ChatTTS - A Generative Speech Synthesis Model for Conversations
终于蹲到ChatTTS增强版整合包,AI视频配角们有了自己的声音~
ChatTTS, a Generative Speech Synthesis Model for Conversations
The speech synthesis field is bustling with talent, frequently surprising us with significant innovations. From Bert-Sovit and GPT-Sovits to the recently skyrocketing ChatTTS, gaining over 10,000 stars in a week, these developments highlight the enthusiasm and recognition for voice synthesis technology. Today, let's experience the magic of ChatTTS!
Parameter Settings: Audio Seed = 42 | Text Seed = 42 | Other settings remain default
Input Text: Sichuan cuisine is indeed famous for its spiciness, but there are also non-spicy options. For example, Sweet Water Noodles, Lai Tangyuan, Egg Cake, and Ye'erba. These snacks are mild, sweet, and popular.
The generated voice has reached a level of realism. Interestingly, to limit the quality of the generated voice, the author added some high-frequency noise and compressed the sound quality during training, making it easier to distinguish. This was done to prevent the model from being used for fraud or other illegal activities. It seems the effect is so good that even the author is "afraid."
Besides the short 12-second audio, what other advantages and disadvantages does ChatTTS have?
- ✅ Conversational TTS: ChatTTS is optimized for conversational tasks, achieving natural and fluent speech synthesis while supporting multiple speakers.
- ✅ Fine-grained Control: The model can predict and control fine-grained prosodic features, including laughter, pauses, and interjections.
- ✅ Improved Prosody: ChatTTS surpasses most open-source TTS models in prosody and provides pre-trained models.
- ❌ Model Stability: The autoregressive model has stability issues, possibly causing sudden changes in voice or sound quality. Multiple attempts may be needed to find the best audio output.
- ⭕️ Emotion Control: The currently released model version's emotion control is limited to laughter ([laugh]) and some sound breaks ([uv_break], [lbreak]). The author plans to release more emotion control features in future versions.
A few days ago, we needed to set up environments locally and in the cloud to run ChatTTS, which was quite complex. Now, online websites and local integration packages have emerged. Here’s how to use them, starting with the website:
Visit ChatTTS website
In the author's examples, the mixed Chinese-English and prosody effects are impressive. Here, I’ll use these examples to teach you how to use them.
Input Text 1📕
These elements are actually glam rock, then add this bling feeling. I think like this jacket, for example, that oversized denim jacket, I think I can be an off-duty model.
Apart from the text and control symbols, the frequently adjusted parameter is Seed, which corresponds to different voices. Currently, no one has compiled a list of pleasant Seeds, but 2222 is quite popular.
Input Text 2📕
ChatTTS not only generates natural and fluent speech [uv_break] but also controls [laugh] laughter [laugh], [uv_break] pauses, and interjections [uv_break]. Its prosody surpasses many open-source models.
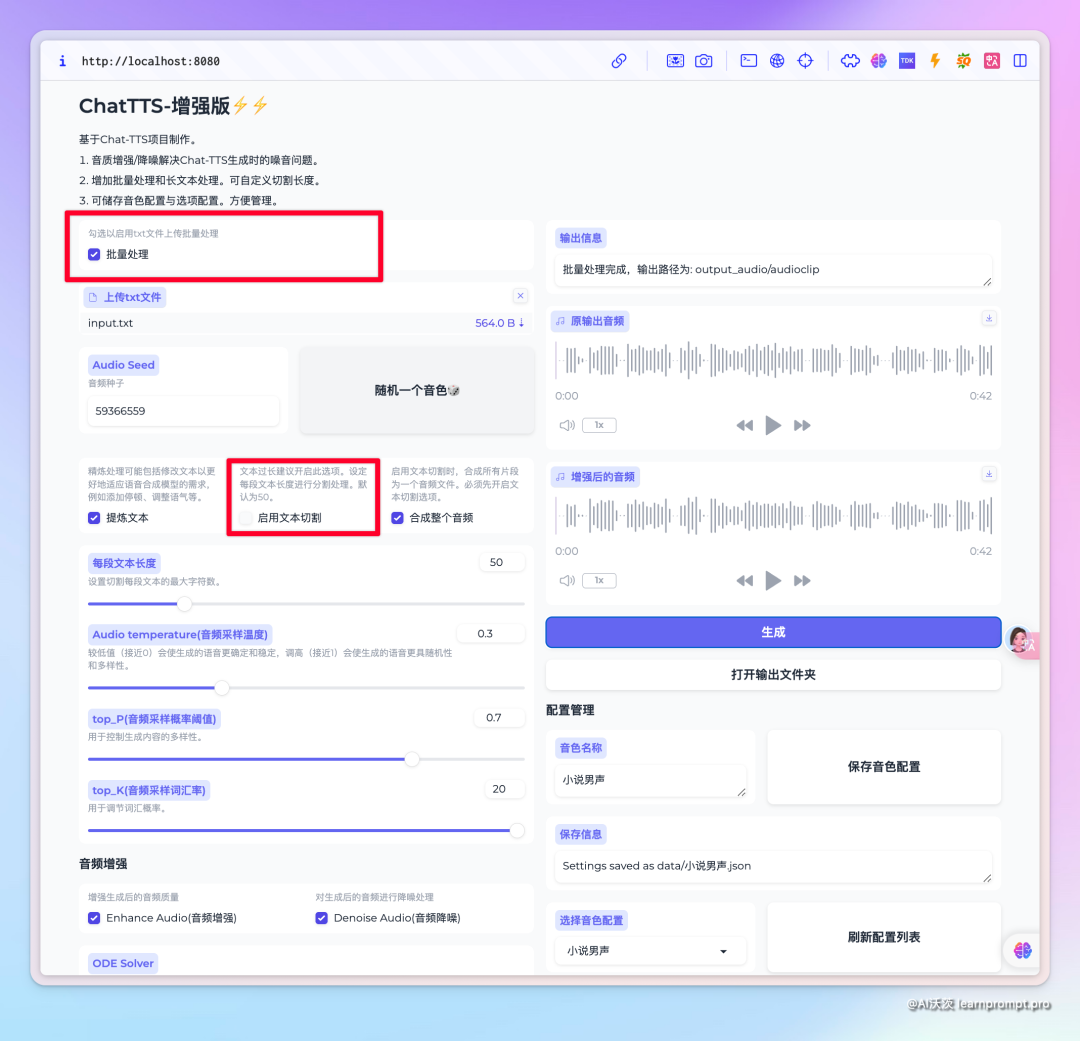
From the online experience, ChatTTS lacks modules like fine-tuning and long text at this stage. However, I found an integration package on Bilibili, which adds features like sound quality enhancement, batch processing, and long text segmentation, with versions for Mac and Windows.
Note on GPU requirements: For 30 seconds of audio, 4G of video memory is needed.
The integration package also has optimization points. The Mac version defaults to port 8080. After quitting the application, execute "lsof -i :8080" to get the PID of the program and kill it, otherwise, the next start will set the port as occupied.
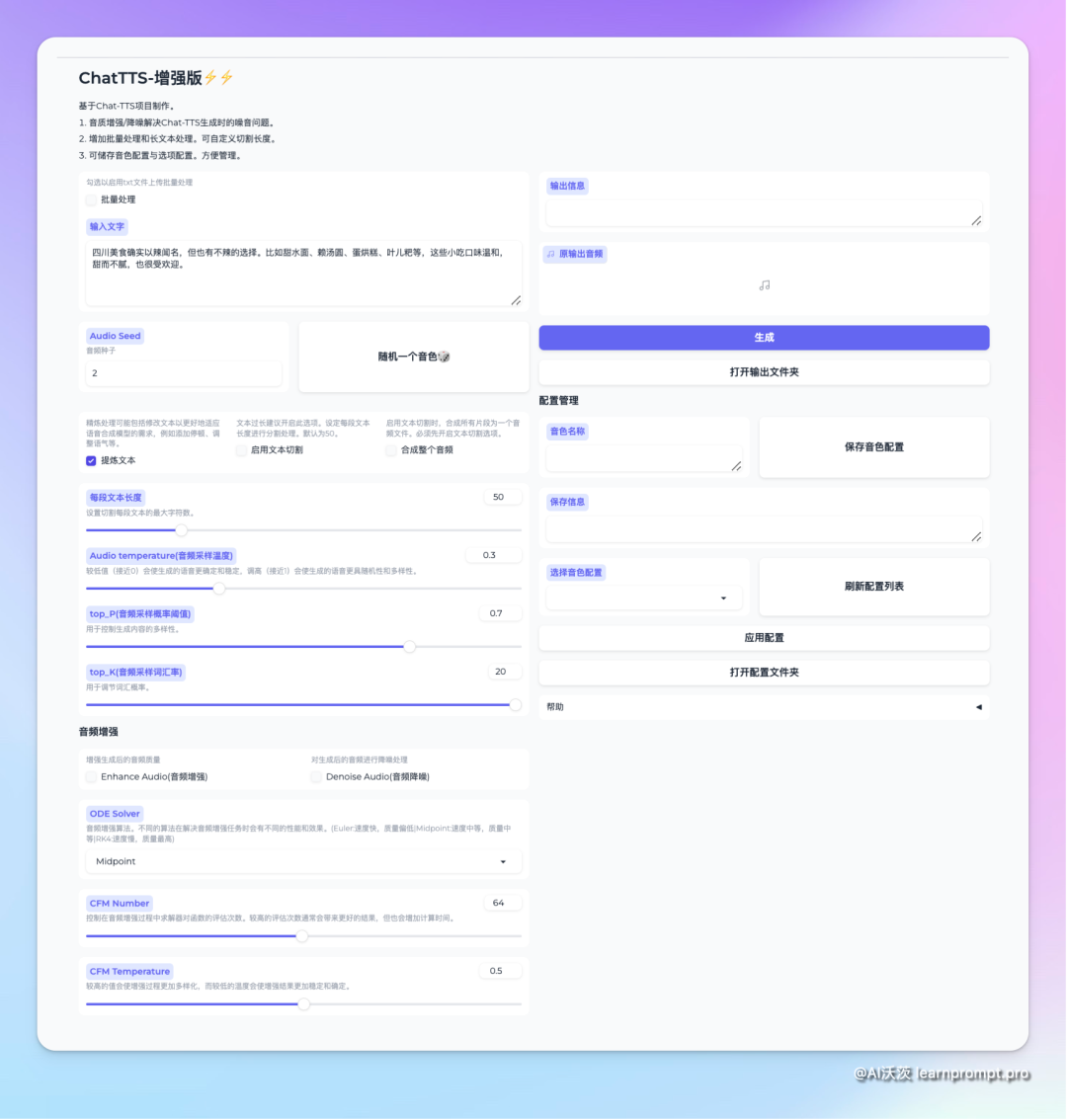
First, let's try enhancing sound quality. When preparing to generate audio, you can check the audio enhancement and noise reduction options for further processing. Enhanced audio will be clearer with reduced noise but will increase processing time⏰
Next, when there is a lot of text, you can check text segmentation for processing, defaulting to fifty characters per segment. You can also merge audio segments into one continuous audio. The segmented audio clips also support enhancement processing.
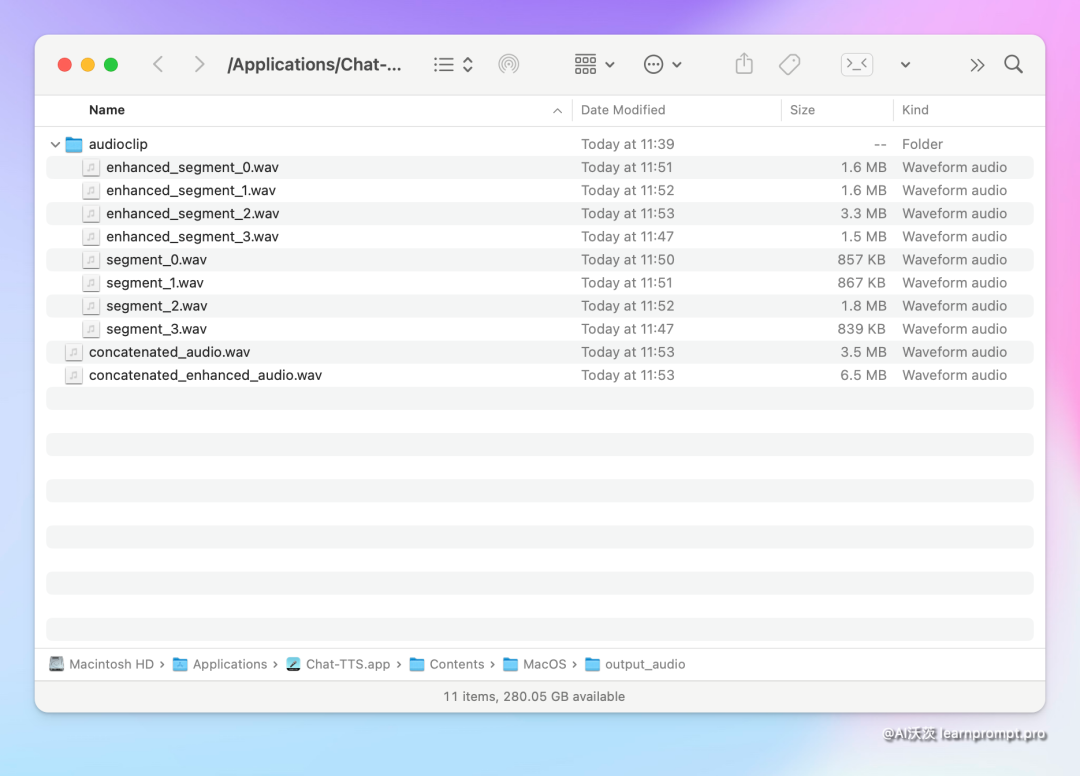
The saved audio file structure is quite clear,
- Concatenated Audio is the synthesized continuous audio, Enhanced Audio is the enhanced processed continuous audio
- Audio clip folder contains the segmented audio clips. Clips prefixed with Enhanced are the enhanced audio clips, while those without the prefix are the regular generated audio clips.
This version also adds a batch processing feature. After checking it, you can upload a TXT file, which needs to be formatted with each sentence on a new line.
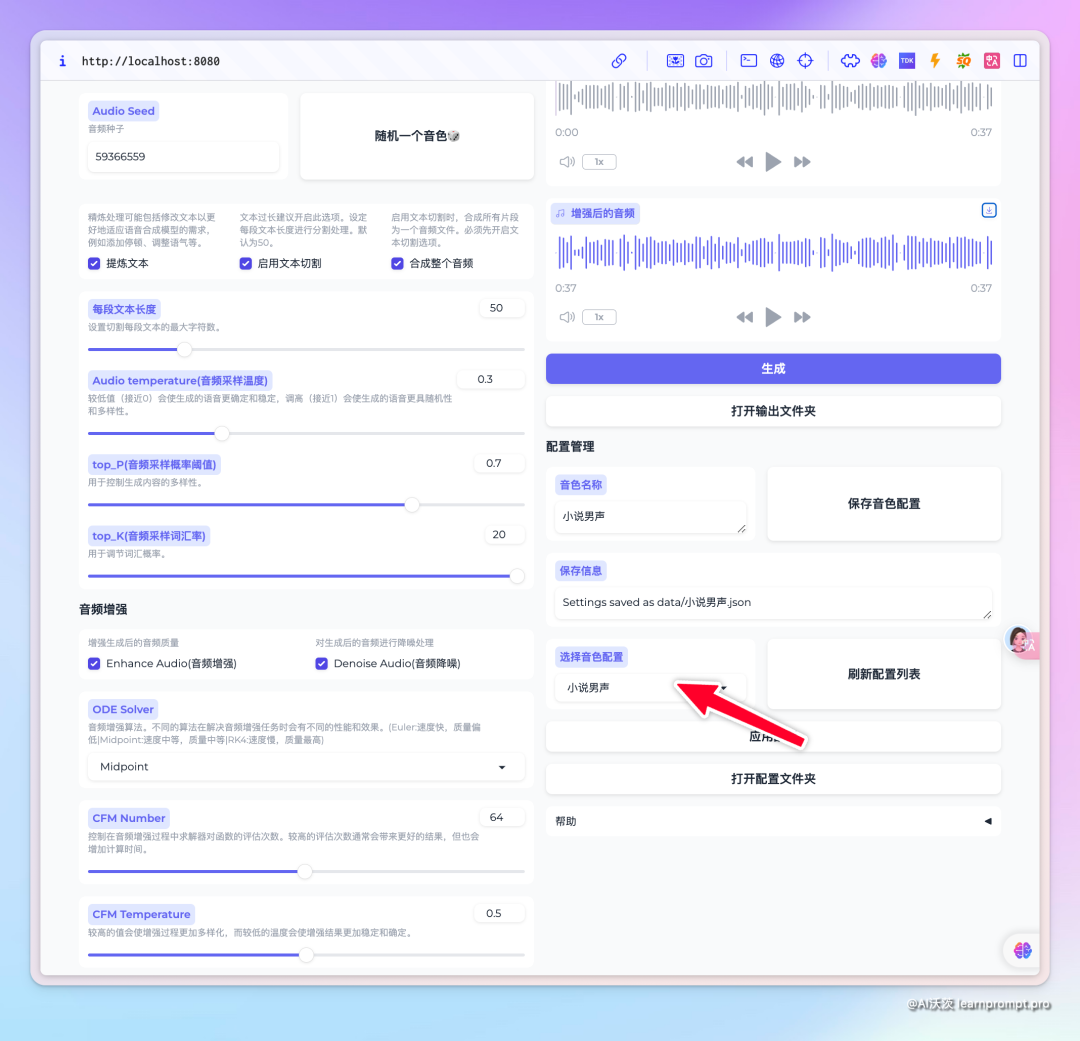
Finally, there's voice stabilization. Different audio seeds generate different character voice tones. By clicking the random button and trying several times, you can find a satisfactory tone. You can save the settings and voice seed to a configuration file for future use.
When ChatTTS was first released, I was amazed by its performance.
Then I reconsidered, given the current situation where the voice can only be randomly generated, what applications would it have in the AI voice-over field?
Originally, I planned to wait for a fine-tuned version to provide a tutorial on replicating celebrity voices.
But last night, while making an AI short film, I suddenly thought of the voice-overs in our videos,
Usually, there are narrators, supporting roles, and minor characters.
The 30-second voice supported by ChatTTS is actually quite sufficient for the current AI video length!
So, I wrote this article to share the current performance and my thoughts.
I believe I have unlocked the secret to using ChatTTS,
In the future, the characters in our AI videos will have their own voices🔊
📁 To facilitate download, reply [ChatTTS] on the official account to receive the integration package directly~