🟢 What is ChatGPT?
ChatGPT (Generative Pre-Training Transformer) is a chatbot launched by OpenAI in November 2022. It is built on OpenAI's GPT-3.5 large language model and fine-tuned using supervised learning and reinforcement learning techniques.
ChatGPT is a chatbot that allows users to engage in conversations with a computer-based agent. It works by analyzing text input using machine learning algorithms and generating responses designed to mimic human conversation. ChatGPT can be used for various purposes, including answering questions, providing information, and engaging in casual conversation.
One of the key factors that determine the success of a ChatGPT conversation is the quality of the prompt used to initiate and guide the conversation. Well-defined prompts can help ensure that the conversation stays on track and covers topics of interest to the user. Conversely, poorly defined prompts may lead to disjointed or unfocused conversations, resulting in a less engaging and informative experience.
What do G, P, and T stand for in ChatGPT?
GPT: Generative Pre-Training Transformer
Generative
The core of a generative language model, in simple terms, is like "rhyming."
When it has read enough text, it finds some language patterns that appear repeatedly. The reason it can accurately fill in the blank "锄禾日当__ " is not because it reconstructs a scene of farmers working in its mind but because it comes out with a rhyme without thinking.
If you ask it: 3457 * 43216 =, it responds 149575912 (which is wrong; the correct result is 149397712). The reason the 2 in the result is correct is only because it has read so many texts that it vaguely feels that
the numbers ending in 7, the multiplication sign, the numbers ending in 6, and the numbers ending in 2 "rhyme" more like a poem, so it learned such words, not learned calculation. The problem generative models try to solve is to predict what words humans would write given some words.
In the BERT era, to train, people often masked random words in a sentence and let the computer predict those words with the existing model. If the prediction was accurate, the model was reinforced; if wrong, the model was adjusted until it became more accurate after millions or billions of training iterations. However, the generative part of ChatGPT trains and predicts not only words but also the context and intention.
Pre-Training
Many AI models used to be trained for a single goal. For example, given 1000 pictures of cats, I could easily train a model to determine whether a picture contains a cat. These were specialized models.
Pre-Training models are not trained for a specific goal but are trained as a general model in advance. If I have specific needs, I can train it again based on the pre-trained model with some fine-tuning.
It's like hiring a housekeeper who has already been pre-trained by an agency on housekeeping knowledge and pre-trained by a primary school teacher on Chinese conversation. When she arrives at my home, I only need to fine-tune some specific requirements for my home, rather than starting from scratch, teaching her Chinese to make her work.
ChatGPT's pre-training provides everyone (especially entrepreneurs and programmers) with a pre-trained model. This model is strong in language, and no matter how nonsense the content it provides, we must at least admit its writing fluency is impeccable. This is its pre-training part, and the content part of the answer is what we need to fine-tune. We can't just say its output content is not enough after buying an Apache server without feeding it any content.
Transformer
A language transformer takes a sequence of language as input and converts it into a numerical representation using an encoder (for example, GPT uses 1536 floating-point numbers (also called 1536-dimensional vectors) to represent any word, sentence, paragraph, article, etc.). It then transforms this representation into a new sequence and finally uses a decoder to output it. This transformer is the core of natural language processing.
For example, if you input the word "Apple" into ChatGPT, it returns:
[
0.0077999732,
-0.02301609,
-0.007416143,
-0.027813964,
-0.0045648348,
0.012954261,
.....
0.021905724,
-0.012022103,
-0.013550568,
-0.01565478,
0.006107009]
These 1536 floating-point numbers represent "Apple" (one or more dimensions' combinations express the meaning of "sweet," another set expresses the meaning of "round," and another set expresses the meaning of "red," etc. However, which specific combinations express these meanings is unknown).
Then these numbers are passed to the decoder, and if limited to Chinese, it will decode as "苹果"; if limited to Spanish, it will decode as "manzana"; if limited to emoji, it will output "🍎". In short, through encoding, transforming, and decoding, it completes the transformation from "Apple" to the target output language.
What ChatGPT does goes far beyond translation. Essentially, it converts one sequence of language into another sequence of language, performing this task so well that it gives the illusion of having thoughts.
GPT: Generative Pre-Training Transformer
Putting the above three sections together, GPT is
A pre-trained model that uses a generative approach to transform input text into output text.
The Technology Behind ChatGPT
The technology behind ChatGPT is InstructGPT, with the paper titled "Training language models to follow instructions with human feedback."
The principle of language models is to predict the next word given a sequence of text. In pre-training, the training data is unlabeled and uses self-supervised learning. When we ask the model questions, such as "What is the Pythagorean theorem?" we hope the model has seen related data during pre-training, so the model's behavior depends on the pre-training content. In today's large language models, the vocabulary size is in the tens to hundreds of billions, so we cannot look into the details of what is inside. We can only roughly know that the quality of the text we obtained is good, and after preprocessing the data, we feed it to the model for training. This situation leads to a lack of precision and controllability of the model and faces effectiveness and safety issues. For example, if I ask the model to perform a task not present in the training text, the model may not have learned it. Or what if the model outputs inappropriate or sensitive content?
Overall, a larger model does not necessarily provide a better user experience because it may not align with the user's goals (in work, we often use the term "aligned" to ensure that the goals between different teams in a company remain consistent). The same applies to the model; it may output unsatisfactory or even offensive content because it is not aligned with humans. Academically, as long as the model can achieve high scores in benchmarks, it is sufficient. However, in actual commercial applications, user experience is crucial, and outputting sensitive content can have very negative impacts. Therefore, aligning the model with humans introduces fine-tuning based on human feedback.
Firstly, a dataset of questions was collected through the OpenAI API, and a labeling tool was used to annotate these questions, fine-tuning GPT-3 on this dataset (supervised learning).
Next, another dataset was collected, giving some questions and asking the model to generate different outputs. Human annotators then rated the model's outputs, creating rankings that were used in reinforcement learning based on human feedback, ultimately producing the InstructGPT model.
RLHF
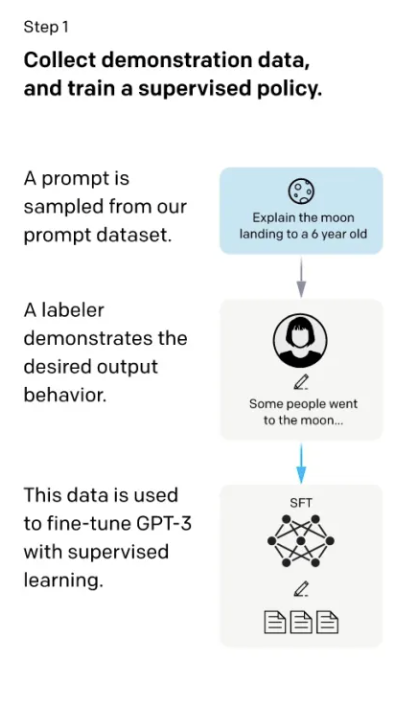
Step one involved having people annotate a dataset, writing various questions in the dataset. These questions in GPT are called prompts. The questions were similar to asking a 6-year-old child to explain what lunar landing is, and the annotator provided an answer to the question, such as "Some people went to the moon and so on...." This created a dataset with questions and answers, which was then used to fine-tune GPT-3, producing the SFT (supervised Fine-tune) model. Although data was annotated and fine-tuned, GPT essentially treated it as predicting the next word given some words, similar to the pre-training process of language models. However, this process is expensive if all collected data is annotated, leading to step two.
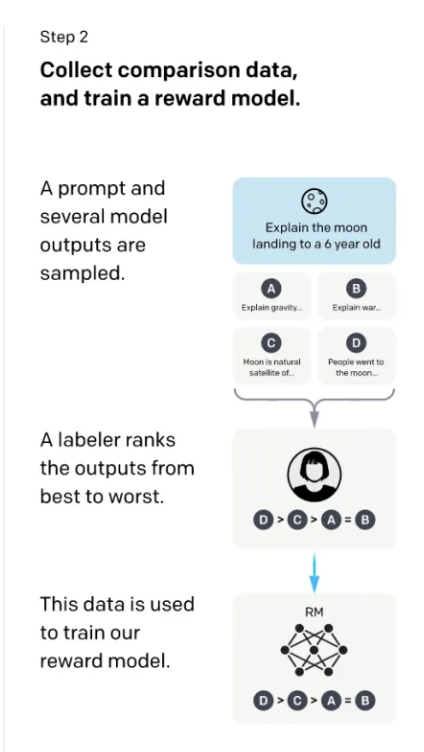
In step two, annotation became simpler. Given a question, such as explaining lunar landing to a 6-year-old, the SFT model generated answers. GPT's generation principle is to predict the probability of each word, sampling based on this probability to produce multiple different answers. Human annotators then rated these answers, ranking them (e.g., D > C > A = B). This ranking served as the data annotation. With these rankings, a reward model (RM) was trained to score answers based on the prompt, ensuring the scores matched the annotated rankings (D > C > A = B). The goal of step two was to train a scoring model.
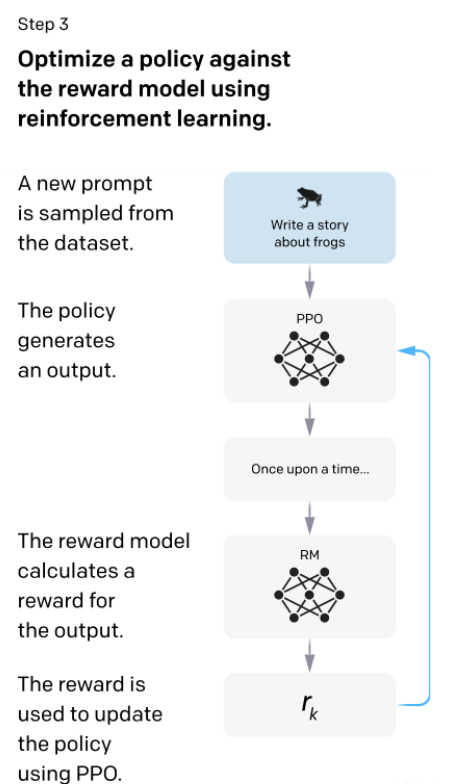
Step three involved further fine-tuning the SFT model from step one, generating answers that the RM model from step two scored. The SFT model's parameters were updated to maximize these scores. Theoretically, if enough data were annotated in step one, steps two and three might be unnecessary. However, writing an answer involves generative task annotation, while scoring answers involves discriminative task annotation, which is less costly. Therefore, steps two and three allow for more data at the same annotation cost, enhancing the model's performance. The final model after step three is InstructGPT.