🟢 Tree of Thoughts
😀 For complex tasks that require exploration or strategic prediction, traditional or simple prompting techniques are not sufficient. Yao et al. (2023) proposed the Tree of Thoughts (ToT) framework, which is based on chain of thought prompting. This framework guides language models to explore thinking as intermediate steps to solve general problems.
ToT maintains a tree of thoughts, where thoughts are represented by coherent language sequences, which are the intermediate steps to solve problems. Using this method, the language model (LM) can evaluate the intermediate thoughts of a rigorous reasoning process. The LM combines the ability to generate and evaluate thoughts with search algorithms (such as breadth-first search and depth-first search), allowing forward validation and backtracking during systematic exploration of thoughts.
The principle of the ToT framework is as follows:
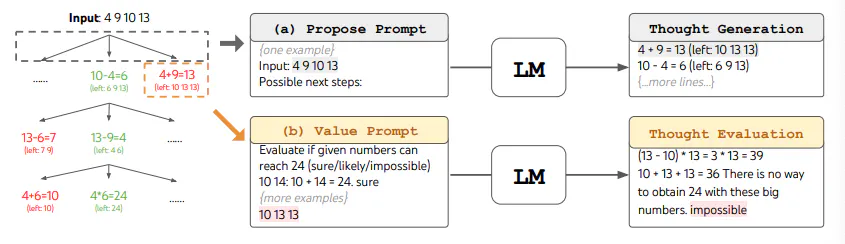
ToT requires defining the number of thoughts/steps and the number of candidates for each step for different tasks. For example, the "24 Game" in the paper is a mathematical reasoning task that needs to be divided into 3 thinking steps, with each step requiring an intermediate equation. For each step, the top 5 best candidates are retained.
To complete the 24 Game task, ToT performs a breadth-first search (BFS). Each candidate thought at every step is evaluated by the LM for whether it can reach 24: “sure/maybe/impossible.” The authors explain: “The goal is to obtain local solutions that can be verified as correct (sure) with minimal forward attempts, eliminate those that are impossible based on common sense of 'too big/too small,' and retain the rest as 'maybe'.” Each step's thoughts are sampled to obtain 3 evaluation results. The entire process is shown in the following figure:
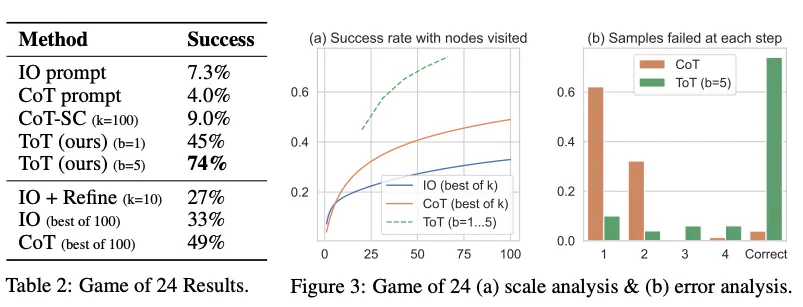
As reported in the figure below, the performance of ToT significantly surpasses other prompting methods:
On a broad scale, Yao et al. (2023) and Long (2023) share a similar core idea. Both methods enhance the LLM's ability to solve complex problems in the form of a multi-round dialogue search tree. The main difference is that Yao et al. (2023) adopts depth-first search (DFS)/breadth-first search (BFS)/beam search, while Long (2023) proposes a "ToT Controller" driven by reinforcement learning (RL) to guide the tree search strategy.
Depth-first/breadth-first/beam search are general search strategies that are not specific to particular problems. In contrast, a ToT Controller trained by reinforcement learning can potentially learn from new datasets or self-play (AlphaGo vs. brute force search). Therefore, even with a frozen LLM, a ToT system based on reinforcement learning can continue to evolve and learn new knowledge.
Hulbert (2023) proposed a prompting method for the Tree of Thoughts (ToT), summarizing the main concepts of the ToT framework into a brief prompt to guide the LLM to evaluate intermediate thoughts in a single prompt. An example of a ToT prompt is as follows:

Prompt
Assume three different experts are answering this question. All experts write down their first step in thinking about this problem and share it. Then, all experts write down their next step and share it. This continues until all experts have written all their steps. If anyone notices a mistake in an expert's steps, that expert leaves. Please...