🟢 I Created 100 Shots with Zhipu’s "Qingying"—Sora Users, Brace Yourselves!
I opened my video app this morning and saw Zhipu was live streaming. Expecting to see a new version of GLM-4, I was instead greeted by a surprise: Zhipu had unveiled their new video creation agent, "Qingying," powered by the CogVideoX model.
CogVideo rang a bell, and after a quick check, I realized that it had released its code two years ago. Back then, it was the largest general-domain text-to-video generation pre-trained model with 9.4 billion parameters.
Here’s what its output looked like back then:

And here’s what it looks like now:


Fast forward to the present—while Sora is still nowhere to be seen, with AI video generation tools evolving at a daily pace, Zhipu’s launch feels like a breath of fresh air:
- Full release, no need to wait for a closed beta
- Supports both text-to-video and image-to-video generation
- Available across multiple platforms (PC/APP/Mini Program)
Everything seems spot on ✅, and it’s super easy to use:
On mobile, open Zhipu Qingyan -> Homepage to find Qingying -> Click the blue text to enter the usage interface.
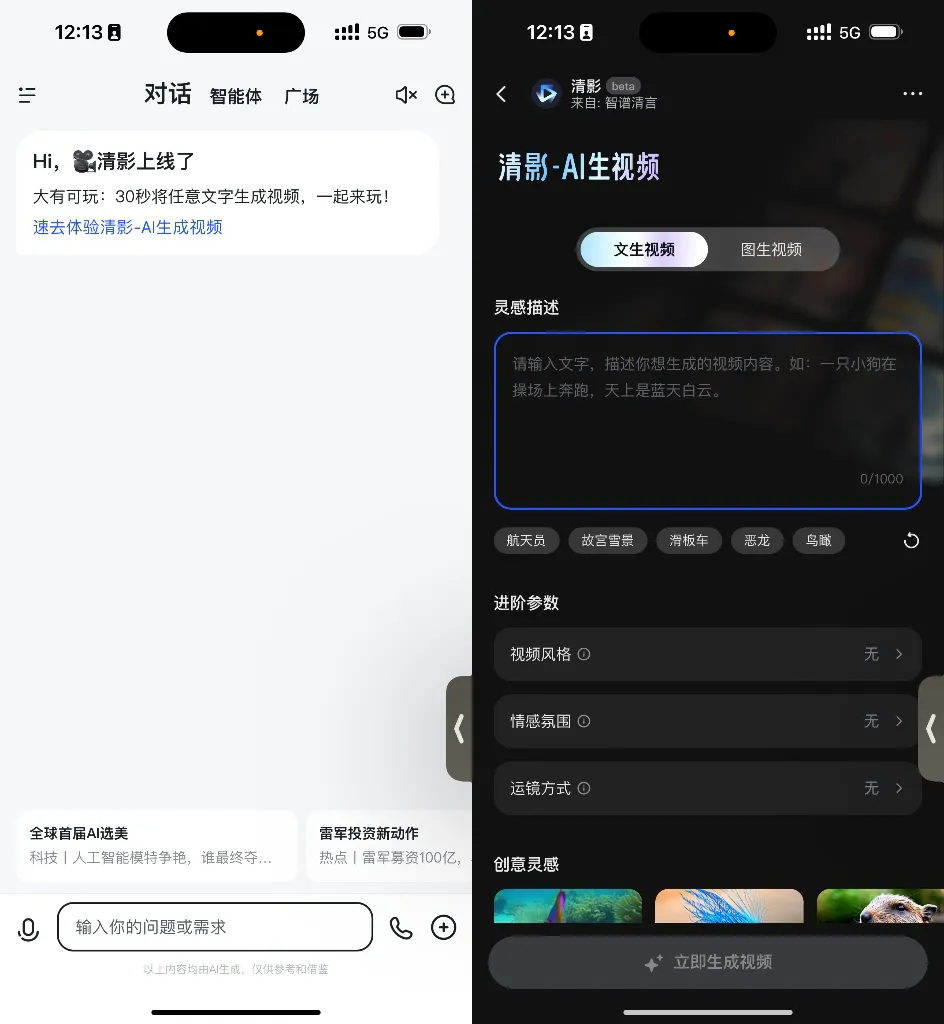
And that's it—no more long waits ⌛️.
Recently, I’ve been working on two projects simultaneously and was struggling with software limitations:
- KLing takes two hours to generate a single shot after its full release.
- Luma is always reliable but slow.
- Gen3 has always been quite expensive.
For a first-generation product, my expectations for Qingying were modest—just making it into my top three choices for shot generation would be enough to keep me eagerly awaiting its updates.
Let's start with the parameters: Qingying supports 1440x960 6-second videos, which is on par with other major players.
However, a few shots aren't enough to capture everyone’s favorite video styles.
So this time, I picked the most popular and widely shared videos from Runway, Luma, and Kling over the past month, categorizing them into:
- Realistic Shots
- Animation Styles
- Sci-Fi & Fantasy
- Multi-Person Scenes
- Meme Characters
Now that we have categories, we just need the prompt suggestions for testing.
Previously, this was GPT's job, but now the Zhipu Qingyan agent has taken over. Input a scene description + content description, and you get a prompt. Let’s compare the prompts before and after the agent enhancement:
Before Enhancement: "An elderly woman cooking in the kitchen, with various kitchen utensils and ingredients in the background, creating a warm atmosphere."
After Enhancement: "Close-up shot following an elderly woman cooking in the kitchen, with the warm evening light shining on her face, giving her a particularly kind expression. She’s dressed in casual home attire, surrounded by neatly arranged kitchen utensils and fresh ingredients, filling the entire kitchen with a warm and lively atmosphere. The colors are vibrant, with rich details and 4K high-definition quality, making you feel the warmth of home."
I used the Runway video prompt formula for quality comparison:
[Camera Language] + [Lighting] + [Subject (Subject Description)] + [Subject Movement] + [Scene (Scene Description)] + [Mood/Atmosphere/Style]
It has all the necessary elements, so it looks like the prompt work can safely be entrusted to it. After generating over a hundred prompts with Qingyan, ATang and I jumped right into testing!
(Note: The test cases mentioned below include our personal tests and Zhipu's official demo videos, provided for reference and comparison.)
Since we can’t include all the videos in this article, all cases are available on Feishu—just reply "Qingying" in the comment area at the bottom to get it.
Realistic Shots
Realistic style has become a must-test style for AI-generated video testing. Generally, I look at how well it captures facial expressions, animal movements, and lighting changes in the scenery.
To clearly demonstrate the comparison between text-to-video and image-to-video effects, this review tests both types of video generation under each style.
Let's see what Qingying can do!
Text-to-Video: Characters
Close-up shot, warm golden sunlight, a young woman with vibrant red hair and a whimsical green leaf crown gazes softly with awe off-camera. The background is warm light and dancing messy hair, creating a dreamy and cozy atmosphere.

Close-up shot, harsh red light on an old man's face, his weathered features filled with fear and shock. The background is deep shadows and blurred details, creating a dramatic and tense atmosphere.

The light and movement depiction for characters is decent, though the emotional expression is still a bit lacking. However, considering it's AI, it's pretty commendable.
Image-to-Video: Characters
The wind blows through a girl's hair as she looks sadly ahead.

A woman blinks, her eyes reflecting beautiful shifting light.

In image-to-video, the imagination and completion are decent. The girl's hair flows naturally, and the eyelid details are well-rendered. However, compared to text-to-video, the dynamic effect is slightly weaker.
Text-to-Video: Animals
Realistic depiction, close-up, a cheetah lies sleeping on the ground, its body slightly rising and falling.

Two red pandas sit in a bamboo forest eating apples, extreme close-up, documentary style.

The realistic depiction of animals is very detailed—the cheetah's ears twitch, and the pandas’ adorable expressions are well-captured, except for the suddenly disappearing apples, haha.
Image-to-Video: Animals
A fish swims in a colorful underwater world.

A cute little creature hops forward.
In image-to-video, there are still some limitations in the model's imagination. For example, the movement of the unfamiliar creature above is a bit jerky, while the familiar fish swimming effect is much better, with detailed depictions of bubbles and more.
Text-to-Video: Scenery
High-angle shot, bright noon sunlight, a bustling street under a city skyline, with skyscrapers and a steady stream of vehicles in the background, creating a busy and modern atmosphere.

Mid-shot, under bright daylight, a huge rock dynamically falls into a lake, with ripples spreading and water splashing, creating a dramatic and natural atmosphere.

The realistic cityscape is well-done, especially the reflections on building glass and the dynamic traffic flow. The stone falling into the water with splashing water effects also looks quite realistic.
Image-to-Video: Scenery
A man slowly walks forward as the sun gradually rises in the distance.

The sun slowly rises, a time-lapse of a sunrise.

In image-to-video, the handling of the character's movement in the landscape is quite natural, with interaction even with the grass around the legs. The second image's time-lapse portrayal of the sunrise is also good, though the layering of trees is slightly noticeable.
Conclusion: Overall, Zhipu Qingying's performance in realistic style meets our expectations—it’s well-executed and has a good understanding of natural language. You can achieve decent dynamic effects in just a couple of tries. The comparison between text-to-video and image-to-video also aligns with the general consensus: text-to-video is superior in dynamics.
Animation Style
Animation style is another must-test comparison with realistic style! This time, we tested effects across commonly used styles like Pixar and classic 2D animation.
Text-to-Video: Characters
Close-up shot, soft night lighting, a cartoon girl drawing in her bedroom, with toys and books in the background, creating a warm and childlike atmosphere in a daily life anime style.

Image-to-Video: Characters
A woman with a frightened expression.

The portrayal of characters in animation style was surprising. The daily animation style leaned more toward children’s picture book 2D animation, which would likely benefit from more specific style keywords. The image-to-video output had more exaggerated character dynamics than expected, but the emotional expression was spot-on—it was genuinely frightening.
Text-to-Video: Animals
Animation scene, showing a pink fluffy little monster holding a large piece of cheese and eating it, in 3D style, with attention to detail. The little monster's expression is full of joy, exuding a mischievous and innocent vibe. Warm colors and ambient lighting.

A mushroom transforms into a bear.

Image-to-Video: Animals
A small cat wags its tail and walks away.

The portrayal of animals in animation style was also impressive. The expressions of anthropomorphic animals and the natural transformation of the mushroom into a bear were well-done. The image-to-video of the cat's movements was smooth, and the background didn’t glitch.
Text-to-Video: Scenery
High-angle shot, under the starry night sky, a magical town is fully visible, with twinkling stars and brightly lit houses in the background, creating a dreamy and mysterious atmosphere in a fantasy anime style.

Wide-angle shot, under the bright midday sun, a fantastical garden filled with various magical plants and fairies, creating a vibrant and wondrous atmosphere in Pixar style.

Image-to-Video: Scenery
The wind blows, birds fly by, clouds drift across the sky.

A gentle breeze causes the lotus flowers in a pond to sway slightly.

In animation style scenery, I personally preferred image-to-video over text-to-video. The control over the desired style in the image was easier to achieve. Although the first image's depiction of birds was a bit lacking, the second one’s slight sway of the lotus flowers and water ripple effects were very well-done.
Conclusion: In the animation style, text-to-video requires more specific style constraints in the prompt to achieve the desired animation effect. Compared to realistic style, animation style is indeed better suited to image-to-video.
Sci-Fi & Fantasy
Sci-fi and fantasy styles were among the earliest and most frequent in AI-generated video works and remain some of the best-performing styles in most AI video generation tools. Testing this style primarily focuses on how well it handles lighting and special effects.
Text-to-Video
Mid-shot, neon lights of a futuristic city, a warrior in mechanical armor leaps between skyscrapers, with hovering vehicles and high-speed trains in the background, creating a tense and high-tech atmosphere.

Low-angle upward movement, slowly lifting the head, a dragon suddenly appears on top of an iceberg, then charges toward you as it spots you. Hollywood movie style.

Image-to-Video
An astronaut plays guitar in space, weightlessness, Christopher Nolan style.

No prompt, cyberpunk beauty.

A mage casting a spell in the waves, with jewels gathering the seawater and opening a magical portal.

Conclusion: There’s not much to add about the sci-fi and fantasy styles—they’ve been tested exhaustively with many video tools. Zhipu Qingying’s depiction of action effects is quite impressive, especially in the last scene where the mage performs magic on the sea. You should try it with corresponding prompts—the effect is stunning. With this level of capability, there's no need for dedicated special effects in movies; just use AI (I don’t even want to mention those fantasy TV dramas...).
Multi-Person Scenes
Displaying multi-person scenes is often a weak point for AI-generated videos.
Many times, attempts to generate multi-person scenes result in overlapping and deformed characters, or the scene fails to generate altogether. This time, we tested Zhipu Qingying's text-to-video capabilities with multi-person scenes.
Wide-angle shot, at dawn on the battlefield, two armies face off, with battle flags waving and war drums thundering in the background, creating a tense and solemn atmosphere.

Low-angle shot, under cold night light, a medieval castle siege battle, with flying fire arrows and siege machines in the background, creating a tense and fierce atmosphere.

Conclusion: This is familiar—these scenes seem like they’ve been seen in various TV dramas, usually in the opening scenes explaining historical backgrounds... Zhipu Qingying's performance in multi-person scenes was surprisingly good; many people were present, but there was no overlap or merging. If a super-resolution feature is added, the effect would be even better.
Classic Iconic Scenes
Aside from the above styles we tested, there’s another popular AI video style recently—generating iconic scenes from classic films or memes. This mainly uses the image-to-video feature. We tried a couple with Qingying:
Tang Sanzang wearing sunglasses.

Zhen Huan and Meizhuang hugging.

Famous paintings come to life.

Final Thoughts
I can't fit everything into this article. If you want to see all the videos and corresponding prompts, follow my official account and message "Qingying" to get the Feishu document.
After testing over a hundred shots, I believe Qingying is a well-timed update.
From ChatGLM to GLM-4, Zhipu has taken only 10 months.
They’re either open-sourcing or on the road to open-sourcing. Building in Public takes great courage, but they seem unafraid.
AI video prompts still have a long way to go compared to AI-generated images. Writing too much can make the scene chaotic, while missing details can lead to wild outputs. This unpredictability is one reason AI-generated videos are often mocked as "gacha" games.
As a first version, Qingying has its flaws, but we can look forward to seeing how this honest player in the AI field evolves with GLM-4—how long will it take to surpass Sora?
Oh, and by the way, "Qingying" is a description of moonlight:
"Dancing with the Qingying, how could it be compared to the human world 🌛"