🟢 RAG: 从理论到langchain实现
😀 原文
作者:Leonie Monigatti 转发:欣 推荐理由:浅显易懂,有代码样例
自从意识到专有数据可以用来增强大语言模型(LLMs)以来,关于如何最有效地补齐大模型中通用知识与专有数据之间gap的讨论一直存在。与此同时,人们也一直在争论微调和检索增强生成(RAG)哪个更适合这个目标(剧透:两者都有用)。
这篇文章首先聚焦RAG的概念,先介绍它的理论,然后演示如何通过LangChain编排、使用OpenAI语言模型和Weaviate向量数据库来实现一个简单的RAG流程。
一、什么是检索增强生成(Retrieval-Augmented Generation,RAG)
RAG就是给大语言模型额外补充一些外部知识。它的作用是能让模型生成更准确、更贴近上下文的答案,并减少幻觉。
问题背景
目前最先进的大语言模型通过大量数据训练,目的是在神经网络权重中储存广泛的通用知识(也叫参数记忆)。但是,当我们让大模型生成一些在它的训练数据中没有包含的知识,比如实时的、专有的,或者是特定领域的信息时,它可能会产生一些事实上不准确的回答(我们称之为幻觉),如下图所示:
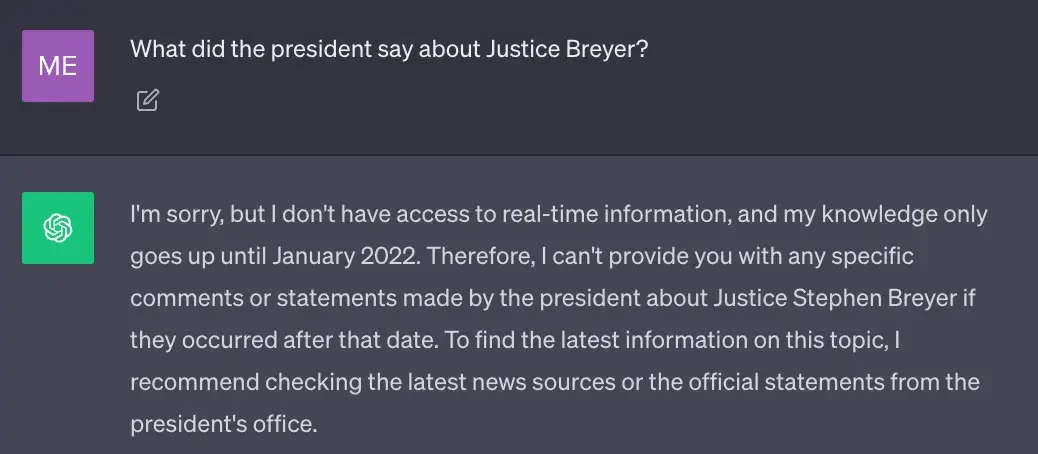
问题:总统对布雷耶大法官说了什么?从ChatGPT回答可以看出,它的训练数据最新知道2022年一月,所以无法回答这个问题
所以,要让模型回答问题更准确、更贴近实际情境,同时减少错误的发生,就需要比起模型中通用知识和额外上下文(例如例子中的实时信息)之间的差距有更好的理解。
解决方案
传统上我们会通过微调模型来适配一些特定领域或专有信息,但这样做具有复杂、计算量大、费用高,需要专业技术知识等问题。因此在2020年,Lewis等人提出了一种更灵活的方法,叫做检索增强生成(Retrieval-Augmented Generation,RAG)。简单说,就是结合一个生成模型和一个检索器模块,让模型能够更轻松地从外部获取训练数据之外的额外信息。
简单来说,RAG对达模型的作用就像开卷考试一样。在开卷考试中,学生可以携带参考资料,比如课本或笔记,然后在答题时翻答案。开卷考试背后的思想是:考试侧重于学生的推理能力,而不是记忆特定信息的能力。
类似地,RAG将事实性知识与大模型的推理能力分开,将知识外挂到数据库中,这样外部知识可以更轻松地访问和更新。:
- 参数化知识:在训练期间学到的,隐式存储在神经网络的权重中。
- 非参数化知识:存储在外部的知识,比如一个向量数据库。
(作者注:顺便说一下,我并没有想出这个天才比喻。据我所知,这个比喻是在Kaggle的LLM科学考试竞赛期间由某位名叫JJ的人首次提出的。)
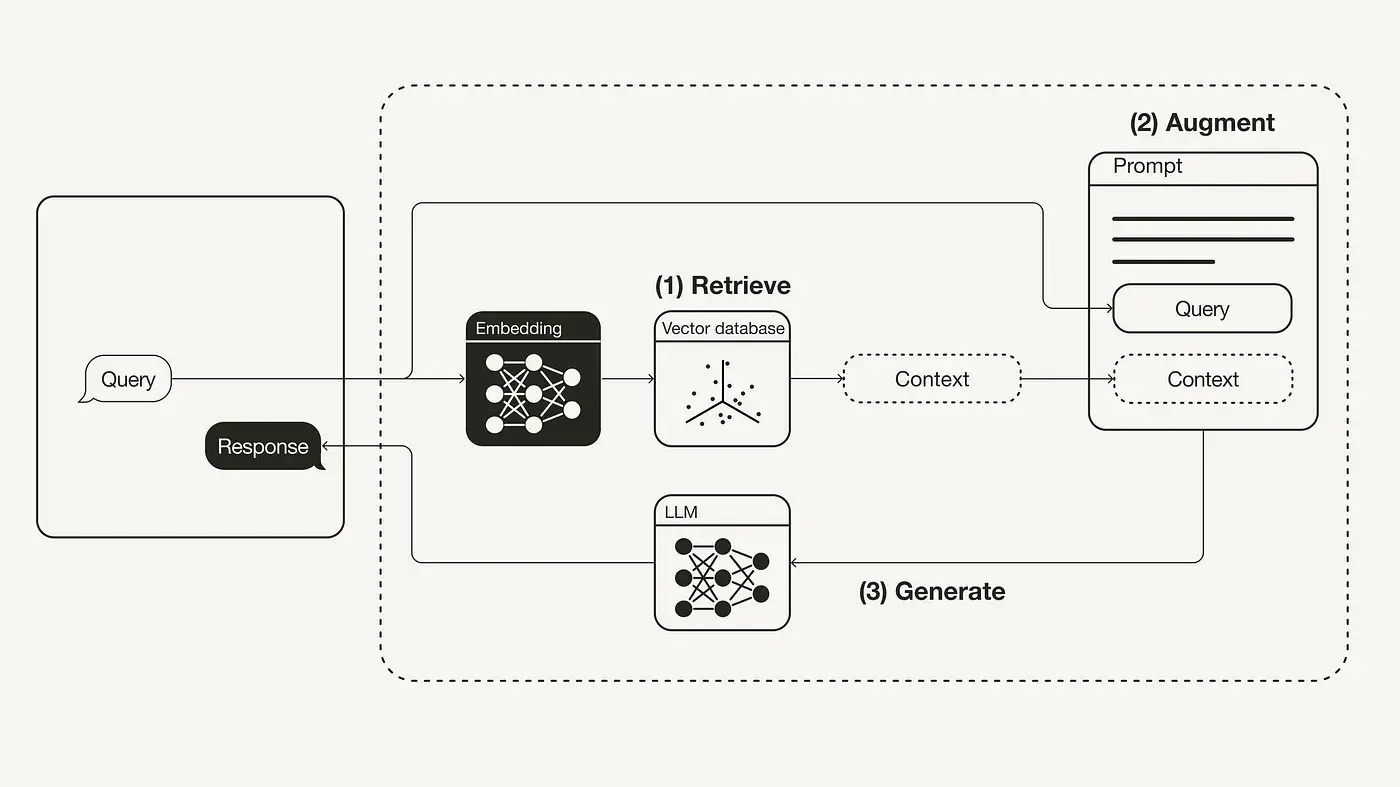
下图是RAG基本工作流程:
- 检索(Retrieve):用户的问题被用来从外部知识库中检索相关上下文。为此,用户查询会被嵌入到与「向量数据库中的上下文」相同的向量空间中,然后在这个空间做相似性搜索,返回数据库中与查询最相似的前k个数据对象。
- 增强(Augment):用户查询和检索到的内容被塞到一个提示模板中。
- 生成(Generate):最后,检索增强的提示被输入到LLM中。
二、用LangChain实现RAG
这节会使用Python实现一个RAG流程:结合OpenAI的LLM、Weaviate向量数据库和OpenAI嵌入模型。LangChain用于编排。
如果你对LangChain或Weaviate不熟悉,可以先看以下两篇文章:
- 《Getting Started with LangChain: A Beginner’s Guide to Building LLM-Powered Applications》
- 《Getting Started with Weaviate: A Beginner’s Guide to Search with Vector Databases》
环境准备
确保你已经安装了以下必要的Python包:
langchain用于编排openai用于嵌入和大模型调用weaviate-client用于向量数据库
#!pip install langchain openai weaviate-client
此外,需要在根目录下的.env中定义相关的环境变量OPENAI_API_KEY。获取OpenAI API密钥需要有一个OpenAI账户,然后在API密钥下选择“创建新的密钥”。
OPENAI_API_KEY="<YOUR_OPENAI_API_KEY>
然后,运行以下命令来加载相关的环境变量。
import dotenv
dotenv.load_dotenv()
数据准备
你需要准备一个向量数据库,作为一个存储所有额外信息的外部知识源。这个向量数据库的内容填充可以通过以下步骤完成:
- 收集并加载数据
- 文档分块
- 嵌入和存储
首先,收集并加载数据:我们将使用拜登在2022年发表的国情咨文作为额外的背景知识。原始文件在LangChain的GitHub上。同时,LangChain提供了很多内置文档加载器(DocumentLoader),文档(Document)是一个包含文本和元数据的字典。这里,我们用内置的TextLoader把文本加载到数据库中。
import requests
from langchain.document_loaders import TextLoader
url = "https://raw.githubusercontent.com/langchain-ai/langchain/master/docs/docs/modules/state_of_the_union.txt"
res = requests.get(url)
with open("state_of_the_union.txt", "w") as f:
f.write(res.text)
loader = TextLoader('./state_of_the_union.txt')
documents = loader.load()
接下来,文档分块:因为原始文档太长,没办法直接输入到大模型,所以需要先将文档切成小块。LangChain也提供了许多内置文本切分工具。此处我们使用CharacterTextSplitter,令 chunk_size约为500,chunk_overlap为50来保持块之间的文本连续性。
from langchain.text_splitter import CharacterTextSplitter
text_splitter = CharacterTextSplitter(chunk_size=500, chunk_overlap=50)
chunks = text_splitter.split_documents(documents)
最后,嵌入和存储: 为了实现对文本块的语义搜索,我们需要为每个块生成向量嵌入,然后把它们和它们的嵌入存在一起。此处使用OpenAI的嵌入模型生成向量嵌入,用Weaviate向量数据库进行存储。通过调用.from_documents(),向量数据库会自动填充这些块。
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Weaviate
import weaviate
from weaviate.embedded import EmbeddedOptions
client = weaviate.Client(
embedded_options = EmbeddedOptions()
)
vectorstore = Weaviate.from_documents(
client = client,
documents = chunks,
embedding = OpenAIEmbeddings(),
by_text = False
)
RAG-1: 检索
向量数据库准备好后,我们把它定义为检索器组件。组件的作用是根据用户查询和嵌入块之间的语义相似性来获取额外的上下文。
retriever = vectorstore.as_retriever()
RAG-2: 增强
为了把prompt与额外的上下文相结合,你需要准备一个prompt模板。prompt可以很容易地从prompt模板中定制,如下所示:
from langchain.prompts import ChatPromptTemplate
template = """你是一个用于问答任务的助手。
使用下面检索到的上下文片段来回答问题。
如果你不知道答案,只需说你不知道。
最多使用三个句子,并保持回答简洁。
问题:{question}
上下文:{context}
答案:
"""
prompt = ChatPromptTemplate.from_template(template)
print(prompt)
RAG-3: 检索
最后,用链将检索器、提示模板和LLM连接在一起,构建RAG流程。定义好了RAG链,就可以调用了。
from langchain.chat_models import ChatOpenAI
from langchain.schema.runnable import RunnablePassthrough
from langchain.schema.output_parser import StrOutputParser
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
rag_chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
query = "What did the president say about Justice Breyer"
rag_chain.invoke(query)
"The president thanked Justice Breyer for his service and acknowledged his dedication to serving the country.
The president also mentioned that he nominated Judge Ketanji Brown Jackson as a successor to continue Justice Breyer's legacy of excellence."
以下是这个例子的RAG流程图例:

总结
本文介绍了RAG的概念,RAG是在2020年的论文《Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks》[1]中提出的。在涵盖了概念背后的一些理论,包括动机和问题解决方案后,本文转向了在Python中的实现。文章使用了OpenAI LLM与Weaviate向量数据库以及OpenAI嵌入模型来实现一个RAG流程。编排方面使用了LangChain。
参考文献
[1] Lewis, P., et al. (2020). Retrieval-augmented generation for knowledge-intensive NLP tasks. Advances in Neural Information Processing Systems, 33, 9459–9474.
参考图片
除非另有说明,所有图片均由原作者创建。