逐帧分析|万字回顾谷歌这次“回怼”OpenAI都掏出来了啥好东西?
在人工智能领域,谷歌一直是OpenAI的主要竞争对手。被OpenAI朴实无华的商战截胡的谷歌,用了两个多小时,感觉把过去一年藏着没出的活都安排上了📅!
Project Astra 🆚 GPT-4o,
文生视频模型Veo 🆚 Sora
AI++ 谷歌搜索搜索 🆚 OpenAI跳票的搜索引擎
200万token上下文 Gemini 1.5 Pro 🆚 GPT4
多模态Gemini App 🆚 新版ChatGPT APP UI
除此之外,还有新的TPU,新的开源模型,新的 Gemma 27B 等等,不用担心,后面安排了一图读懂 & 详细解读版本。
看OpenAI发布会的时候,还觉得26分钟完全不够看的我,逐帧分析这场发布会就用了一天🥱。谷歌这次准备周全,还是非常有自信:
CEO劈柴一上场就点题道:「我们正处于Gemini时代」。

刚一上线就争议不断
下面评论收集于多个论坛,所以统一用“有人”开头
有人认为 Google 的新产品发布存在炒作疲劳,新模型表现不尽人意,存在等待名单等问题。
有人认为 Google 产品管理存在问题,提到 Google 的产品发布常常存在短暂炒作,产品最终可能会被关闭,对 Google 新产品持怀疑态度。
有人认为 Google 的产品发布方式混乱,命名不清晰,与 OpenAI 的产品比较,存在不足。
也有人反驳到 OpenAI 的产品发布也存在问题,尚未发布的功能引发疑问。
有人指出 Google 的产品发布方式类似于过去几年的 IO 大会,发布等待名单和演示,但产品最终可能无法达到预期。
有人对 Google 的产品发布方式和品质持怀疑态度,认为 Google 已经转向苹果式的营销策略,控制社交媒体上的话语权。
对我来说,能尽快用上这波新产品是最重要的!
今日可用
- Gemini 1.5 Flash,1M context window
- PaliGemma,开源视觉模型
即将可用
- Imagen 3,文生图模型
- Gemma 2,开源 LLM
- Gemini 1.5 Pro,2M context window
超快速版 & 一图看懂
谢谢歸藏老师提供的第一版
Google 的 I/O 发布会全线开花,几乎覆盖了目前所有的生成模型类型📌,产品层面上更融合AI🧪
📌 Gmini 1.5 Pro 支持 200 万上下文,跨关键用例的一系列质量改进,例如翻译、编码、推理等”,但没有发布测试结果。
📌 Gemini Flash 这款更小的 Gemini 模型针对较窄或高频任务进行了优化,其中模型响应时间的速度最为重要。百万 Token 的价格比 GPT-3.5 要便宜。
📌 Gemini 模型家族的构成:
- Ultra:“最大的模型”(仅在Gemini Advanced提供)
- Pro:“最佳总体性能模型”(在 API 预览版中提供)
- Flash:“轻量级速度/效率模型”(在 API 预览版中提供)
- Nano:“设备上模型”(将内置于Chrome 126中)
📌 Gemini Gems 谷歌的 GPTs,支持自定义与 Gemini 的互动方式。
📌 Gemini Live :“使用声音进行深入的双向对话的能力。”,Project Astra 实时视频理解个人助理聊天机器人,就是基于这个能力。
📌 Gemma 2:6 月发布规模为27B(之前为 7B 和 2B),以一半的尺寸提供接近 Llama-3-70B 的性能。
📌 PaliGemma:谷歌的第一个视觉语言开放模型,灵感来自PaLI-3 。
📌 Veo:DeepMind 对标 Sora 的模型,一小段提示词通过拓展可生成60秒长的1080p 高画质、连贯性视频。但HN 上有些体验过的人表示不太行,国际象棋的棋盘和棋子生成的都不对。
📌 Imagen 3:图像模型,能够理解人们自然书写的提示,生成更高质量的逼真图像,并且在渲染文本方面表现卓越。
📌 Music AI Sandbox: 由 Wyclef Jean、Justin Tranter、Marc Rebillet 等艺术家参与开发,可用于创作原创乐器音轨,并实现声音变换
📌 Trillium:最新的TPUs,在每颗芯片的计算性能上,相比上一代TPU v5e,实现了高达4.7倍的显著提升。
🧪 谷歌搜索的更新:
- AI Overviews:今天将开始向美国所有人推出,将能够通过选项调整 AI 概述,以简化语言或更详细地解释
- 引入多步骤推理能力:能将复杂的问题拆解成多个小部分,明确解决问题的顺序和方法。
- 很快就能在搜索中使用视频提问了。
- 提前计划:在搜索中直接具有规划功能,可以为需要的任何事物制定计划,从餐饮到度假。
- AI 组织的搜索结果:搜索将使用生成式人工智能与您进行头脑风暴,并创建一个由人工智能组织的结果页面。
🧪 Project Astra:语音助手 + 谷歌眼镜,真正的AI助手,随时随地的Copliot
🧪 Gemini App:手机版的 Gemini 应用,也将支持和 AI 视频对话。
🧪 Workspace(Gmail): 内置了Gemini Pro 1.5,可以帮助总结查找邮件内容和编写邮件回复。
🧪 谷歌文档:侧边栏的 Gemini Pro 1.5 集成,文档的改写总结等。
🧪 谷歌表格:使用 Gemini 和 Data Q&A 功能请求帮助,创建表格和数据分析等功能在今年晚些时候推出。
🧪 谷歌相册:Ask Photos可以帮助用自然语言搜索图片和视频,可以理解并回答复杂问题。
🧪 Circle to Search:现在成为了极佳的学习小帮手,可以在手机或平板上圈选复杂的物理问题,获得分步骤的指导帮助你学会解题。
接下来是详细版本,Gogogo!
新版本Gemini
随着劈柴宣布其上下文token数将达到2000K(200万),Gemini上下文超过了目前所有的大语言模型,而且开放给个人用户使用。相比之下,GPT-4 Turbo是128K,Claude 3是200K。

2000K tokens意味着,你可以一口气输入2小时的视频内容、22小时的音频文件、超过6万行的代码或者140多万个单词,模型将能够准确理解和处理这些信息。
而谷歌的下一步目标是—无限长上下文,我觉得可以开始期待了。
使用案例1 - 多模态交流
支持多模态的Gemini可以处理你上传的信息,理解内容后将其改造成适合你的形式,与你对话互动。仔细想想也不就是一对一小课吗?
作为父母,如果想快速了解孩子在学校的情况,就可以在Gmail中要求Gemini识别所有关于学校的电子邮件,然后帮你总结出要点。
如果你错过了公司会议,也可以拿到一小时时长的会议录音,Gemini就能立刻帮你总结出会议要点。
为帮助学生和教师,在NotebookLM中,谷歌设计了一个「音频概述」的功能。把左边的所有材料作为输入,Notebook就可以把它们整合成一个个性化的科学讨论了。

使用案例2 - Agent帮你退货/点外卖/自动“美团”
- 买了一双鞋子,不合适想退回怎么办?拍一张照片给Agent,它就可以从你的邮箱中搜出订单后,帮你填写退货单了。
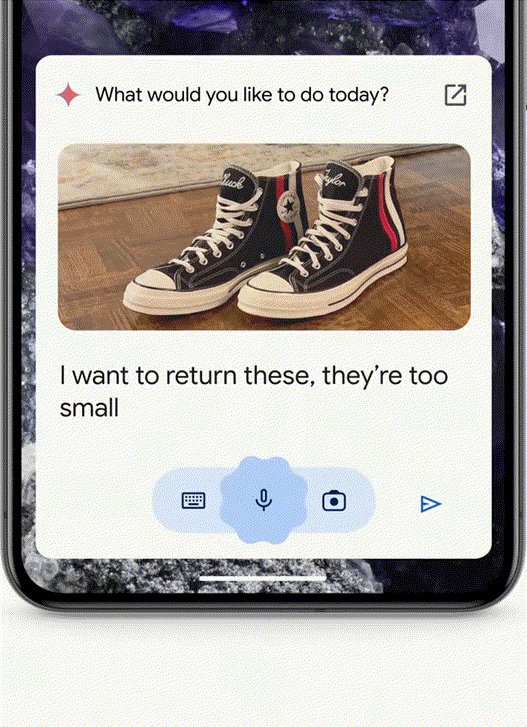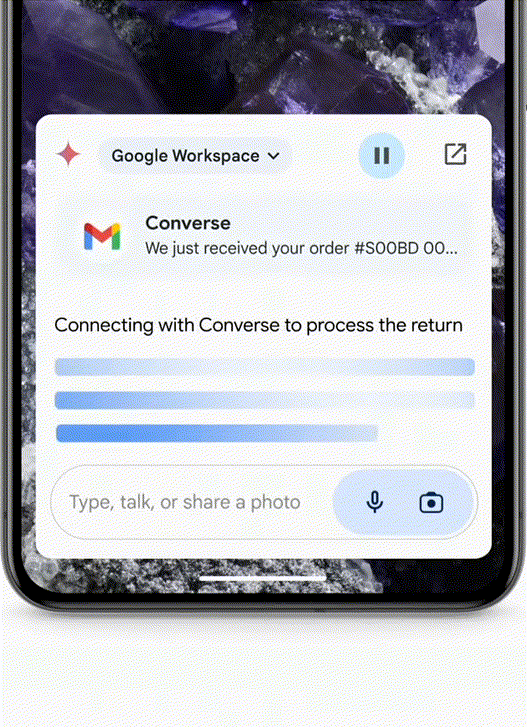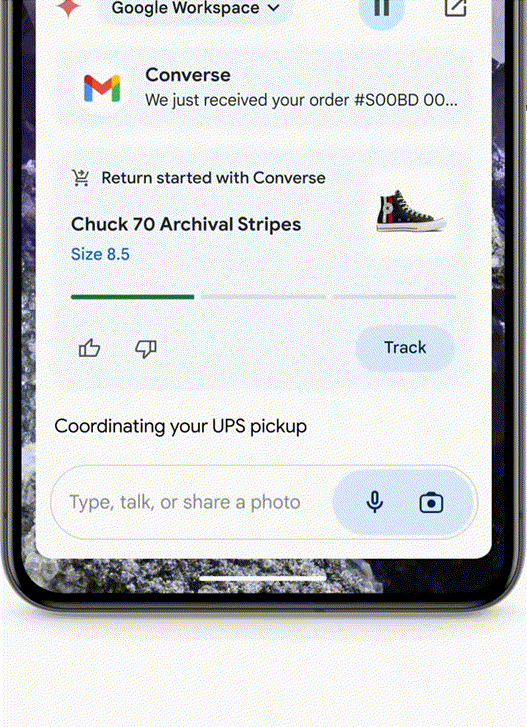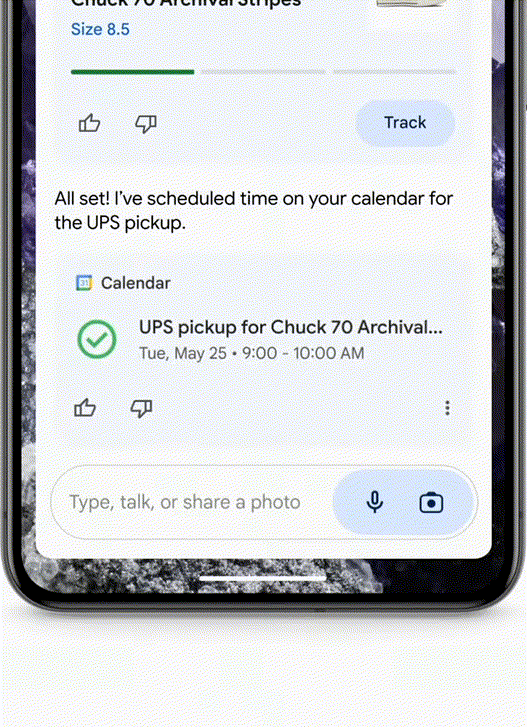
- 比如,你刚搬到某个城市,Agent能帮你探索你在这个城市所需的服务了,比如干洗店、帮忙遛狗的人等等,从Google Maps的角度上,我们不一定能用上🤔

简单来说,Gemini可以发挥自己的「多步推理」 Multi-Reasoning 能力包揽这些任务,把你需要的信息一次性提供给你!
AI++ 谷歌搜索
早在二月份,OpenAI就间接通过各种媒体声称要发AI搜索引擎,这不等于抢谷歌蛋糕了。
从昨天开始,在Gemini的加持下,谷歌搜索会彻底变样。在搜索框下,会出现一个为你量身定做的AI总结。事实上这个AI总结对于注册使用过Gemini的用户并不陌生,谷歌早在去年就开始使用人工智能来回复用户提问。
不仅如此,这次谷歌一连串给谷歌搜索加了4个强劲外设:
- 外设1: 这次多重推理能力同样植入到了新 Google 的搜索当中。它能将用户输入的一个复杂问题分解成多部分,确定需要解决哪些问题,以及用什么顺序解决,非常熟悉的Agent工作流拇指👍
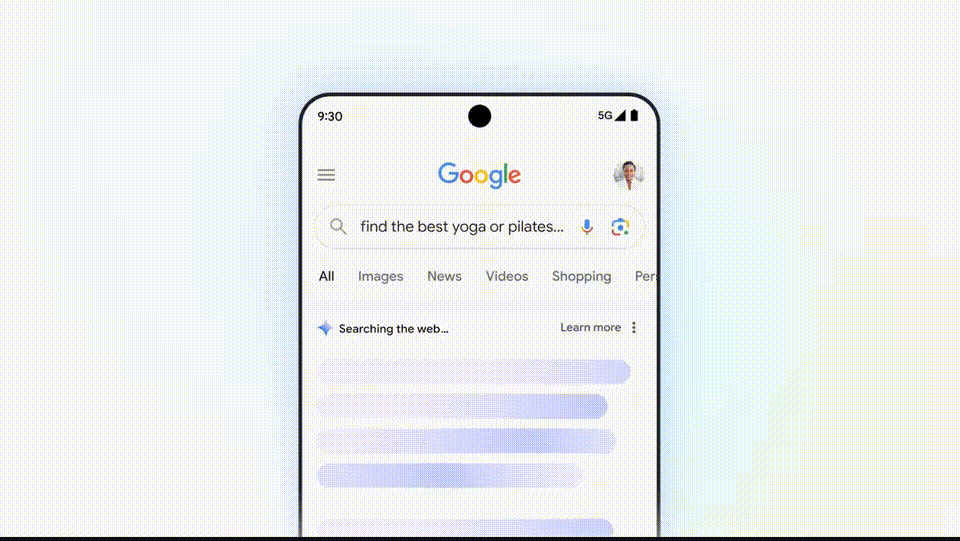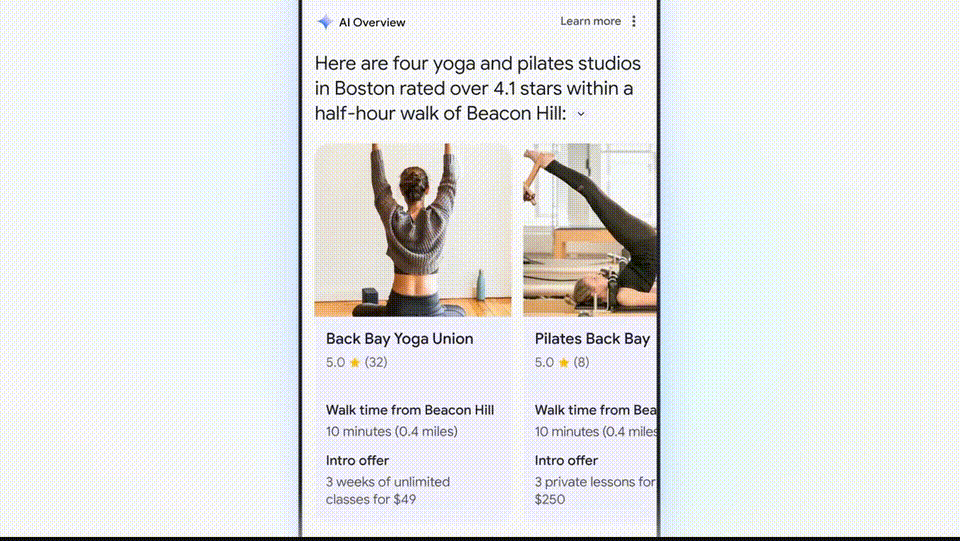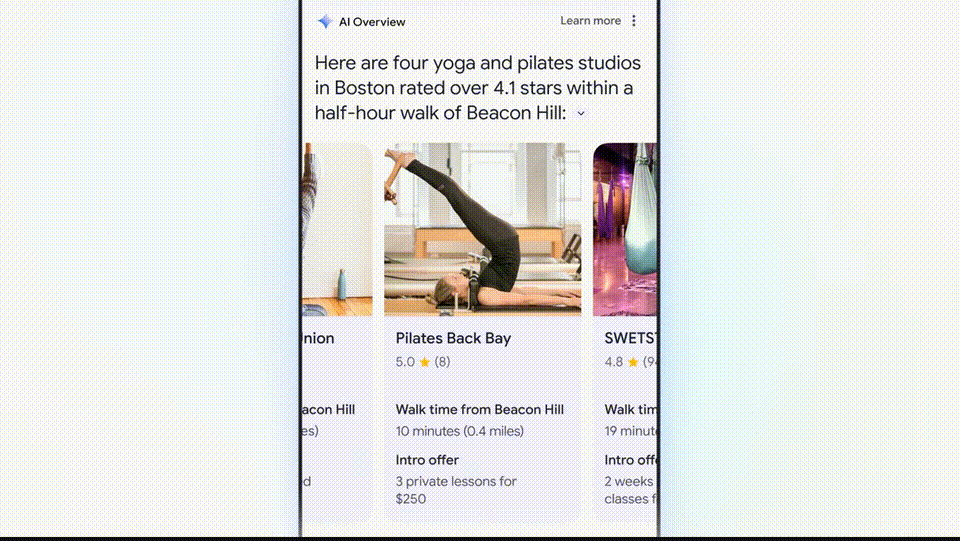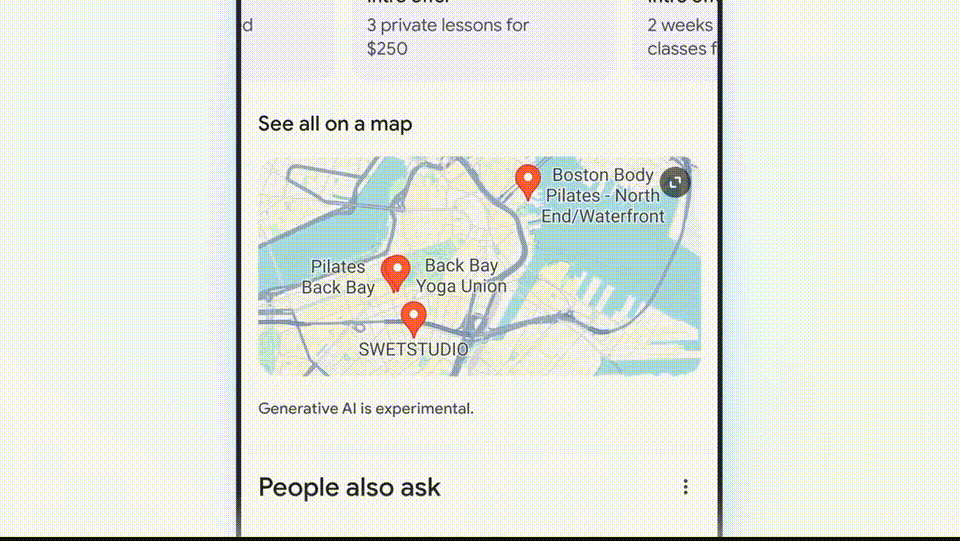
比如,如果想找到波士顿最好的瑜伽或普拉提工作室,它会直接搜出来结果,然后帮你整理好情况介绍和工作时间。
- 外设2: 除了提供答案外,Google Search AI 版 还会帮你做更为详细的规划。在下面这个例子中,你可以要求谷歌提供一个三天的膳食计划。这些食谱被从整个网络整合出来,清晰又全面,期待用它来做旅游计划
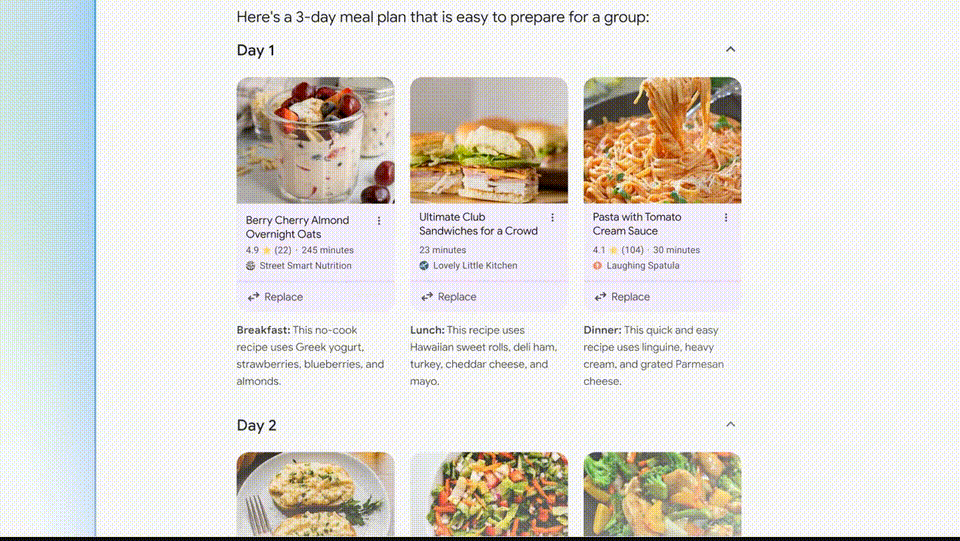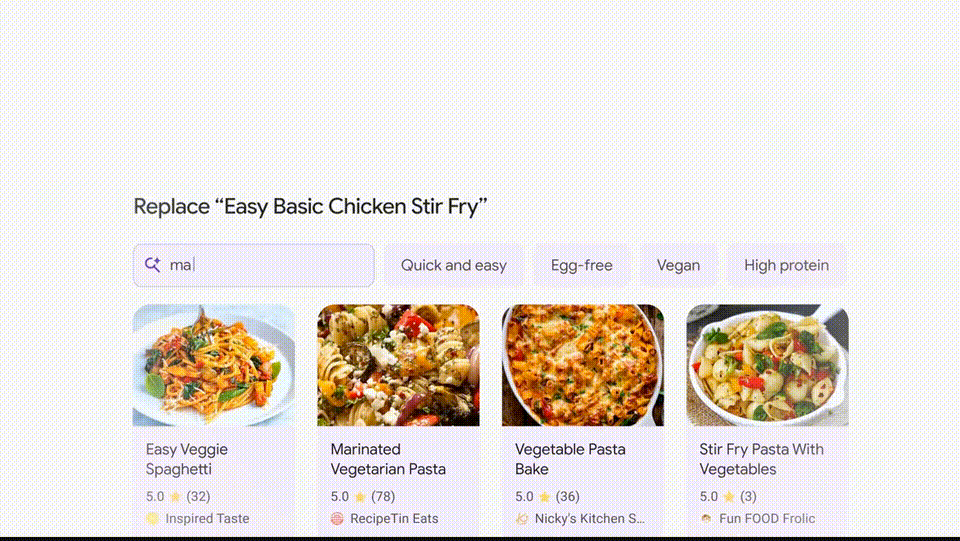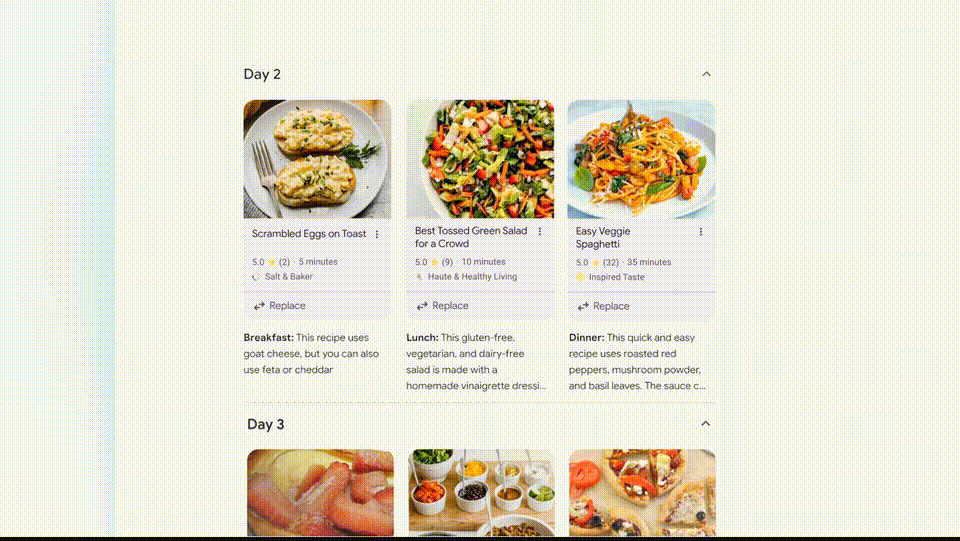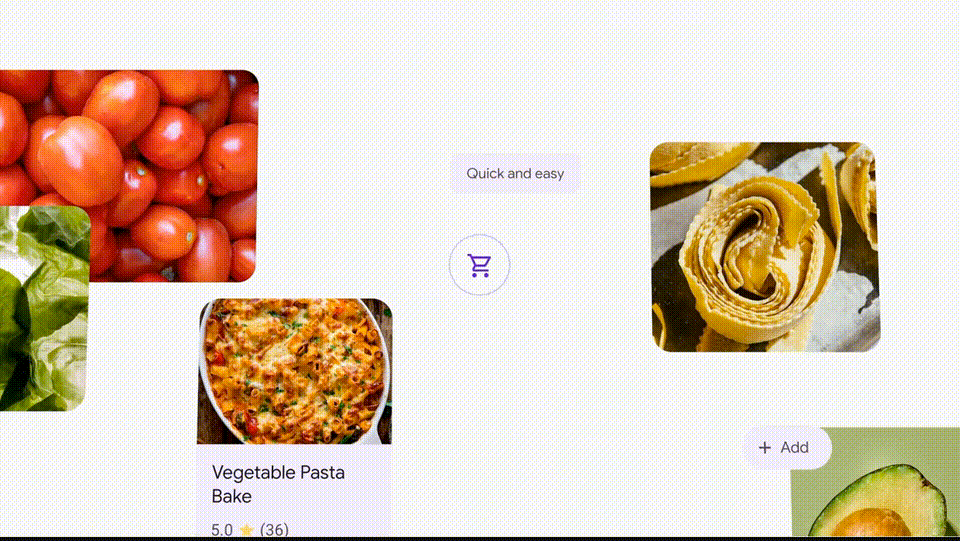
外设3: 多模态搜索
比如,没有说明书的话,要如何修理唱片机?
过去,我们可能要花费大量时间进行搜索,确定唱片机的品牌和型号,然后才能弄清楚问题所在。但现在,情况完全不同了。只需拍摄一个视频,上传到谷歌,并简单描述问题,就能得到详细的解答。

谷歌表示本周将向美国用户推出这个具有AI Overviews功能的新搜索引擎,并在未来几个月向更多国家的用户推出,在今年年底前将覆盖超过10亿用户。
对标GPT-4o,打造通用AI智能体 Project Astra
我们见识了新型号GPT-4o的出现,赋予了ChatGPT更强大的实时对话能力,大家都在说仿佛将《Her》中的情节带入了现实生活中。
对标OpenAI,谷歌DeepMind今天首次对外公布了「通用AI智能体」新项目—— Project Astra,后面简称Astra
根据谷歌的说法,它是一种通用的AI代理,可以在日常生活中帮助我们,一个真正的AI助手。

在现场的演示中,表现相当惊艳。不少朋友都觉得这是谷歌I/O大会中最喜欢的部分。
Astra展示了其出色的流畅回答能力,同时还首次展示了配备人工智能的「谷歌AR原型眼镜」。
Astra的演示分为两部分,都是一次拍摄、实时录制完成的。
案例1
测试者:当你看到会发出声音的东西时,告诉我
Astra:我看到一个扬声器,它可能会发声

测试者在APP内可以用红色剪头指定特定物品:这个扬声器的部件叫什么?
Astra:这是高音扬声器,能产生高频的声音。

Astra还可以读懂代码,GPT4o同款,直接用摄像头拍电脑屏幕,然后提问:这部分代码是做什么的?
Astra:此段代码定义了加密和解密函数。它似乎使用AES CBC加密,根据密钥和初始化向量对数据进行编码和解码

让人更加眼前一亮的,是它的记忆能力,我觉得也可以称之为视频的上下文窗口。
当你的眼镜找不到了?直接问Astra,你记得在哪里见过我的眼镜?
Astra能“回忆”场景,是的,我记得。你的眼镜就在桌子上,旁边有一个红苹果。

案例2 谷歌AR眼镜
谷歌的原型AR眼镜 + Astra 感觉要超过 🍎Vision Pro了【它们功能不一样,功能上不具备可比性,我仅仅是考虑如果是作为我的佩戴设备的个人感受】
测试者走到白板前,看向一个「服务器」的示意图,问到我应该怎样做能使这个系统更快?
Astra:在服务器和数据库之间,添加缓存可以提高速度。

再者,看到如下图,会让你想起什么?
薛定谔的猫! 我都差点没联想到

Astra直接在一个复杂的办公环境里演示🧑🏫,也是我觉得比GPT-4o演示好玩的一个点。
当谈到通用人工智能时,我们期望它能够像人类一样,对于复杂且不断变化的世界有所理解并做出相应的反应。
具体来说:Astra就是是谷歌团队在Gemini基础上开发的智能体,专注于持续编码视频帧。
它能够整合视频和语音多模态输入,并将它们缓存到事件时间轴中,以实现AI智能体的高效召回和信息处理。
此外,谷歌还通过广泛的语调变化增强了语音输出效果。通过这些努力,Astra能够更好地理解上下文,从而在交谈中更自然地做出快速反应,提升了互动的流畅度和质量。
文生图 Imagen 3
AI 文本到图像生成模型 Imagen 3 迎来升级!

具体来说
Imagene 3 比前一版本生成的图像更丰富细致,光影效果更出色,干扰伪影更少。
对提示的理解能力大幅提升,可以从更长的提示中捕捉到更多细节。
Imagen 3 生成的图像视觉效果出色,光照和构图都十分优秀。它能准确地渲染出细微的人手皱纹和复杂的纹理,还可以根据提示添加一些微小的细节,比如野花、蓝色的小鸟等。
Imagen 3 将提供多个版本,针对不同任务进行了优化,兼容生成快速草图到高分辨率图像。
显著改进了其文本渲染功能,实现文生文字图片
我们来直接看看实例吧!
提示Prompt:提示:使用偏振滤镜以数码单反相机的风格拍摄。两个热气球漂浮在土耳其卡帕多西亚独特岩层上的照片。这些气球上的颜色和图案与下面风景的大地色调形成鲜明对比。这张照片捕捉到了享受这种体验所带来的冒险感。

大象amigurumi在大草原上行走,专业照片,模糊背景

由各种五颜六色的羽毛制成的“光”字,黑色背景

更多案例:https://deepmind.google/technologies/imagen-3/
文生视频Veo 🆚 Sora - 1080p超过60秒
谷歌最新发布的视频生成模型Veo应该就是准备已久的对OpenAI Sora的挑战!
Veo的推出建立在DeepMind过去一年各种开创性成果的基础上,包括GQN、Phenaki、Walt、VideoPoet、Lumiere等等。谷歌结合了这些成果中最好的架构和技术,提高了一致性、质量和分辨率。
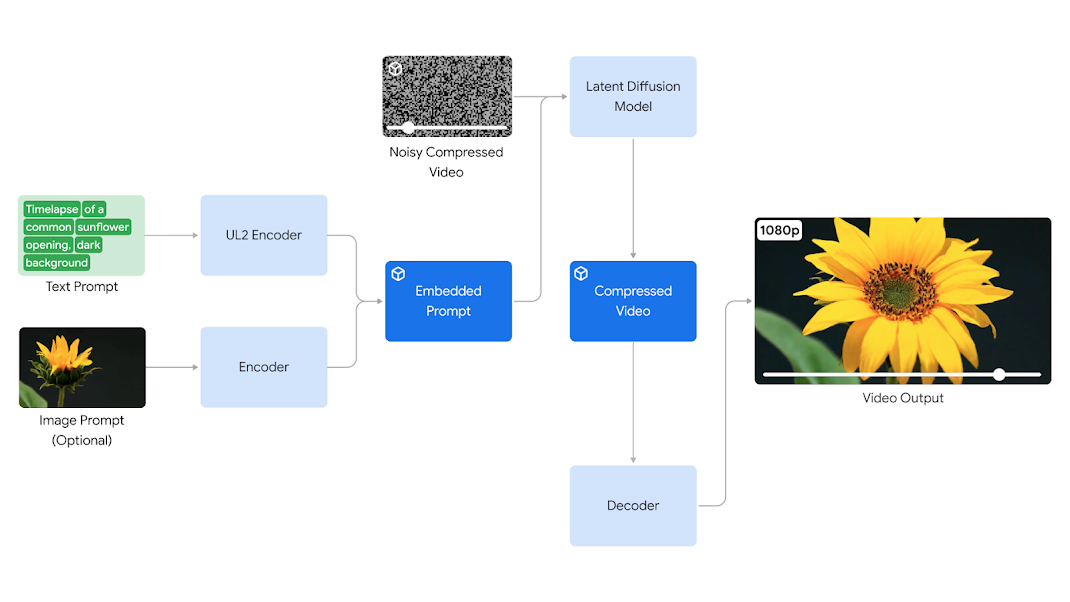
最终结果是Veo具备1080p的高质量,用户提示可以是文本、图像、视频等各种格式,还能捕捉到其中关于视觉效果和影像风格的各种细节描述。
用谷歌自己的话来说
它准确地捕捉了提示的细微差别和语气,并提供了前所未有的创意控制水平——理解各种电影效果的提示,如延时摄影或风景的航拍。

Veo同样支持视频修改,比如在航拍镜头中添加皮划艇到海岸线的场景。Veo能够接收输入视频和编辑指令,然后应用这些命令,生成全新的编辑视频。

除此之外,Veo在确保视频帧之间的一致性方面也做得很好。在当今AI视频生成中,一个常见的挑战是在视频帧之间角色、物体甚至整个场景可能会出现意外的闪烁、跳跃或变形,从而影响观看体验。但是,Veo似乎能够很好地解决这些问题。
动图3
好消息是,Veo已经开始在官网开放试用了。此外,团队还开发了实验性工具VideoFX搭载Veo模型。申请入口:https://aitestkitchen.withgoogle.com/tools/video-fx
更多案例:https://deepmind.google/technologies/veo/
文生音乐 Music AI Sandbox
在AI音乐领域,谷歌与YouTube联手打造了Music AI Sandbox。这不就是对标Suno,Udio吗?
Music AI Sandbox能够接收用户输入的旋律,并通过风格迁移功能,帮助艺术家们快速实现他们的创意。
一些知名音乐人如Wyclef Jean、Justin Tranter 和 Marc Rebillet 是第一个使用音乐 AI 沙盒发布新演示的人,每个演示现在都可以在他们的 YouTube 频道上收听。
可惜的是这次没有给出很多关于Music AI Sandbox的信息,我们蹲一波后续
Gemini App
谷歌推出了Gemini原生多模态应用,能够同时处理文本、音频和视频内容。这款应用是谷歌长期以来努力打造的个人AI助手的一部分。
为了让用户与Gemini交互更自然,谷歌还发布了Gemini Live。
在 Gemini app 中,你可以和 AI 进行视频对话,延迟大概是 1-2秒,比 GPT-4o 长(4o 大概是 0.3秒),同时语音语调明显比 4o 要弱。
比如,你正在为一场面试做准备,只需要进入Live,让Gemini陪你一起做准备。
Gemini可以与你进行模拟面试排练,甚至在与潜在雇主交谈时应该突出哪些技能,还能提供建议。你甚至可以控制自己的说话节奏,或者随时打断Gemini回答,如同与真人交流一样。
谷歌表示今年会推出摄像头模式,用户可以通过周围环境与Gemini实现对话。
谷歌版GPTs
与此同时,谷歌还推出了根据个人需求自定义的Gemini专家——Gems,所以是谷歌版GPTs~
你可以让 Gemini 成为健身教练、厨房助手、编程伙伴、创意写作指导或您能想到的任何角色。Gems 功能与 OpenAI 的 GPT Store 类似,所以是谷歌版GPTs~

谷歌也展示了如何通过构建自定义AI助手。你可以通过告诉 Gemini 要做什么以及如何回应来设置一个 gem。例如,您可以告诉它成为您的跑步教练,为您提供每日跑步计划,并保持乐观和激励人心的语气。然后,Gemini 将根据您的描述为您创建一个 gem。

Ask Photos新功能
在Gemini的加持下,谷歌还会推出Ask Photos的新功能。这项功能的便利之处在于,当你需要查找特定照片时,无需在手机里翻找大量图片。
举例来说,假如你在缴纳停车费时忘记了车牌号,你可以直接向Ask Photos询问,它会展示你的车牌照片,省去了繁琐的查找过程。

你还可以询问关于照片中人物或场景的信息。例如,你可以问你的女儿是什么时候开始学游泳的,以及她的游泳技术是如何进步的。Gemini会识别照片中的不同场景,并将所有相关信息汇总展示。

但我关心的是,这个功能只能在谷歌相册中使用吗?
Gemini 1.5 Flash
没错,谷歌还发布了新的轻量模型!Gemini 1.5 Flash
起因是某些Gemini 1.5 Pro用户的反馈,一些程序需要更低的延迟和服务成本。
麻雀虽小,五脏俱全。Gemini 1.5 Flash同样具有多模态、1M tokens长上下文,每百万个token的价格仅是Pro版的二十分之一,价格折人民币只需要0.002 元/千tokens
今天起,Gemini 1.5 Flash在Google AI Studio和Vertex AI中就可用了,开发者可以注册申请两百万token的内测版。此外,为了方便开发者,谷歌还对Gemini的API功能进行了三项优化——视频帧提取、并行函数调用和上下文缓存。
Gemini 1.5 Flash
详细价格信息如下:
标准价
- 输入:$0.7 / 1M tokens
- 输出:$1.05 / 1M tokens
折扣价(上下文小于 128k 时)
- 输入:$0.35 / 1M tokens
- 输出:$0.53 / 1M tokens
对比一下,GPT-3.5 Turbo (16k 上下文)的价格是
- 输入:$0.5 / 1M tokens
- 输出:$0.15 / 1M tokens
从跑分结果上看,Gemini 1.5 Flash跟Gemini 1.5 Pro差距相当少
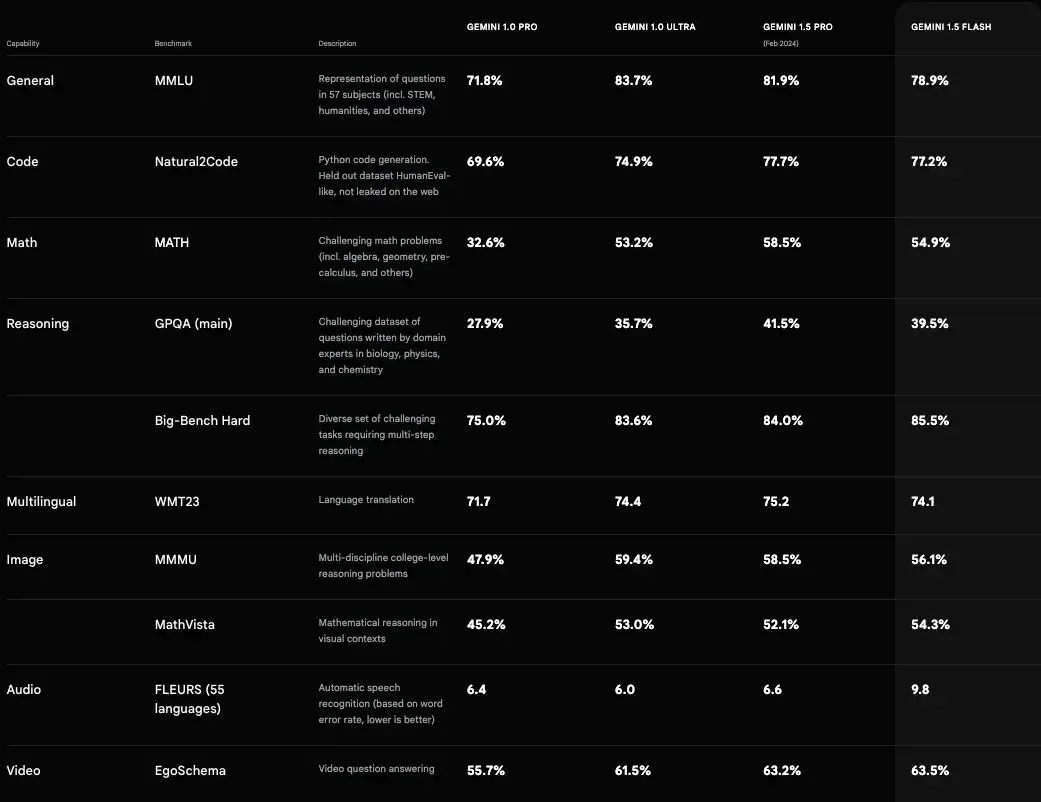
「彩蛋」谷歌还宣布其Chrome 126浏览器将引入Gemini Nano模型,该模型能够在本地执行文本生成等功能,如生成产品评论、社交媒体帖子和其他简介,并针对Chrome浏览器进行了优化,显著提高了加载速度。
第六代 TPU Trillium
最新一代的Trillium TPU相较于之前的TPU v5e,性能提升高达4.7倍,同时能效提升超过67%

这一飞跃得益于谷歌对矩阵乘法单元(MXUs)规模的增大和时钟速度的提升。此外,Trillium还配备了第三代SparseCore,这是一种专为处理高级排序和推荐工作负载中常见的大型嵌入而设计的加速器。
SparseCores可以通过从TensorCores策略性地卸载随机和细粒度访问,从而有效加速了重嵌入型工作负载。谷歌还将高带宽存储器(HBM)的容量和带宽翻倍,并将芯片间互连(ICI)的带宽提升了一倍,这使得Trillium能够支持更复杂的模型,并大幅缩短大型模型的训练时间和响应延迟。
在一个高带宽、低延迟的Pod中,Trillium可以扩展至256个TPU。而通过多切片技术和Titanium智能处理单元(IPU),Trillium还可以进一步扩展——连接数以万计的芯片,并在一个多千兆位每秒的数据中心网络支持下,组成一个超大规模的超级计算机。
视觉-语言开源模型 PaliGemma
谷歌也没忘了开源社区,发布了Google 首个视觉-语言开源模型——PaliGemma,专门针对图像标注、视觉问答及其他图像标签化任务进行了优化可在 GitHub、Hugging Face 模型、Kaggle、Vertex AI Model Garden 和 ai.nvidia.com(使用 TensoRT-LLM 加速)上找到,现在就能用。

此外,谷歌计划在6月推出规模更大的开源模型 - Gemma 2 27B。在性能方面,全新的Gemma 27B超越了规模大了2倍多的Llama 3 70B,还能在GPU或单个TPU主机上高效运行。

写在最后
从头到尾梳理了这次发布会后,虽然关注度没有OpenAI多,但我人觉得 Google I/O 还是有不少亮点,这也促使我写下了这篇长文。
总体来说,我感觉 Google 正在迎头赶上 OpenAI,甚至在某些方面已经超越了它。无论是 2M 超长上下文、文生视频 Veo、AI + 谷歌引擎,还是语音助手 Astra 以及谷歌眼镜的合成等等,都已经有所显示。
但 Google 当下最大的风险还是在如何应对 LLM 在搜索结果中带来的商业化挑战,这点也是从去年到现在的老问题了。到底如何让自己模型不割了搜索引擎的大动脉?毕竟搜索的第一条结果换成了 LLM 的结果,不少人觉得这对SEO(搜索引擎优化)& 网站商业化 的影响是巨大的。
最后,我仍希望 Google 越来越好,
毕竟人工智能通往AGI的路上,
百花齐放远比一枝独秀更加精彩!
