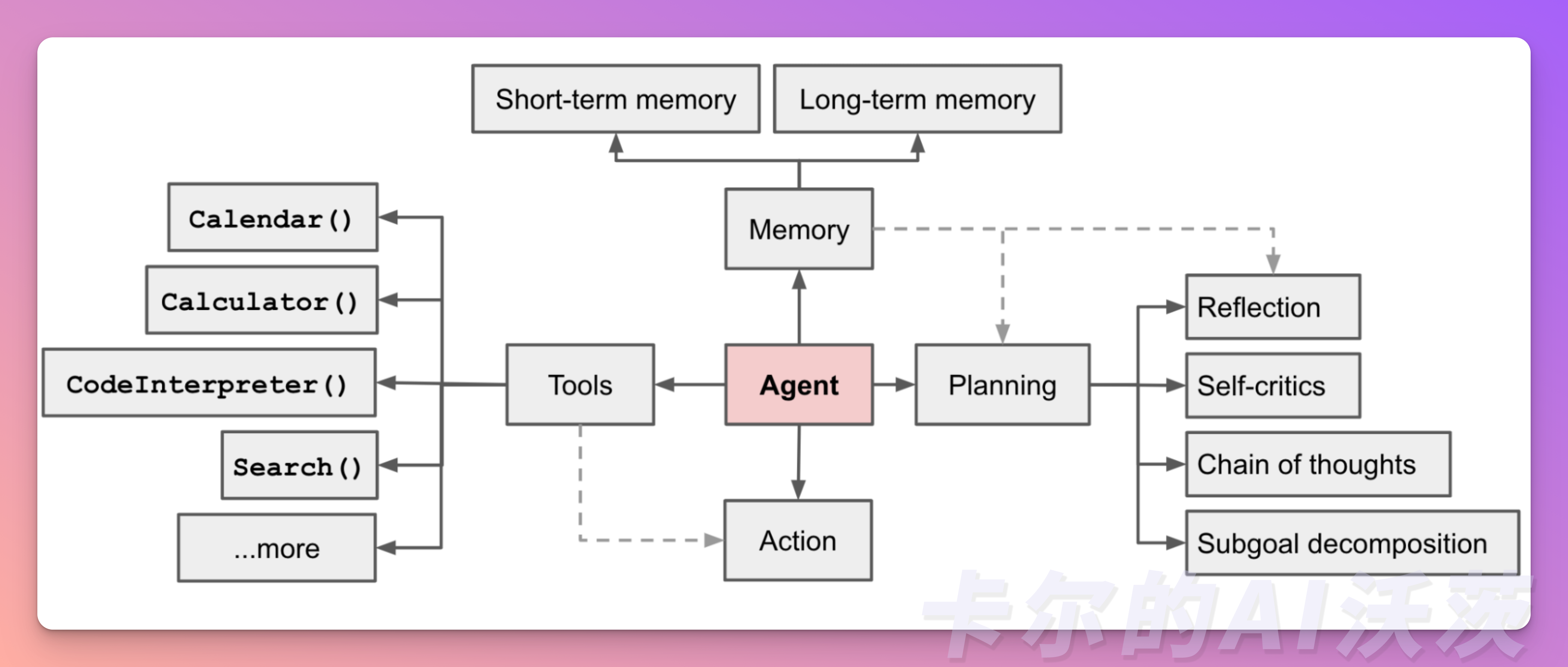
🟢 Detailed Explanation of Agents Components
In an LLM-driven Agent system, the LLM acts as the brain of the Agent and is supplemented by several key components:
- Planning: The LLM can perform comprehensive planning, not just simple task decomposition. It can evaluate different paths and strategies, formulating the best action plan to achieve the goals set by the user.
- Memory: The LLM has memory capabilities, enabling it to store and retrieve past information and experiences. This allows it to leverage previously learned knowledge and experiences when handling user queries, providing more accurate and personalized answers.
- Tool Usage: The LLM is proficient in using various tools and resources, flexibly utilizing them to support task completion. It can employ search engines, databases, APIs, and other tools to gather and organize relevant information to meet user needs.
🎉Before you start reading, if you are interested in other articles, visit our welcome page and follow us! "Karl's AI Watts" is an open-source Chinese community that provides real-time updates and the latest tutorials.🎉
Component 1: Planning
- Sub-goals and Decomposition: Agents break large tasks into manageable sub-goals, effectively handling complex tasks.
- Reflection and Improvement: Agents critique and reflect on past actions, learning from mistakes and improving future steps to enhance the final outcome.
Handling complex tasks often requires multiple steps. To better organize and plan, the Agent needs to clarify the specific content of the task and start planning in advance.
Task Decomposition
- Chain of Thought (CoT) has become a standard prompting technique to enhance model performance on complex tasks. Instructing the model to think step by step breaks difficult tasks into smaller, simpler steps. CoT focuses on the interpretability of the model's thinking process, making it more manageable to handle challenging tasks.
- Tree of Thoughts extends CoT by exploring multiple reasoning possibilities for each step. It first breaks down the task into multiple thinking steps and generates multiple ideas for each step, creating a tree structure. You can search the Tree of Thoughts using breadth-first search or depth-first search and determine each state based on classifiers or majority voting.
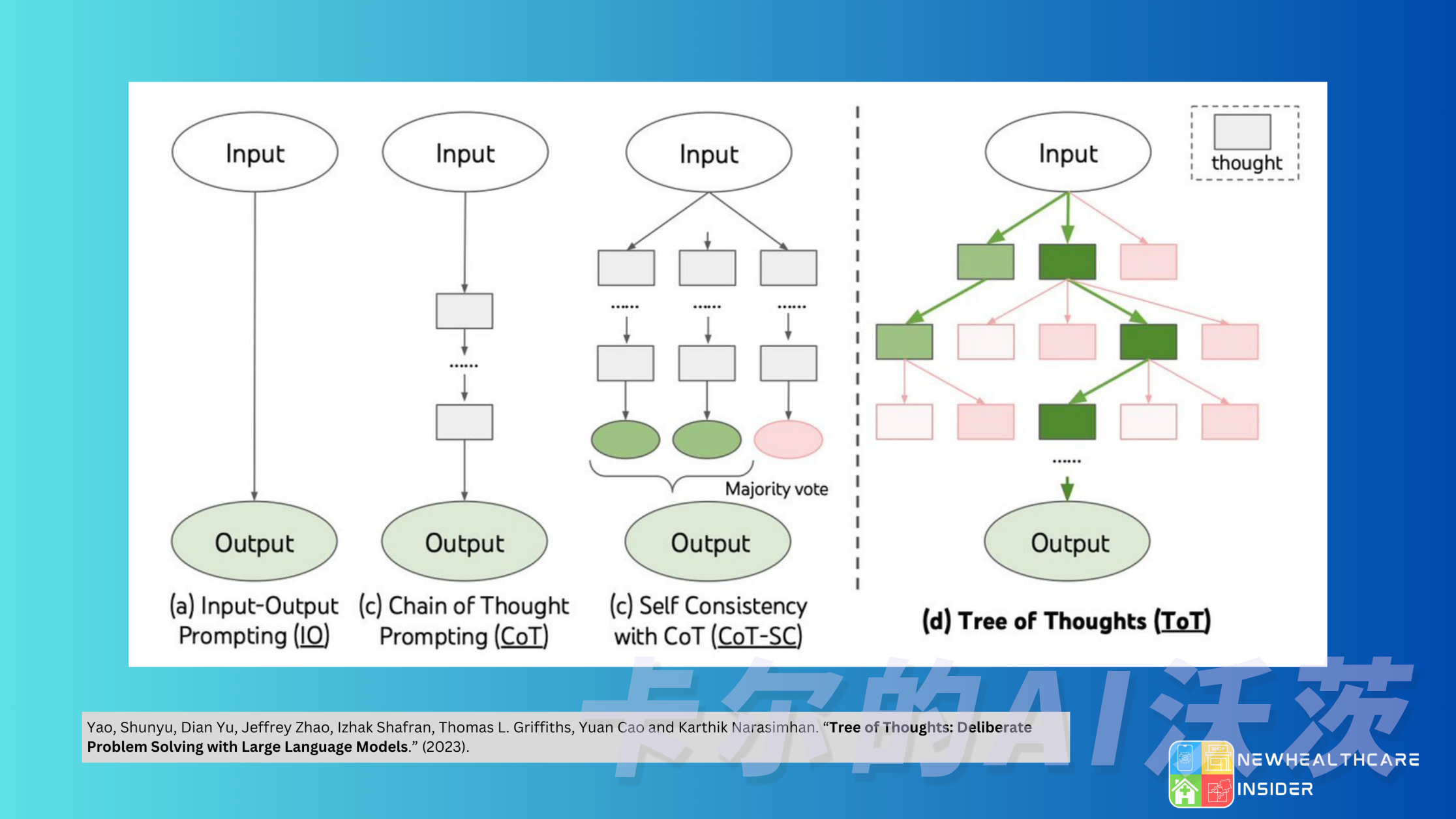
Through the above methods, you can decompose tasks in three ways:
- Use simple prompts to guide the LLM in decomposition, such as "Steps to achieve A," "What are the sub-goals to achieve A?"
- Use specific task instructions, such as "Write a story outline" for novel writing.
- Decompose and plan tasks yourself, such as extracting information first, then generating content when writing scripts.
Reflection
In real tasks, trial and error are inevitable, and self-reflection plays a crucial role in this process. It allows the Agent to iteratively improve by refining past action decisions and correcting previous mistakes.
Reflection results from the Agent's higher-level, more abstract thinking about things. Reflection is generated periodically when the sum of the importance scores of the latest events perceived by the Agent exceeds a certain threshold. This can be likened to the common Chinese idiom "Think thrice before you act," where we reflect on our previous decisions when making major decisions.
ReAct
ReAct is a technique that integrates reasoning and action by combining the action space with the task-specific discrete actions and the language space in the LLM. Simply put, task-specific discrete actions allow the LLM to interact with the environment (e.g., using the Wikipedia search API), and language space prompts the LLM to generate reasoning tracks in natural language.
The ReAct prompt template includes explicit steps of LLM thinking, with a general format as follows:
Thought: ...
Action: ...
Observation: ...
... (Repeated many times)

The difference between ReAct and CoT: CoT simply adds a static "Let’s think step by step" to the prompt, while ReAct's prompt is dynamically changing.
Reflexion
Reflexion is a framework that provides Agents with dynamic memory and self-reflection capabilities to improve reasoning skills. Reflexion adopts a standard reinforcement learning setup, rewarding the model with simple binary rewards (i.e., judging whether actions are correct or not), while the action space follows the setup in ReAct, enhancing task-specific action space with language to increase complex reasoning steps. After each action, the Agent calculates a heuristic value and decides whether to reset the environment to start a new trial based on the self-reflection results.

Heuristic functions are used to judge when the LLM's action track starts to be inefficient or contains hallucinations and stop the task at this moment. Inefficiency means spending a lot of time but not finding a successful path. Hallucination is defined as the LLM encountering a series of consecutive identical actions that lead the LM to observe the same result in the environment.
Note that this is different from the general hallucination of large models, where the large model outputs a series of seemingly logical but actually incorrect or non-existent false facts.
Component 2: Memory
- We can view context learning as utilizing the model's short-term memory (i.e., the maximum length of input the model can accept) to learn.
- Long-term memory provides the Agent with the ability to store and recall information over the long term, usually achieved through external vector storage and fast retrieval.
Memory refers to the process of acquiring, storing, retaining, and subsequently retrieving information. There are various types of memory in the human brain:
- Sensory Memory: This is the earliest stage of memory, providing the ability to retain impressions of sensory information (visual, auditory, etc.) after the original stimuli have ended. Sensory memory typically lasts only a few seconds.
- Short-Term Memory (STM) or Working Memory: It stores information that we are currently aware of, used for performing complex cognitive tasks such as learning and reasoning. The capacity of short-term memory is usually about 7 items and lasts for 20-30 seconds.
- Long-Term Memory (LTM): Long-term memory can store information for a long time, from days to decades, with virtually unlimited storage capacity. Long-term memory has two subtypes:
- Explicit/Declarative Memory: Refers to memory of facts and events that can be consciously recalled, including episodic memory (experiences) and semantic memory (facts and concepts).
- Implicit/Procedural Memory: This memory is unconscious, involving skills and routines that are automatically performed, such as riding a bike or typing.

For Agents:
- Sensory memory serves as raw input, which can be text, images, or other modalities.
- Short-term memory is used for context learning. It is transient and limited because it is constrained by the limited context window length of the Transformer.
- Long-term memory is accessed by the Agent through external vector storage and fast retrieval.
Memory Stream and Retrieval
The Memory Stream records all experiences of the Agent. It is a list of memory objects, each containing a natural language description, a creation timestamp, and a recent access timestamp. The basic element of the memory stream is Observation, which is the event directly perceived by the Agent. Observations can be actions performed by the Agent itself or actions perceived by the Agent performed by other Agents or non-Agent entities. Each Agent has its independent memory stream.
The retrieval function extracts a portion of memory from the memory stream based on the Agent's current situation for the language model to use. The sorting and scoring include three aspects:
- Recency: More recent memory objects receive higher scores, so recent events or events from this morning are likely to be more prominent to the Agent. Recency is measured using an exponential decay function with a decay factor of 0.99, based on the time since the last memory retrieval.
- Importance: Memory objects are assigned different scores based on their perceived importance by the Agent, distinguishing between ordinary memories and core memories. For example, mundane events (like having breakfast) receive low importance scores, while significant events (like a meeting with an important person) receive high scores. Importance scores can be implemented using various methods, similar to solutions that output an integer score using a specific scoring model.
- Relevance: Memory objects more relevant to the current situation are assigned higher scores. Relevance evaluation is implemented using common vector retrieval engines.
Component 3: Tool Usage
Agents can learn to call external APIs to obtain additional information missing from the model weights, including current information, code execution capabilities, and access to proprietary information sources. This is crucial for model weights that are difficult to modify post-training.
Mastering the use of tools is one of the most unique and important traits of humans. We break through our physical and cognitive limitations by creating, modifying, and utilizing external tools. Similarly, we can provide external tools to language models (LLMs) to significantly enhance their capabilities.
MRKL (Modular Reasoning, Knowledge, and Language) is a neuro-symbolic architecture designed for autonomous Agents. The MRKL system contains a set of "expert" modules, and the LLM sends queries to the expert module it deems most suitable. These modules can be neural modules (such as deep learning models) or symbolic modules (such as mathematical calculators, currency converters, weather APIs).
TALM (Tool Augmented Language Models) and Toolformer fine-tune language models to learn to use external tool APIs. These datasets are created based on whether adding external API call annotations can improve the quality of model outputs. The collection of tool APIs can be provided by other developers (as in the case of plugins) or customized (as in the case of function calls).

ChatGPT plugins and OpenAI API function calls are the best practical examples of LLMs with tool usage capabilities.
Example👏
Suppose there is an Agent that assists with research, and we want to get the latest news summary about Twitter:

- We tell the Agent, "Your goal is to find the latest news about Twitter and send me a summary."
- The Agent reviews the goal and uses AI like OpenAI's GPT-4 to understand the task. It proposes the first task: "Search Google for news related to Twitter."
- The Agent searches Google for Twitter news, finds top articles, and returns a list of links. The first task is completed.
- Now, the Agent reviews the main goal (get the latest news about Twitter and send a summary) and what it has just completed (obtained a series of news links about Twitter) and decides what its next task needs to be.
- It proposes two new tasks: 1) Write a news summary. 2) Read the content of the news links found on Google.
- Before continuing, the smart assistant pauses to ensure these tasks are correctly arranged. It reflects on whether it should write the summary first. However, it decides the primary task is to read the content of the news links found on Google.
- The Agent reads the article content, then reviews the to-do list again. It considers adding a new task to summarize what it has read but finds this task is already on the to-do list, so it does not add it again.
- The Agent checks the to-do list, with only one task remaining: writing a summary of the content read. So, it performs this task and sends you the summary as requested.
I believe you now understand how Agents work! Follow 「卡尔的AI沃茨」for more insights.
Next, we will introduce eight top Agent projects that play significant roles in different fields!