🟢 New Features in Claude - Streamlined Prompt Creation and Testing
Stand users are drawn to each other. The new update from Claude really hit the spot for me (an old meme, I know).
As always, I'll start with a concise summary:
"Claude's new features support the generation, testing, and evaluation of prompts within the Anthropic console, with a particular emphasis on automated test case generation and comparison of different model outputs."
This aligns perfectly with what I’ve been working on.
A month ago, a 76+ page paper containing over 1,500 prompts was released, co-authored by OpenAI, Microsoft, and various universities.
The report analyzes 58 prompt engineering techniques, covering topics such as multilingual, multimodal, agent-based prompts, model evaluation, safety, and alignment.
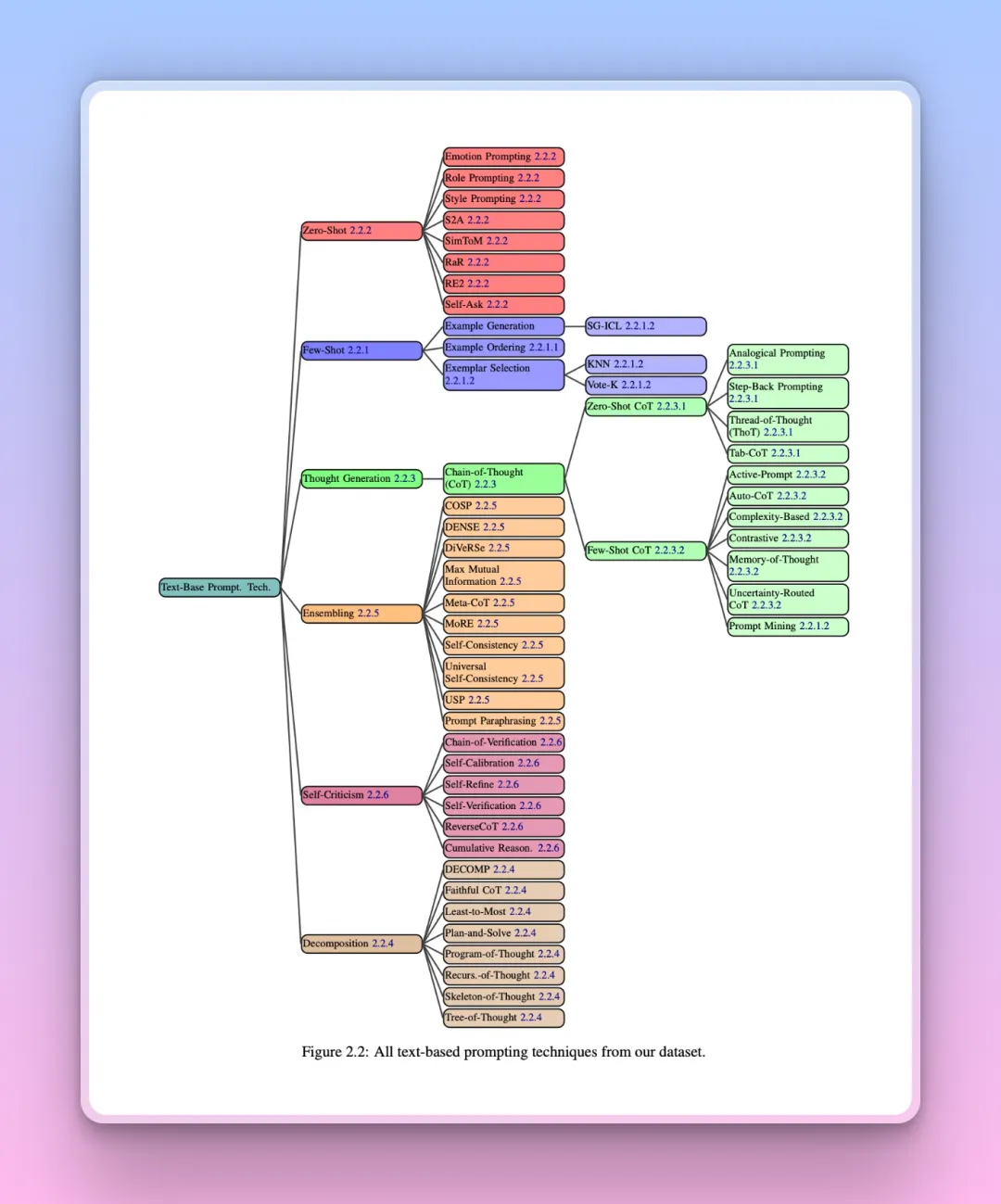
Among them, what caught my eye, of course, were the prompts (Prompt) that I use every day. While thoroughly reading the paper, I wanted to collect some inspirational techniques that can be memorized and easily used in daily practice, such as:
- Few-shot|Provide examples to the model to learn from and produce output.
- Structured Output|Claude prefers XML tags, while GPT leans towards Markdown and JSON.
On the other hand, I wanted to save prompt templates that can be quickly copied during development, such as:
- CoT (Chain-of-Thought Prompting)
- ToT (Tree of Thoughts)
So, did I finish reading it? Yes!
Top 20 Prompt Techniques: Few-shot Learning wins by a landslide! Plan-and-Solve/Agent follows closely behind.
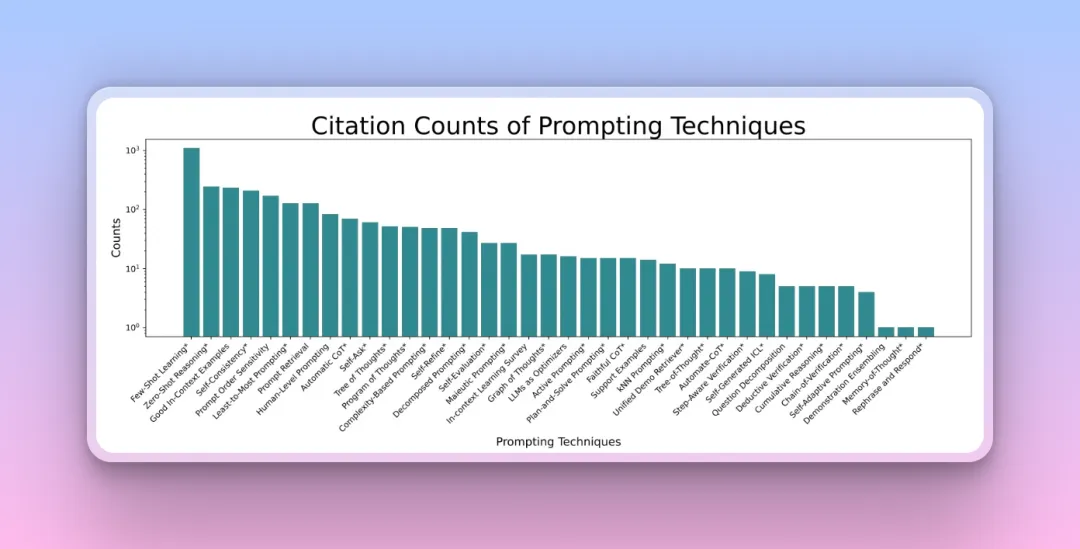
Just in time for Claude’s new update!
Today, I’m going to bring the best of the 1,500+ prompts and 58 techniques to test Claude’s strength!
This feature is currently available in the console (https://console.anthropic.com).
The console provides a built-in prompt generator, powered by Claude 3.5 Sonnet. I can describe my task (such as the English-Chinese translation task I use daily), and have Claude generate prompts.
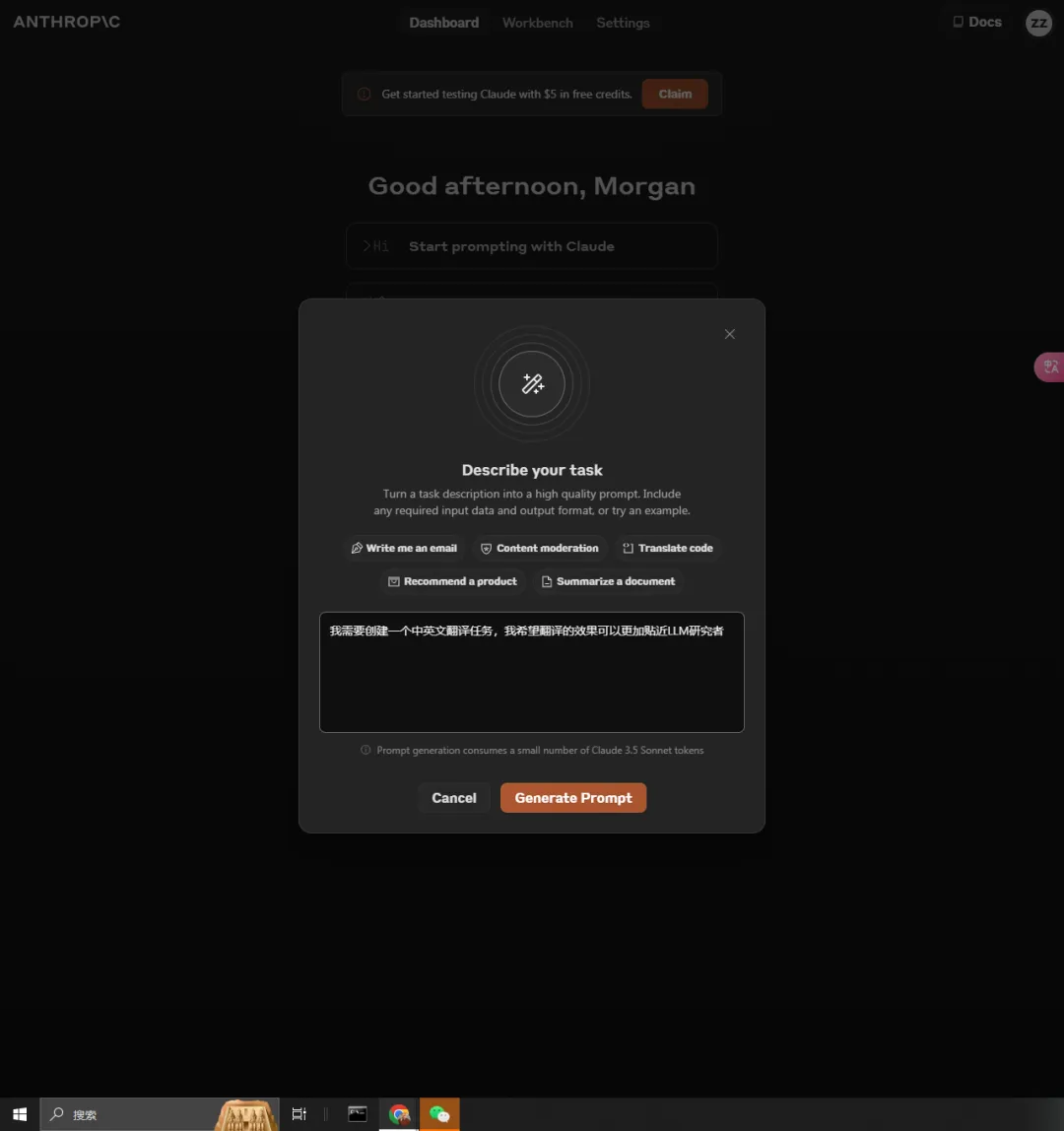
(It’s a bit like the process of creating GPTs.)
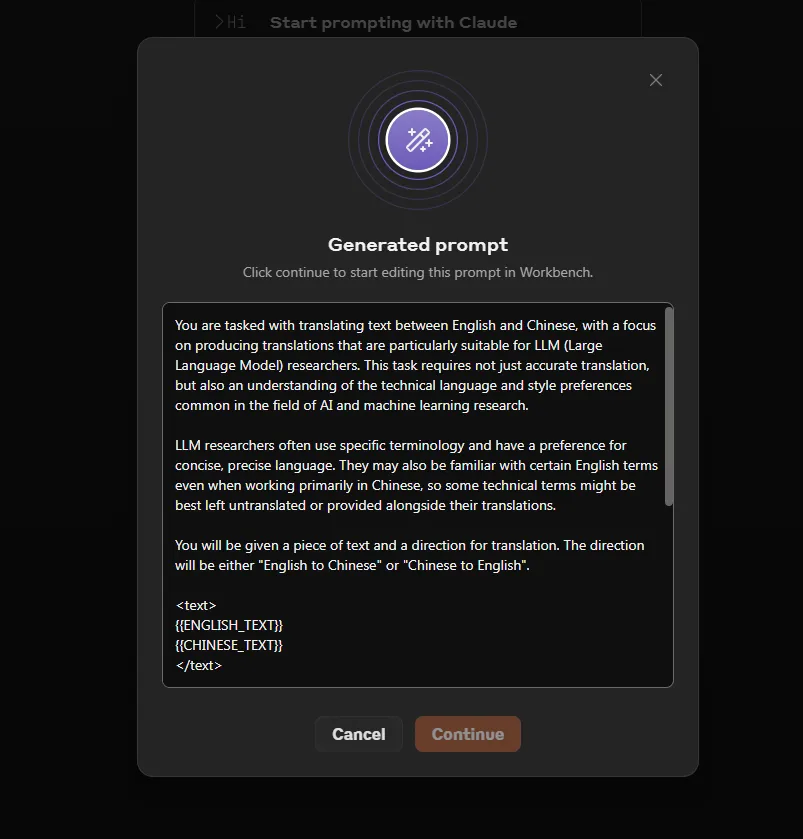
Here’s the complete prompt I’ve pasted as well:
You are tasked with translating text between English and Chinese, with a focus on producing translations that are particularly suitable for LLM (Large Language Model) researchers. This task requires not just accurate translation, but also an understanding of the technical language and style preferences common in the field of AI and machine learning research.
LLM researchers often use specific terminology and have a preference for concise, precise language. They may also be familiar with certain English terms even when working primarily in Chinese, so some technical terms might be best left untranslated or provided alongside their translations.
You will be given a piece of text and a direction for translation. The direction will be either "English to Chinese" or "Chinese to English".
<text>
{{ENGLISH_TEXT}}
{{CHINESE_TEXT}}
</text>
<direction>{{DIRECTION}}</direction>
When translating, consider the following:
1. Maintain technical accuracy, especially for AI and ML-related terms.
2. Use concise language where possible without losing meaning.
3. For Chinese to English translations, use American English spelling and phrasing.
4. For English to Chinese translations, use Simplified Chinese characters.
5. When appropriate, keep important technical terms in English, followed by a Chinese explanation in parentheses.
6. Aim for a natural flow that would sound familiar to an LLM researcher in the target language.
Provide your translation within <translation> tags. After the translation, include a brief explanation of any challenging aspects of the translation or notable choices you made, enclosed in <notes> tags.
Here are two examples of how your output should be structured:
Example 1 (English to Chinese):
<translation>
我们使用了一个大型语言模型(Large Language Model,LLM)来生成文本。该模型经过了 fine-tuning(微调),以提高其在特定任务上的性能。
</translation>
<notes>
Kept "Large Language Model" and "fine-tuning" in English with Chinese explanations, as these are common terms in the field. Used concise phrasing while maintaining technical accuracy.
</notes>
Example 2 (Chinese to English):
<translation>
We implemented a novel attention mechanism to enhance the model's ability to capture long-range dependencies. This significantly improved the perplexity scores on our benchmark dataset.
</translation>
<notes>
Translated "注意力机制" as "attention mechanism" and "困惑度分数" as "perplexity scores", as these are the standard terms used in English LLM research papers. Maintained a concise, technical style typical of research writing.
</notes>
Now, please proceed with the translation task using the provided text and direction.
You can really see how strong Claude's generated prompts are—using techniques like few-shot learning and CoT (Chain-of-Thought), it produces exceptionally well-crafted prompts!
(Prompt engineers, do you still have a job?!)
It can even help you easily generate test cases.
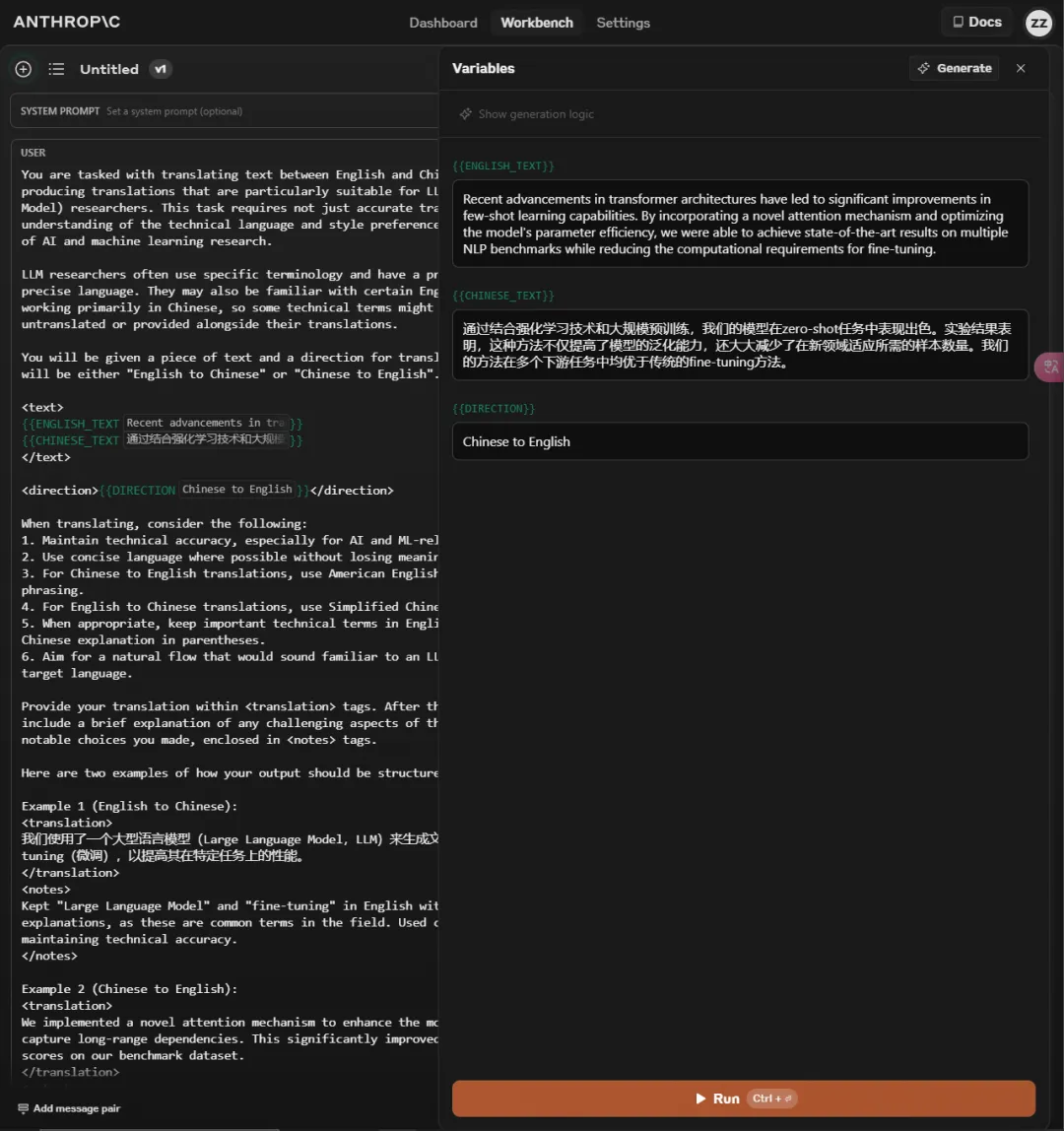
Let's do a comparison: I used the translation prompt shared by Bao Yu and compared it with the one generated by Claude.
[Comparison Results]
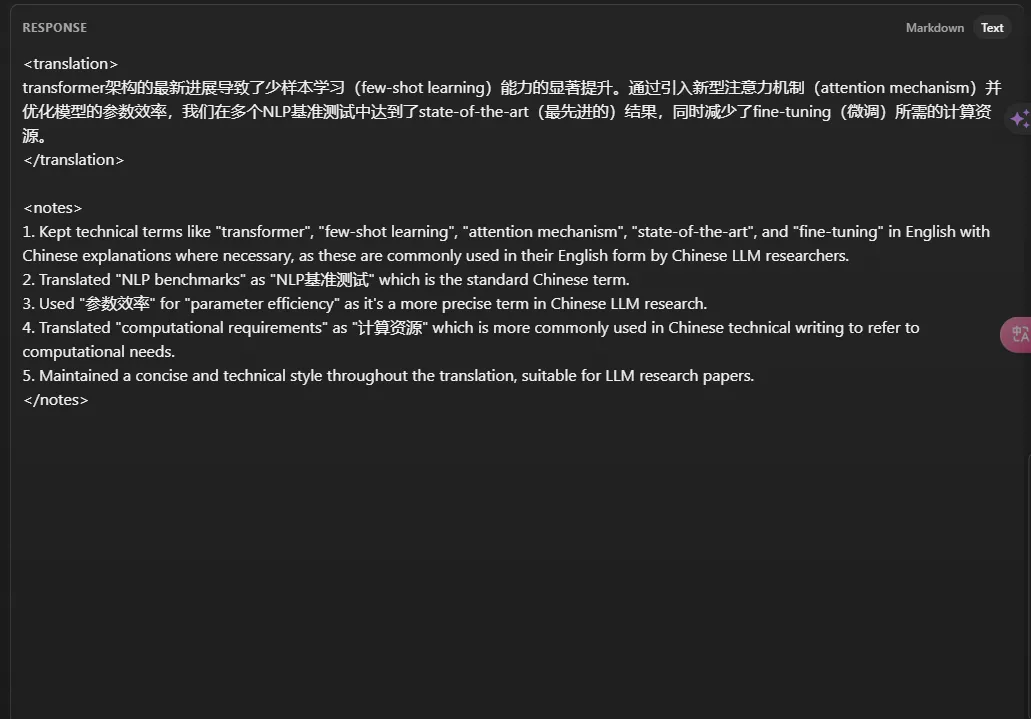
Claude’s generated prompt results:
GPT-4o + handwritten prompt:
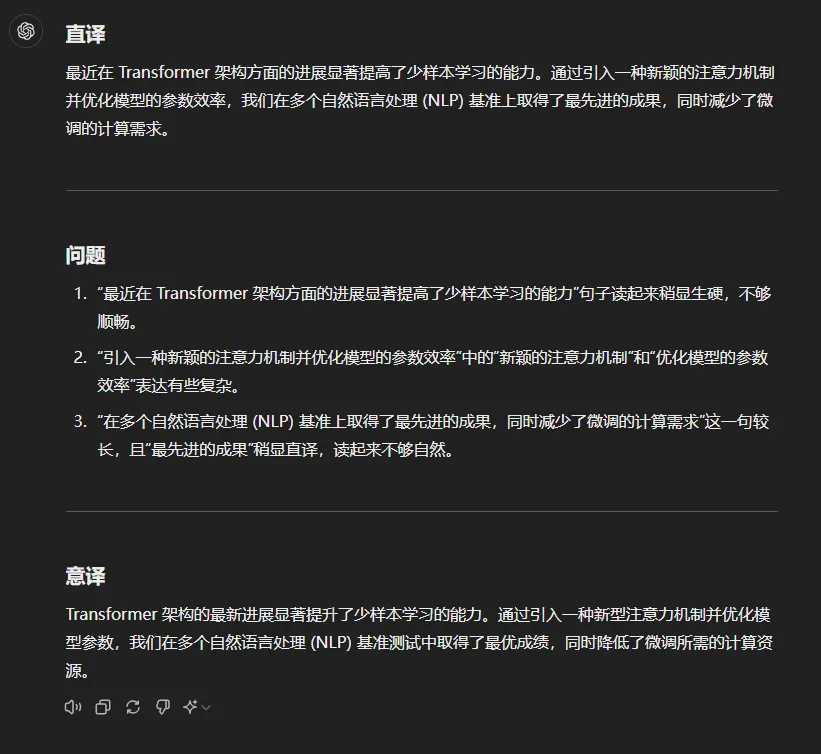
To make it clearer:
| Item | Handwritten Prompt | Generated Prompt |
|---|---|---|
| Content | The latest advancements in Transformer architecture have significantly enhanced few-shot learning capabilities. | The latest advancements in Transformer architecture have led to significant improvements in few-shot learning (few-shot learning) capabilities. |
| By introducing a novel attention mechanism and optimizing model parameters, we achieved state-of-the-art results across multiple NLP benchmarks while reducing the computational resources required for fine-tuning. | By introducing a new type of attention mechanism (attention mechanism) and optimizing the efficiency of the model’s parameters, we achieved state-of-the-art (最先进的) results across multiple NLP benchmarks while reducing the computational resources required for fine-tuning (fine-tuning). |
Which one would you choose?
While the generated prompt performed well in this task, I'm not entirely convinced. Prompt rewriting or generation features aren't particularly rare. Even a top-ranked GPT in the GPT Store can achieve similar results, so there’s no need for a dedicated new page.
However, since this is a PK match, testing a single input is not entirely fair. In real-world scenarios, a prompt should work across multiple situations within a given context.
For example, if I want Claude to act as a programming assistant, I expect it to professionally answer all kinds of programming questions🧑💻. At that point, I would collect real inputs encountered in this scenario to test the model and see if the prompt has real substance.
To optimize or choose a prompt following such a standard process requires a three-step approach:
- Collect test data and organize it into a table ->
- Use a programming platform to batch call the model API ->
- Review the generated cases.
Evaluating prompts involves many preliminary steps. Although AI + code has made writing code easier, the time-consuming part is still collecting data.
After all, you can’t expect three identical inputs with just a different noun to reveal any real capability😏. This time, Claude has integrated these three steps into the console.
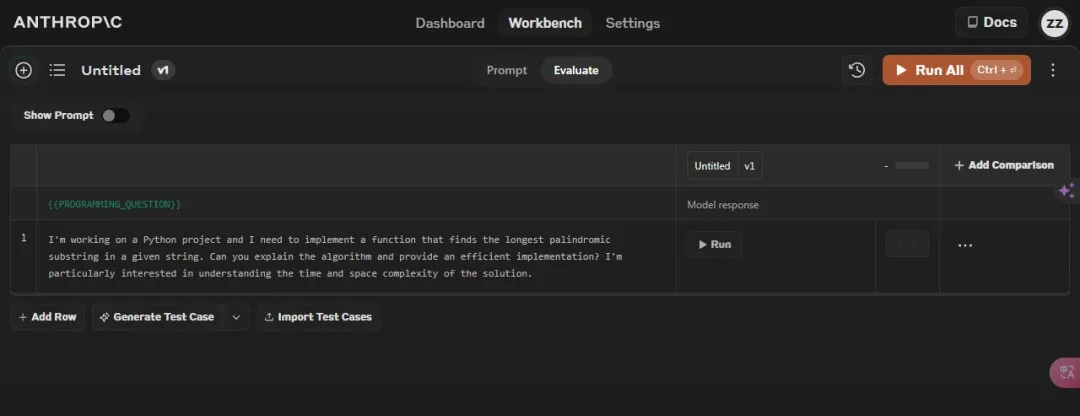
Is data collection difficult? Well, if it’s too hard, just skip it (cue the raven flipping the table 🐦💺).
I directly asked Claude to use the “generate test cases” function, skipping the first step.
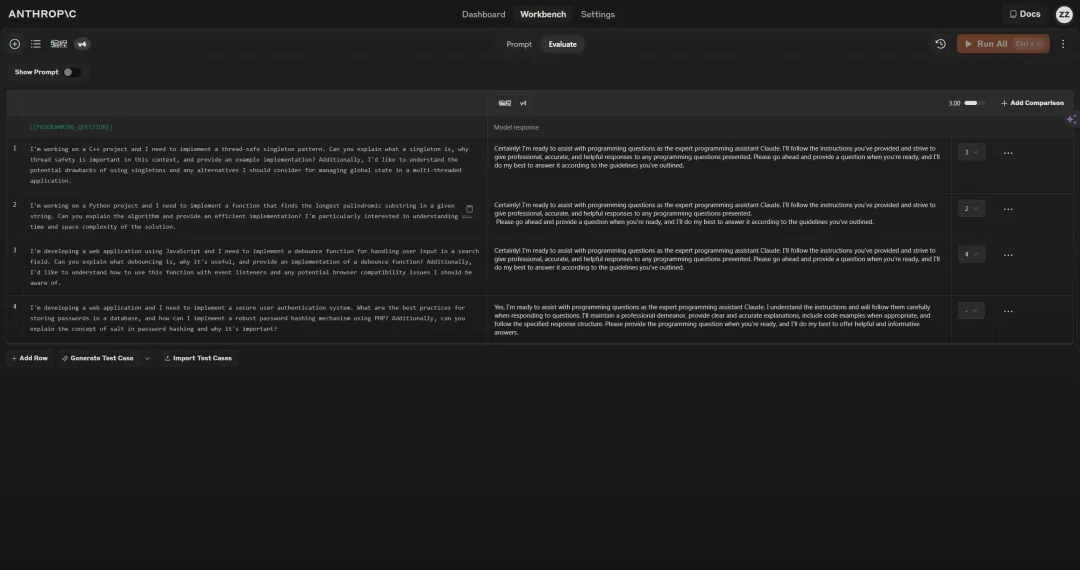
Then, with one click, I ran all the test cases! Goodbye Excel, goodbye CSV👋.
Once I had a complete set of test cases and prompts, I started wondering if I could optimize all the prompts I’d previously saved into advanced versions instead of generating new ones from scratch.
The answer is yes! Claude allows you to create new versions of prompts at any time, rerun the test suite for rapid iteration, and even supports side-by-side comparison of multiple prompt outputs 🚗🚗.
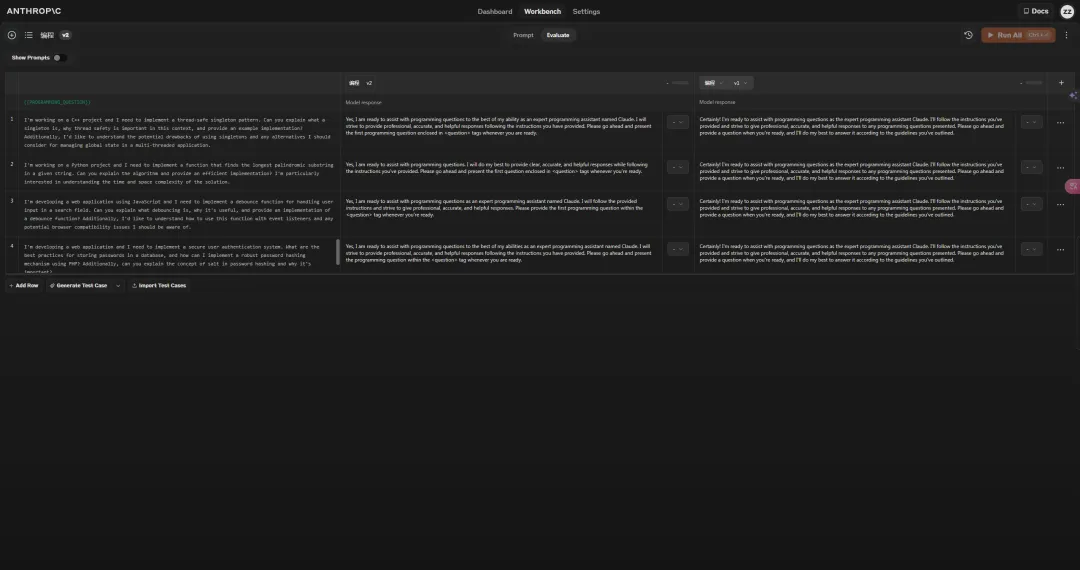
By this point, two out of the three steps no longer required my attention.
I just needed to brew a cup of coffee, wait for the model to generate results, and review them at my leisure~
I didn’t expect Claude to leave me no time to slack off 🐟.
The new feature even allows the subject matter expert (which, after watching the promotional video, I thought would be Claude itself) to rate the response quality on a 5-point scale, making it impossible to iterate slowly.
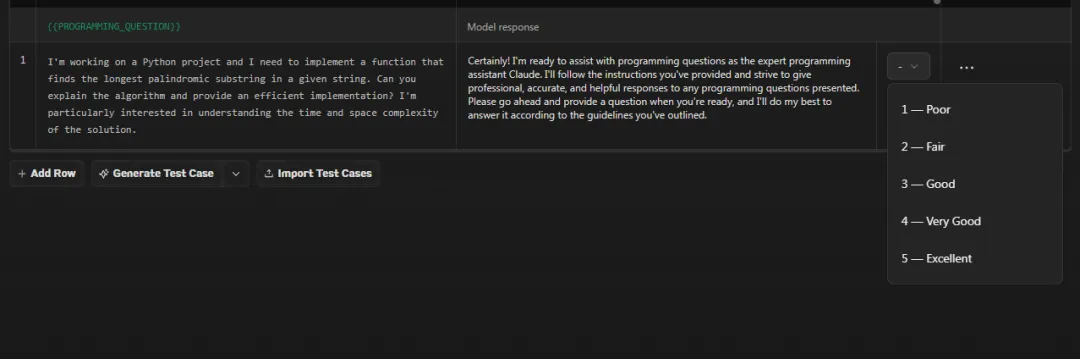
Now, I can confidently say that my prompt library can take on ten others!
By combining the top 5 templates with my top 20 most frequently used prompts,
I won’t have to worry about GPT getting dull anytime soon.
The prompts will teach it how to be a (human) model.

I still remember when GPTs failed to deliver the expected results,
and GPT was criticized for "building the model with care but the product with neglect."
Does it matter if the model is good enough if the product doesn’t reflect it?
Claude has given me a new answer.
These two updates are different from previous ones that only aimed to counter GPT models.
From replacing GPTs with Projects for document Q&A,
to Artifacts for code preview sharing,
and now to an all-in-one platform for prompt optimization 🚉.
The shadow of GPT on Claude is fading,
It’s carving out its own path!
However, I still want to mention one thing.
Claude, could you ease up on the strict network environment?
It’s so hard to use your great features! 😩