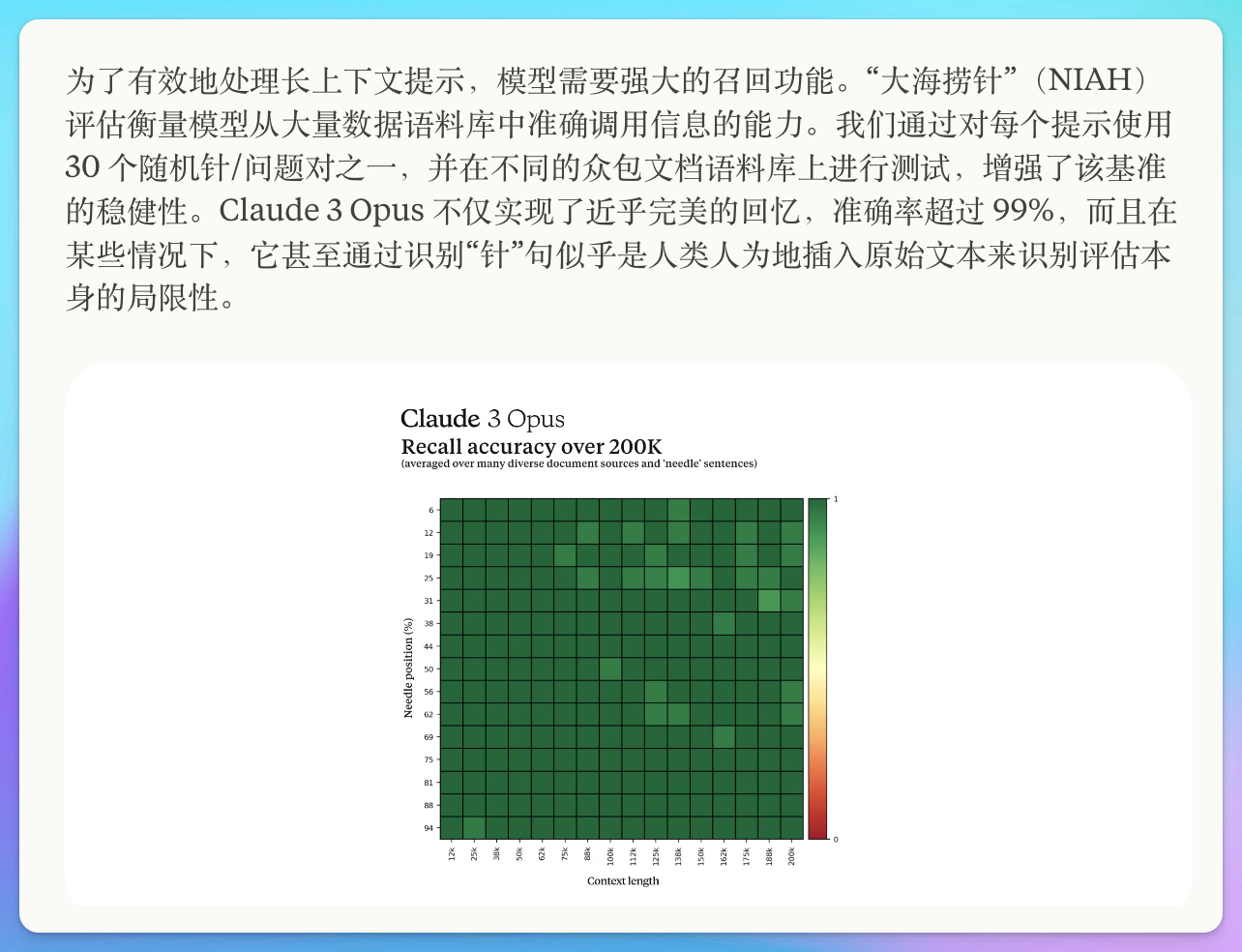
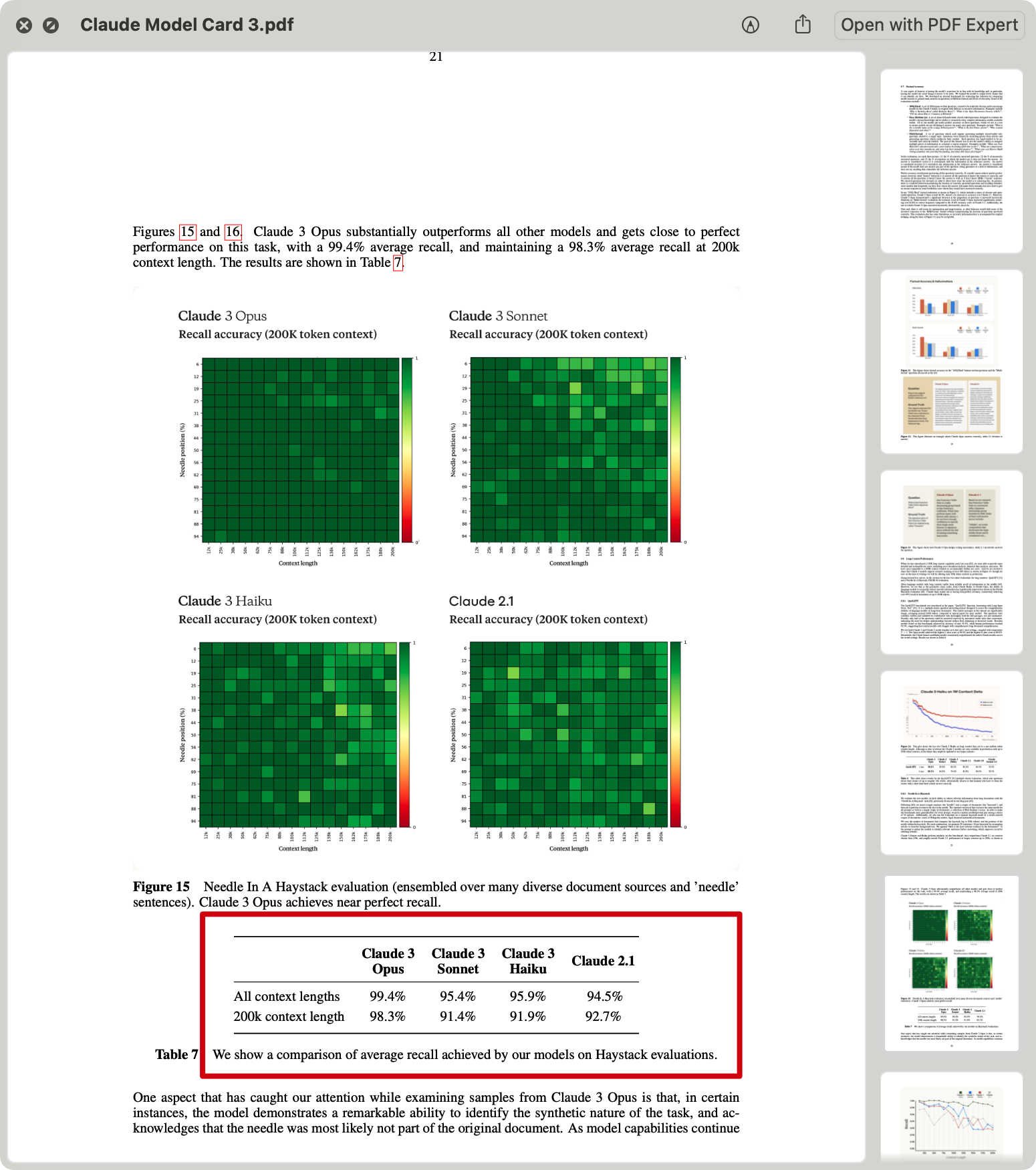
Needle in a Haystack
All models in the Claude 3 series can handle inputs exceeding 1 million tokens. The litmus test for context window capability remains the familiar "needle in a haystack" test.
🤑 "Needle in a haystack" means hiding a specific sentence (the "needle") in a pile of seemingly random documents (the "haystack"), then asking a question that can only be answered by finding that "needle," thus testing the model's information recall ability.
Claude3 Opus not only achieved near-perfect information retrieval with over 99% accuracy but also, in some cases, recognized that the sentences serving as "needles" were deliberately inserted. This level of awareness is truly Cooooool.
If you want to learn more about Claude 3's performance, join me in reading the full technical report.
At the same time, NVIDIA scientist Jim Fan shared his thoughts on Claude-3, highlighting two aspects that complement Claude's other "improvement points."
Domain Expert Benchmarks. I am less interested in saturated benchmarks like MMLU and HumanEval. Claude specifically selected finance, medicine, and philosophy as expert domains and reported performance. I suggest all LLM model cards follow this so that different downstream applications know what to expect.
Refusal Rate Analysis. Overly cautious responses to innocent questions are becoming an epidemic with LLMs. Anthropic is usually at the extreme end of safety, but they recognized this issue and emphasized their efforts in this area. Great!
I love Claude stirring the pot on a stage dominated by GPT and Gemini. But remember, GPT-4V, the high watermark everyone is desperate to beat, was trained in 2022. This is the calm before the storm.
Official Easter Egg
It's evident that the official team is eager to attract new users, and Anthropic has launched a prompt library with diverse creative prompts. This is perfect for those who want to delve deep and fully utilize Claude 3's new features.
https://docs.anthropic.com/claude/prompt-library
Doesn't this interface look familiar?
In Conclusion
From the actual experience, Claude 3 can indeed be said to surpass GPT-4, but don't forget GPT-4V was trained in 2022 ✅. Will OpenAI have any secret moves soon?
As of 2 PM today, OpenAI has fully released two small features: memory and reading capabilities in response to Claude3's big move.

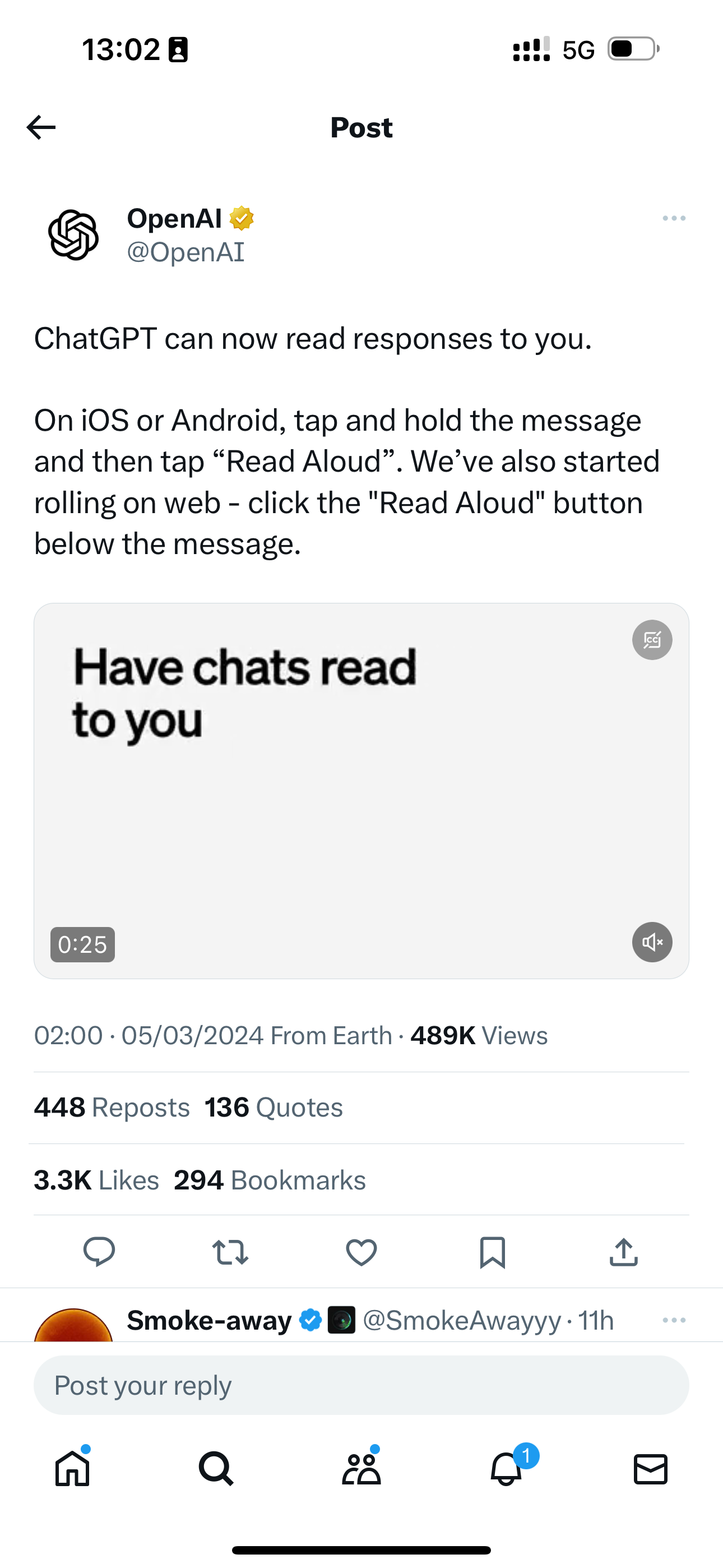
But that's far from enough! Should I stay up late recently to see if GPT-5 suddenly appears 🏃

💡 In 2024, the competition among AI models remains strong, and now I'm eager to subscribe. Currently, the Claude web version is "overloaded," so it's impossible to experience Sonnet. To experience the new Claude3, you need to subscribe to Pro. Should ordinary users subscribe to Claude 3? If you don't have heavy reasoning & long text needs, my suggestion is to wait a bit for OpenAI's big move and more comprehensive reviews of Claude 3.