4 steps for AI-generated influencer creation - Flux with Kling AI
🟢 我用Flux开了场TED“真人”演讲,AI生图开启新赛季“谁是真人”
这周末我被各种“真人”演讲刷屏了,
刚开始看到100% AI生成的标签时,我以为HeyGen更新了,结果却看到了一个新的组合词“FLUX Dev+Runway Gen3”。
好嘛,一觉醒来,数字人的饭碗被AI生图和AI视频抢了,
如果说,AI应用们在卷各种功能来破圈,
那么,AI数字人绝对是个异类,因为破圈的原因只有一个 - 那就是更像人了
有多少像?画质被压缩了一倍不止

Runway是老朋友了,人物的动作并没有到达让我惊讶的程度,所以这次真人演讲的技术供应商是新朋友Flux
Flux发布的第一周,
给我留下的印象是一个比SD强上不少的 AI 生图模型。
但仅过去一周,装载了真实版LoRA后,TED用Flux掀起了一场“真人演讲”比赛。

如果说之前我做数字人测试会在不同光线、不同镜头角度下测试稳定性,
那这次比赛就像一个命题作文,
如何做出让人无法分辨的演讲视频。
今天我就带大家来挑战一下💪
整个工作流分为四步,涉及到的工具们都有替代品,
大家可以发挥自己的想象力做出更多演讲。
生图->生成视频—>视频对口型->视频加速和高清化(可选)
第一步,生成以假乱真的图片
第一步,生成以假乱真的图片
为了复刻原版视频,我使用的是
FLUX Dev + XLabs AI Realism

上面我有提到FLUX,一个新的AI生图模型,
而这后半截 XLabs AI Realism 就是习惯用Stable Diffusion的友友们心心念念的“作弊码” - LoRA。
简单来说,通过这个模块,你生成的图片会更加写实,不需要反复尝试不同的提示语。
使用方式有手就行,
访问NoteBook(地址在评论区),左侧看到黑色的播放键,
点击运行后,等待下方输出以gradio结尾的网址就可以点开使用
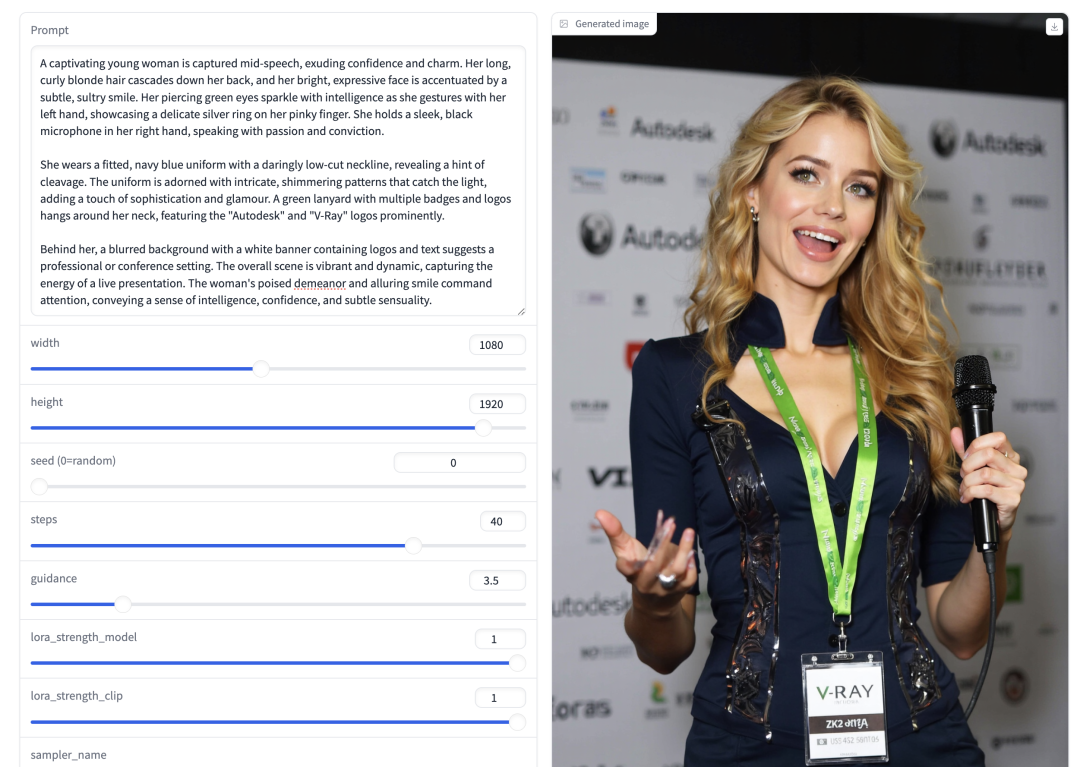
提示词很长,我直接放在这次文末彩蛋了
第二步,生成演讲视频
这一步重要是让人物动起来,让背景不像PPT。
哪怕嘴不动也没关系,因为在第一步的时候,让人物张嘴而不是闭口就能保证后续对口型成功。

提示语非常简单,“一个女人正在台上演讲”
Step 3: Make the Character Speak
让人物开口说话
这里使用的是sync labs,
不过在不充会员的情况下,
sync会给你一个画面中央放上一个大大的水印
Portal: https://synclabs.so/
操作同样简单,上传图片,选择适合人物的音色即可
第四步,加速或高清化视频
这一步能让成品更加真实,特别是
- AI视频工具生成的人物动作会较慢
- 以及唇形同步工具会影响原视频的清晰度
如此类推,你也能收获一大堆真人演讲。
所以AI能100%取代真人了吗?
使用下来还是存在局限性:
- 10秒的视频需要5分钟才能生成
- 短视频平台上的热门视频平均时长是 1 分钟,因此生成需要 30 分钟
- 数据充足的前提下,AI声音几乎可以以假乱真
- 口型同步的质量目前还没跟上其他环节
In Conclusion
人类好像一直期待着复刻出“自己”,
我时不时会想有一个克隆体,
帮我工作,
也会怀疑我会不会是一个数字人,
一切的经历都是虚构的,
所以当我能构建一个真人来演讲的时候,
我是兴奋的,
TA是如此的真实,
似乎真的在跟我说话
那TA第一句话会是什么呢,
Hello World吗?
