🟢 叮!马斯克向你扔来了 314B 超大杯开源模型段子手--Grok1🕶️
好消息!马斯克的 xAI 的 Grok 开源了。坏消息,314B 超大杯,怎么喝?
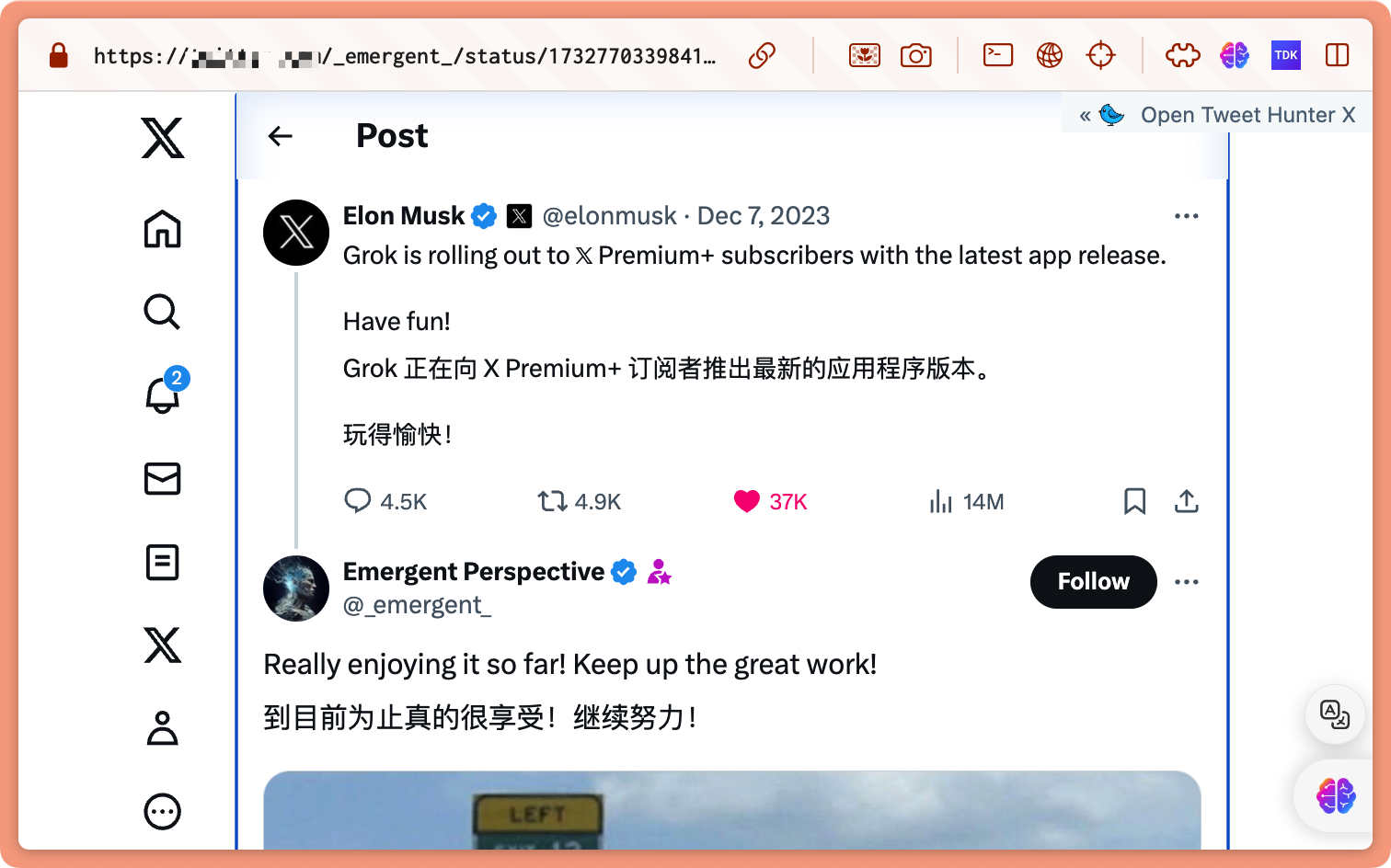
Grok 自从诞生就套上了幽默版"马斯克"标签,23 年的 12 月 7 日也正式推送了 X 的订阅用户,Grok 备受瞩目的主要原因有两个:
- 幽默感和互动性:不回避敏感话题、敢于表达真实想法
- 实时性和信息获取能力:能够通过 X 平台实时了解世界
OpenAI and Elon Musk

就是 3 月 1 号,马斯克正式起诉 OpenAI 及其 CEO 奥特曼。马斯克在诉讼中指控 OpenAI 违反了其创立时达成的协议,即开发技术以造福人类而不是追求利润,并要求 OpenAI 恢复开源状态
随后,OpenAI 在 2024 年 3 月 6 日通过一篇长文《OpenAI and Elon Musk》正式回应了马斯克的指控。在这篇回应中,OpenAI 公开了过去八年的邮件往来截图,以此来驳斥马斯克的所有指控
所以在 3 月 11 号,马斯克直接开大招,预告会开源 Grok,一周过去了,正当我都以为要跳票了,没想到在最后一个时刻,马斯克如约开源了 Grok🎉!
Grok-1 开源意味这什么?
开源 Grok-1 是一件大事,因为这代表了马斯克已经正式选边站了,而且是开源 AI!这是一个开创性的时刻,也是迈向开源 AGI,拥抱开源的重要一步!
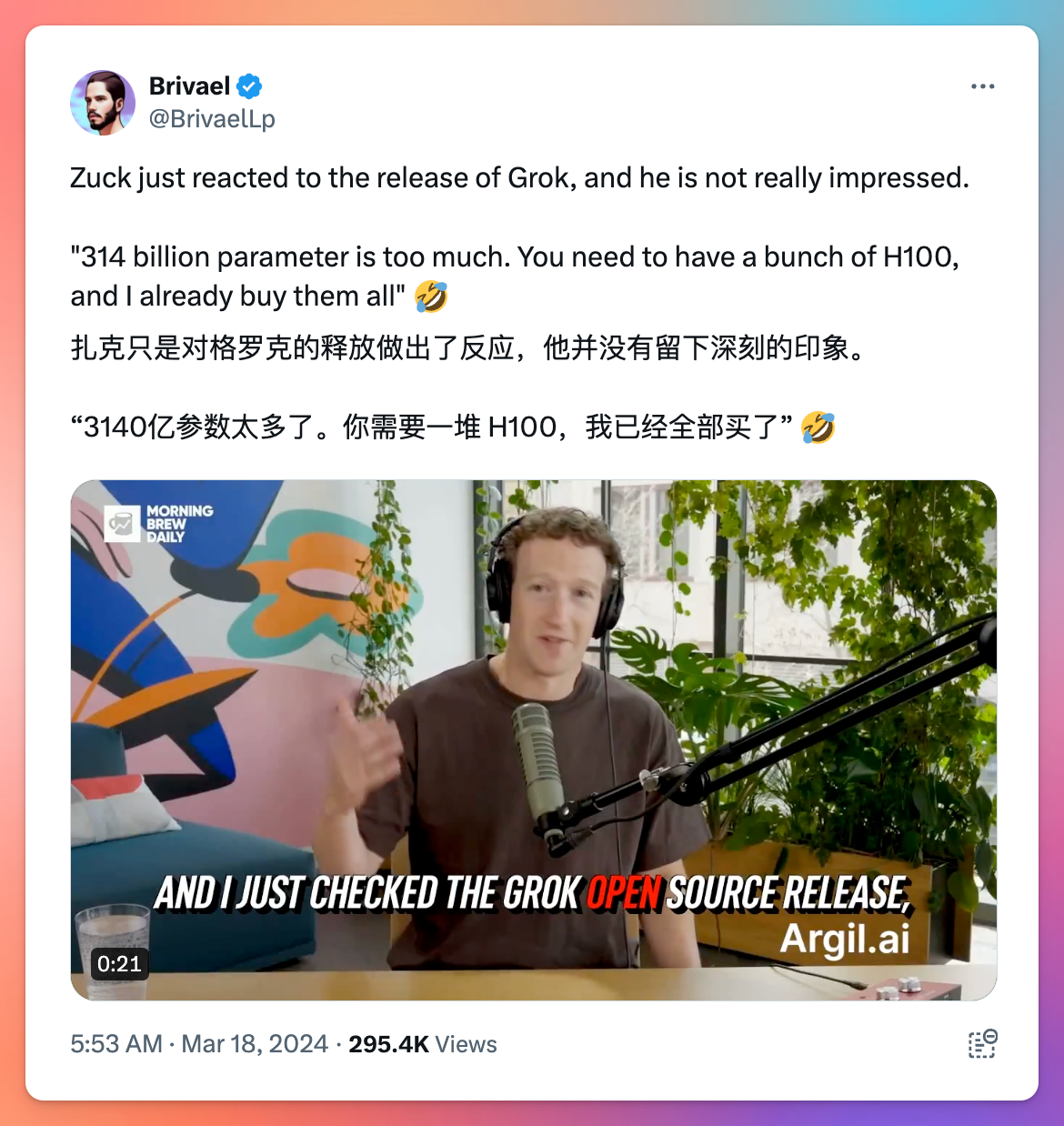
扎克伯格也对 Grok 做出了回应:
“3140 亿参数太多了。你需要一堆 H100,我已经全部买了”😂
Perplexity 的 CEO 也表示:
“我们将对它进行微调以进行对话搜索并优化推理,并将其提供给所有 Pro 用户!”
看来不仅仅是 Claude3,Grok 也将动摇到 GPT 的“霸主地位”🫅
快速了解 Grok 全貌
这次开源的 Grok-1,是 2023 年 10 月结束的 Grok-1 预训练阶段的原始基础模型检查点。基础模型基于大量文本数据进行训练,未针对任何特定任务进行微调。。这意味着该模型不会针对任何特定应用(例如对话)进行微调
- 基础信息:模型规模为 314B,由 8 个专家系统组成(其中 2 个处于活跃状态)。 活跃参数总数达到 86B。该模型采用旋转嵌入(Rotary Embeddings)技术,而非传统的固定位置嵌入方式。
- 高效运行:Grok 是一个拥有 3140 亿参数的混合专家模型,其中在处理每个数据单元(Token)时,大约有 25% 的模型参数是活跃的,这意味着模型可以更高效地运行
- 训练架构:这个模型是 xAI 团队使用定制的训练架构,在 JAX 和 Rust 的基础上从头开始搭建并训练出的成果
- 开源证书:Apache 2.0 这一开源许可证下发布这个模型的权重和架构,任何人都可以在该许可证的规则下使用这些资源。
- 314B 超大杯 🍺:为了运行整个模型,你可能需要 5 台 H100 GPU
模型架构介绍
这部分需要一定前置知识,计划使用 Grok-1 微调的大家可以通过下面关键信息来快速定位到自己所需的部分
- 分词器的词汇量为 131,072(与 GPT-4 相似),即 2 的 17 次方。 嵌入向量的大小为 6,144(48*128)。
- 模型包含 64 层的 Transformer 结构(这是相当高的层数)。 每层包含一个解码层,由多头注意力模块(Multihead Attention Block)和密集前馈块(Denseblock)构成。 键值对(Key-Value)的大小为 128。
- 在多头注意力模块中: 用于查询的头数为 48, 而用于键/值(Key/Value, KV)的头数为 8, 其中 KV 的大小为 128。
- 密集前馈块(Dense Block)的特点包括: 扩展因子为 8, 隐藏层的大小为 32,768。
- 每个 Token 会从 8 个专家中选出 2 个进行处理。
- 旋转位置嵌入(Rotary Positional Embeddings)的大小为 6,144,这与模型的输入嵌入尺寸相匹配。
- 模型可以处理的上下文长度为 8,192 个 Token。 计算精度为 bf16。
代码:https://github.com/xai-org/grok-1
写在最后
Grok-1 的开源将掀起一股新的浪潮,开源社区即将迎来一波又一波更新。可以预见,量化、蒸馏、微调、汉化等各种形式的 Grok 将陆续亮相。
让我们一起迎接
这个从出生就自带幽默因子的
🕶️ 小子 -- Grok!
