🟢 Basics of Artificial Intelligence
Article Length: 2600 Words, Reading Time: 10 Minutes Recommendation Reason: After gaining a basic understanding of models, it becomes easier to grasp the upper and lower limits of large models like GPT.
What is Artificial Intelligence?
Many people can give numerous examples of artificial intelligence, but defining it clearly can be challenging. In reality, artificial intelligence is not exclusive to computer science; it is also a concept studied in other fields like neuroscience, psychology, and philosophy. From my perspective, artificial intelligence is the ability of machines to simultaneously acquire, establish, develop, and apply knowledge.
In computer science, we can consider artificial intelligence as a goal, with machine learning, deep learning, reinforcement learning, and other algorithms as methods to achieve this goal.
The following image is a classic depiction of the relationship between artificial intelligence, machine learning, and deep learning.
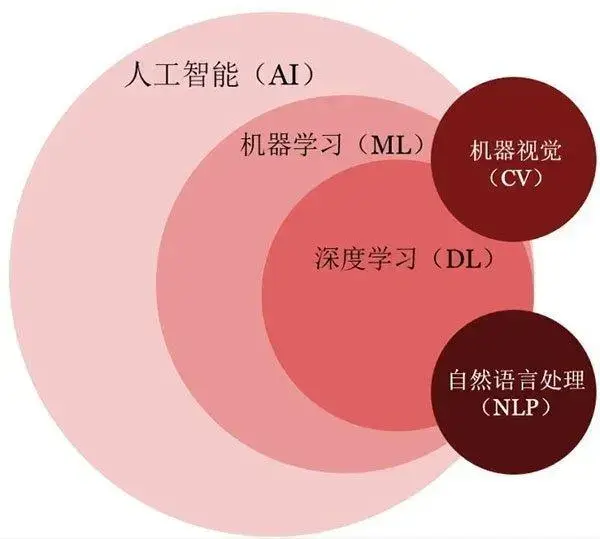
Machine Learning
We can divide machine learning methods into several categories: supervised learning, unsupervised learning, and reinforcement learning.
In supervised learning, the dataset has labeled data. For instance, if we want a machine to classify images of fruits, the dataset needs not only various fruit images but also labels indicating what fruit is in each image.
In unsupervised learning, the dataset has no labels. Using the fruit image example again, the dataset would only contain various fruit images without any labels.
Reinforcement learning involves three elements: an agent, an environment, and actions. The agent performs actions based on the environment and receives rewards or punishments based on a defined reward function. For example, in playing Go, winning would result in a reward, while losing would result in a punishment. We set up mechanisms for the agent to change its behavior to maximize the reward function, meaning it becomes smarter by constantly updating its actions through interaction with the environment.
Semi-supervised Learning
In semi-supervised learning, part of the dataset has labels, and part does not. As the volume of data on the internet increases, labeling all data becomes nearly impossible. Therefore, training with a small amount of labeled data and a large amount of unlabeled data has become a research direction.
Self-supervised Learning
Self-supervised learning involves using auxiliary tasks to extract representations from a large amount of unlabeled data as supervisory information to enhance the model's feature extraction ability. For example, in natural language processing pre-training, tasks like filling in the blanks and determining if one sentence follows another are used for training. In self-supervised learning, the supervisory information is not manually labeled but automatically constructed by the algorithm from a large amount of unlabeled data.
Deep Learning
Deep learning is mainly based on deep neural networks and belongs to supervised learning, requiring labeled data for training. However, current deep learning models are not purely supervised learning. For example, the pre-training process of language models is self-supervised learning.
Neural network structures are diverse, and the layers are often stacked deep, making the network a black box without rigorous mathematical proof of its effectiveness, unlike traditional statistical machine learning methods like SVMs (Support Vector Machines). Therefore, deep learning practitioners often humorously refer to their work as alchemy, where they input data (raw materials) and wait to see if the results meet expectations (alchemy success).
Training
Once we have the model and the training dataset, how is AI trained? AI training generally involves data collection and preprocessing, model construction, defining the loss function and optimization methods, training, validation, and optimization.
The quantity and quality of data are crucial. There is a saying in the industry: "Data is king." The larger the data volume and the higher the quality, the more "intelligent" the AI theoretically becomes.
The "learning" process of AI is essentially updating model parameters. How does AI update parameters? By defining the loss function and using gradient descent.
The loss function measures the discrepancy/inconsistency between the model's output and the desired output. The model's output is called the prediction, while the dataset's labels are the actual values. For example, to train a model to distinguish between different fruits, we convert the labels into numerical forms before training (e.g., 1 for apple, 2 for banana, 3 for grape). If the model reads an apple image and predicts 2, but the actual label is 1, the loss function measures this error.
There are many types of loss functions, used depending on the task. With a loss function, we can optimize the model's parameters to minimize the loss function—the smaller the loss, the more accurate the model's predictions. One common optimization method is gradient descent, which can be likened to descending a mountain:
Imagine a person trapped on a mountain needing to descend (find the lowest point, the valley). Due to heavy fog, visibility is low. They must use surrounding information to find the path. By using the gradient descent algorithm, they start from their current position, look for the steepest downward slope, and walk in that direction. Repeating this process eventually leads them to the valley.
During gradient descent, the model's parameters are continually updated until the lowest point is reached.
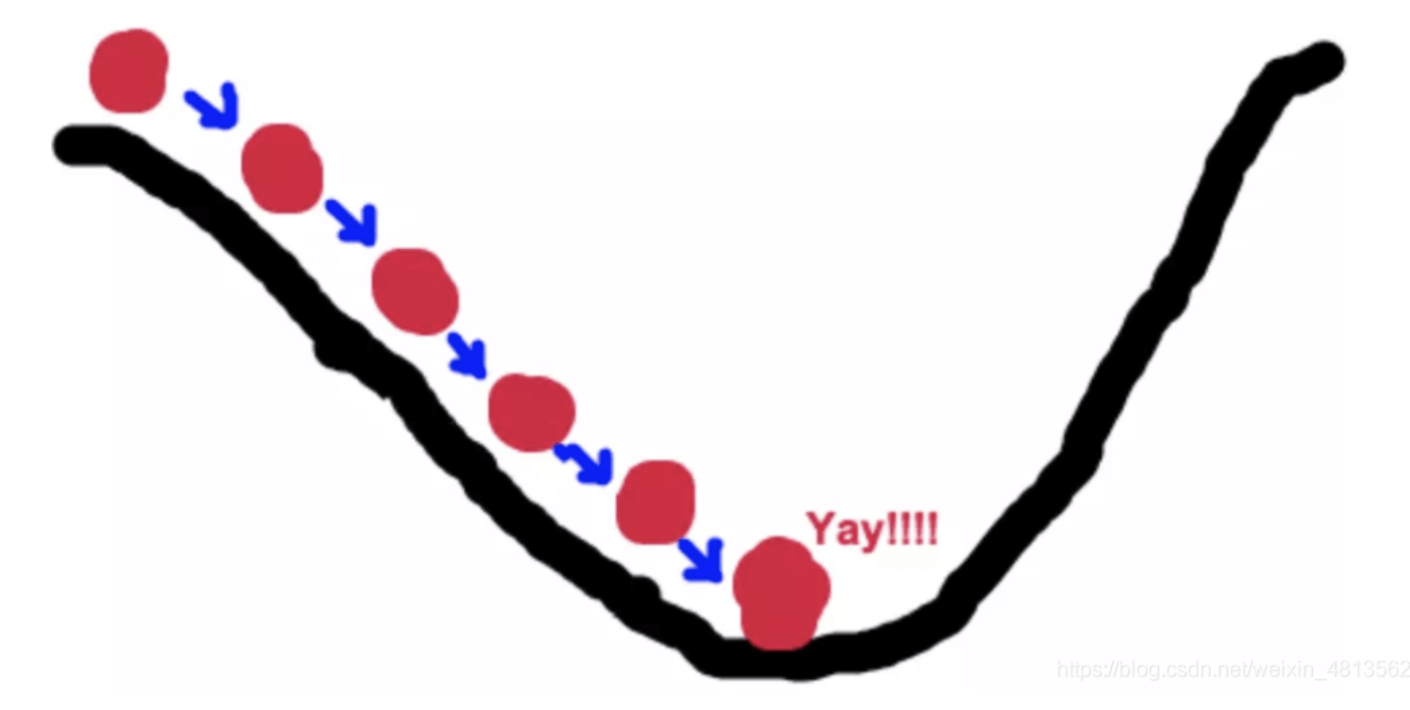
While the principle of gradient descent is straightforward, in practice, the landscape is not just one peak and one valley, so the valley reached may only be a local minimum, not the global minimum. There are many improvements to gradient descent to prevent the model from stopping at a local minimum. However, due to the complex solution space of neural networks, it is not always possible to find the global minimum or prove the point found is the global minimum. Nonetheless, the points found are often good enough, making the extensive search for the global minimum unnecessary.
Overfitting and Underfitting
After collecting and preprocessing the data, the dataset is not directly used for model training. Typically, it is split into a training set and a test set (80:20 ratio). The test set data is not seen by the model during training. Once the model is trained on the training set, its performance is tested on the test set. The image below shows three common scenarios: underfitting, good fit, and overfitting.
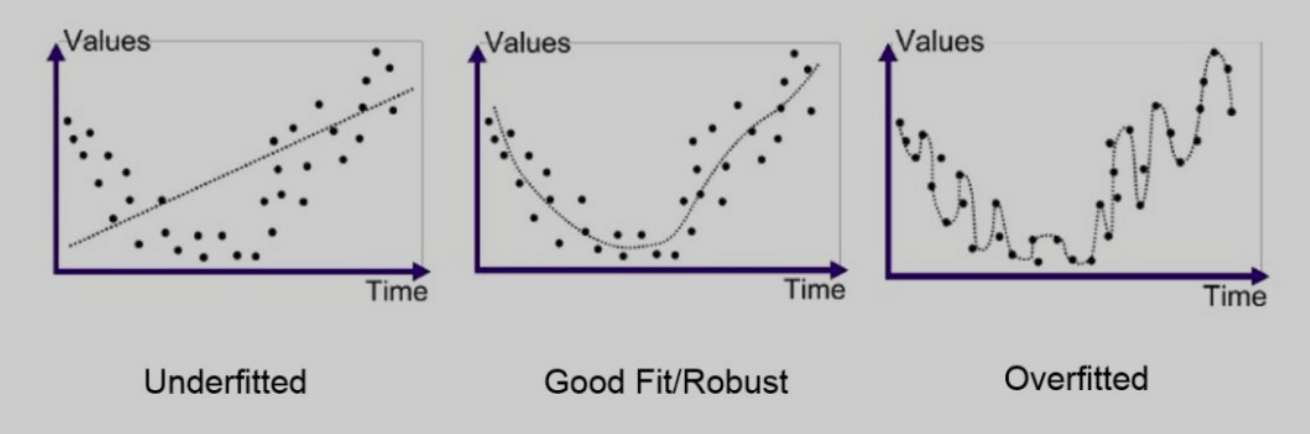
Underfitting indicates the model hasn't learned enough; it's not smart enough to learn what we want. It performs poorly on both the training and test sets. Solutions for underfitting include:
- Adding more features
- Using nonlinear models
- Using more complex models
Overfitting, on the other hand, means the model has learned too well on the training set, becoming too rigid. It performs excellently on the training set but poorly on the test set. For example, in handwriting recognition, an overfitted model would only recognize handwriting identical to the training data. Solutions for overfitting include:
- Expanding the training dataset
- Reducing the model's complexity or using simpler models
- Adding regularization
- Stopping training at the right time to prevent overtraining